10 Pipeline Design Patterns for Data Engineers
How to leverage Design Patterns for scalable and efficient data pipelines

Data pipelines are the backbone of moving and processing information from multiple sources so businesses can make better decisions. Using software engineering principles and design patterns, data engineers build pipelines that are efficient, reusable, and easy to manage, allowing data from apps, databases, and third-party tools to flow into a central system for analysis and insights.
In this post, we cover:
What is a data pipeline
10 key design patterns, their principles, and practical applications for building effective data pipelines.

The patterns above simplify the integration of diverse data sources and enable efficient large-scale data processing, ensuring pipelines align with business goals.
What Are Data Pipelines?
A data pipeline is a system that moves, processes, and transforms data throughout its lifecycle. It begins where data is generated (e.g., databases, APIs, streaming platforms, or flat files) and concludes with data stored in warehouses, processed in machine learning models, or analysed for insights.
Acting as the architects of data flow, pipelines channel, refine, and direct information from raw data to actionable insights. They enable organisations to bridge the gap between data collection and decision-making, supporting efficient, data-driven strategies.
If you’d like to learn more about data pipelines, these videos by Zach Wilson are a great place to start:
Key Design Patterns in Data Pipeline Architecture
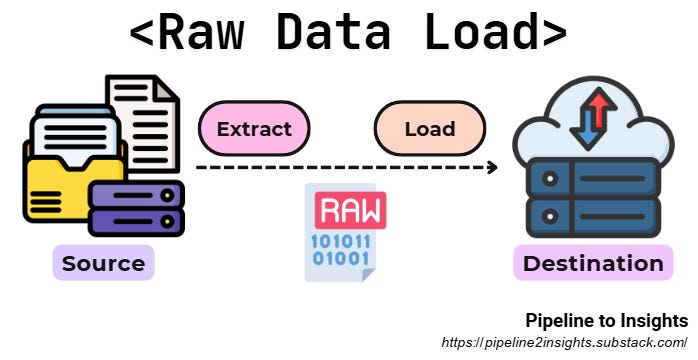
1. Raw Data Load:
Purpose: Transfers unprocessed data between systems, often for bulk migrations or initial loading of databases.
Method: Moves raw data directly from the source to the target system.
Benefits:
Simplifies one-time operations like database migrations.
Handles large data volumes efficiently.
Limitations: Unsuitable for ongoing operations or use cases requiring cleaned or structured data.
2. ETL (Extract, Transform, Load):
Purpose: Processes structured and semi-structured data with complex transformation requirements for analytics or integration.
Method: Extracts data from sources, transforms it (e.g., cleansing, standardisation), and loads it into the target system.
Benefits:
Ensures data quality and consistency for downstream applications.
Handles integration from multiple sources effectively.
Limitations: Batch-oriented, resulting in built-in latency and delayed availability of data.

3. ELT (Extract, Load, Transform):
Purpose: Accelerates data availability by loading raw data into the target system before applying transformations.
Method: Extracts data, loads it into a storage like datalake to datalakehouse, and performs transformations in place.
Benefits:
Reduces initial latency by enabling immediate access to raw data.
Leverages the computational power of modern data warehouses.
Limitations: Exposes unprocessed data to users, which may result in data quality or privacy concerns.

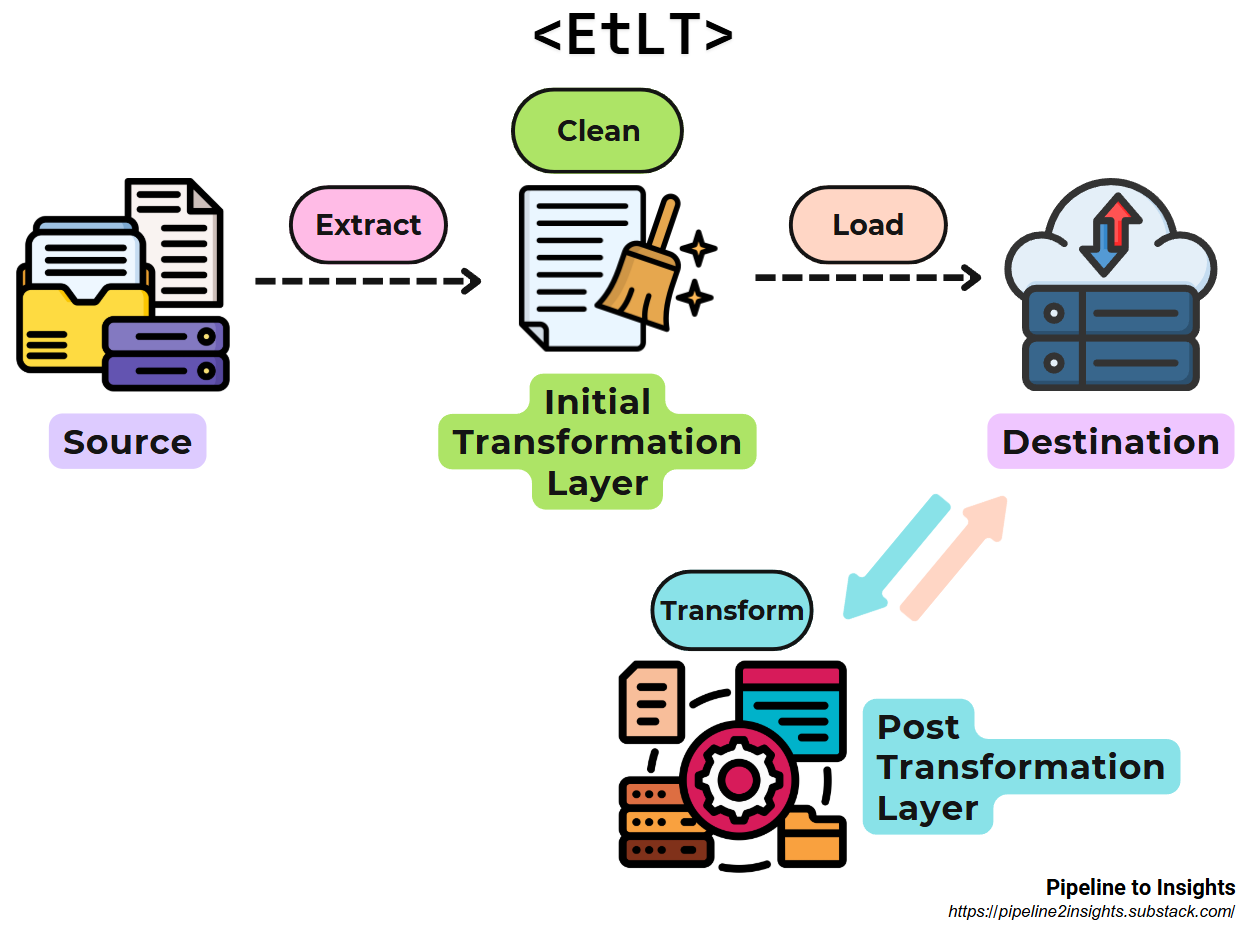
4. EtLT (Extract, Transform, Load, Transform):
Purpose: Combines fast availability with initial data cleaning and post-load transformations.
Method: Performs lightweight transformations during extraction (e.g., cleansing, masking), loads the data, and completes advanced transformations in the target system.
Benefits:
Balances rapid data availability with data integrity and privacy.
Handles multi-source integration after initial transformation.
Limitations: Requires managing both pre-load and post-load transformation stages.
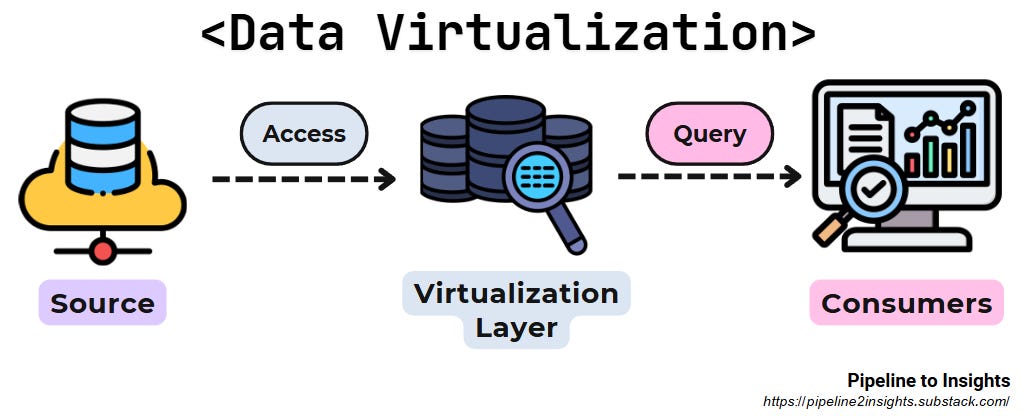
5. Data Virtualisation:
Purpose: Provides on-demand data access by creating virtual views without physical duplication.
Method: Integrates and transforms data dynamically through query-driven processes, leveraging abstraction layers.
Benefits:
Avoids data replication, reducing storage costs.
Offers up-to-date data without requiring scheduled processes.
Limitations:
Performance depends on the structure and indexing of the underlying data sources, which can impact query efficiency.
Limited functionality compared to ETL or ELT, making it less suitable for complex transformations or advanced analytics.
Its read-only nature restricts data manipulation capabilities.
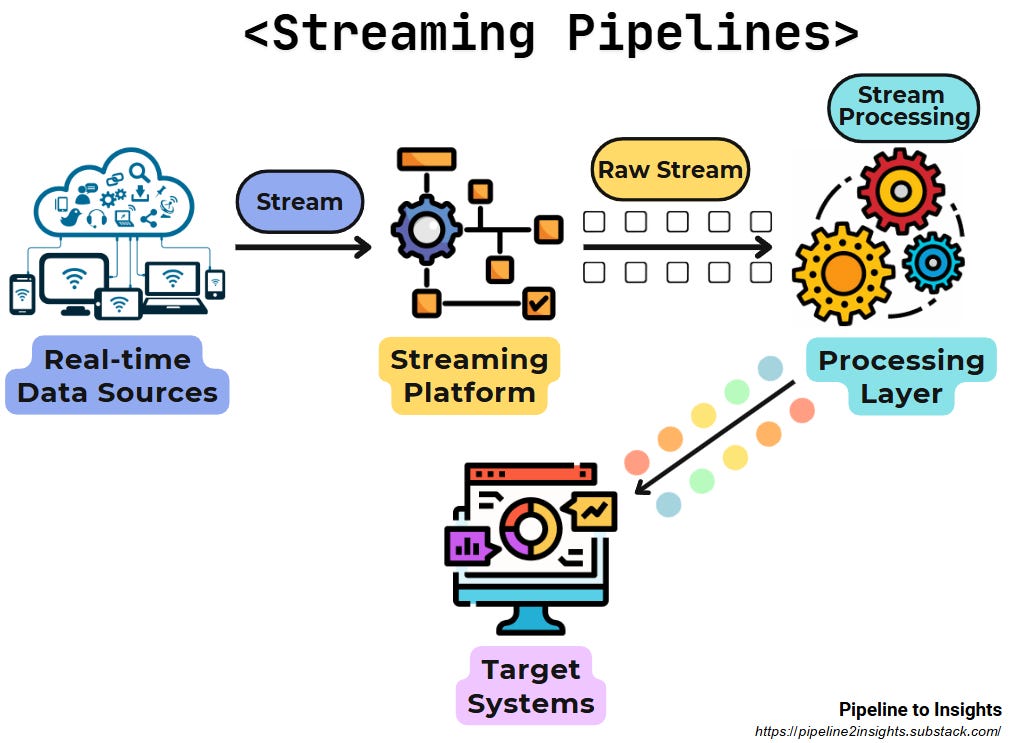
6. Streaming Pipelines:
Purpose: Processes and delivers data in real-time, ensuring continuous updates for systems or applications.
Method: Ingests data from streaming platforms (e.g., Kafka, Kinesis) and processes it in motion without delays.
Benefits:
Provides low-latency insights for real-time decision-making.
Ensures smooth handling of high-frequency, continuous data streams.
Limitations: Requires specialised tools and infrastructure for stream processing and may involve higher costs than batch pipelines.