

Getting Started with Apache Spark: Exploring Big Data Processing
A Beginner's Guide to Big Data Processing✨

Introduction
In today's digital world, we generate around 266 exabytes of data daily. This data comes from things like social media, online shopping, and sensors in smart devices. While this offers great potential, handling such massive amounts of data is challenging, and traditional tools often can't keep up, causing delays and inefficiencies.
Apache Spark is a fast and general-purpose cluster-computing system that has become a cornerstone in the big data ecosystem. It empowers organisations to filter through massive datasets with ease, enabling real-time analytics and decision-making.

In this tutorial, you will :
Learn the basics of Apache Spark
Explore key components:
Resilient Distributed Datasets (RDDs)
DataFrames
Spark SQL
See how to use Spark with a simple application
What is Apache Spark?
Apache Spark is an open-source, unified analytics engine designed for large-scale data processing. It provides an easy-to-use interface for programming entire clusters with implicit data parallelism and fault tolerance.
Key Features:
Speed: Spark processes data up to 100 times faster than traditional Hadoop MapReduce due to its in-memory computing capabilities. By keeping data in memory, it reduces the time spent on disk I/O operations.
Ease of Use: With high-level APIs available in Scala, Java, Python, and R, Spark allows developers and data scientists to write applications quickly in their preferred language.
Versatility: Spark supports multiple workloads, including batch processing, real-time streaming, machine learning, and graph processing.
Core Concepts
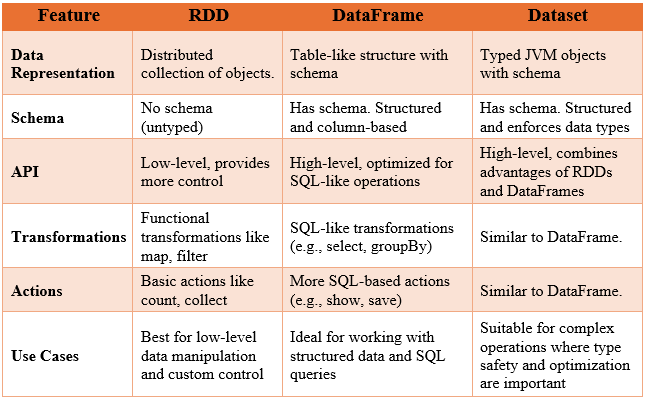
In Apache Spark, understanding the core abstractions is crucial for efficient big data processing. The three primary data structures that Spark provides are:
Resilient Distributed Datasets (RDDs)
DataFrames (via Spark SQL)
Datasets (via Spark SQL)
Resilient Distributed Datasets (RDDs)
RDDs are the fundamental data structure of Spark. They are immutable, distributed collections of data that can be processed in parallel.
Spark SQL and Structured Data
Spark SQL is the module for structured data processing, providing:
DataFrames: Similar to tables in a relational database, dataFrames are distributed collections of data with named columns and schema information.
Datasets: Provide the benefits of RDDs (type safety) and DataFrames (ease of use and performance optimizations).
SQL Querying: Enables querying data using SQL syntax.
With Spark SQL, you can easily switch between coding with API methods and writing SQL queries, while still getting performance improvements.
Getting Started with Apache Spark
In this section, we'll go through the installation process. For this tutorial, we'll use pip to install PySpark, the Python API for Spark. This method simplifies the setup, allowing you to start experimenting with Spark quickly. However, for deploying Spark applications on a cluster or utilising advanced features, you may need to install Apache Spark manually. (This will be covered in upcoming posts, so stay tuned! 👌)
Prerequisites📃;
Java Development Kit (JDK) 8 or Later. Ensure you have the JDK installed.
Verify Java installation:
java -versionPython 3.x. Ensure that Python 3.x is installed, as Spark's PySpark API requires it.
Verify Python installation:
python --versionOnce both the JDK and Python are installed correctly, we can proceed to install Apache Spark.
Install PySpark
Open your command prompt or terminal and run:
pip install pysparkNote: If you're using a virtual environment, activate it before running the installation command.
Verify PySpark Installation
Start a Python shell and try importing PySpark:
import pyspark print(pyspark.__version__)
You should see the PySpark version displayed. If so, you're ready to go! 👌
First Spark Application
A classic way to start with Apache Spark is by creating a simple Word Count application, think of it as the "Hello World" of big data processing. Let's write a simple word count program using PySpark.
Create a Sample Text File
Create a txt file with some text in it like below:
Welcome to Pipeline to Insights! Passionate Data Engineers sharing knowledge from our data journeys.Create a Python script
Next, create a Python script named word_count.py and add the following code:
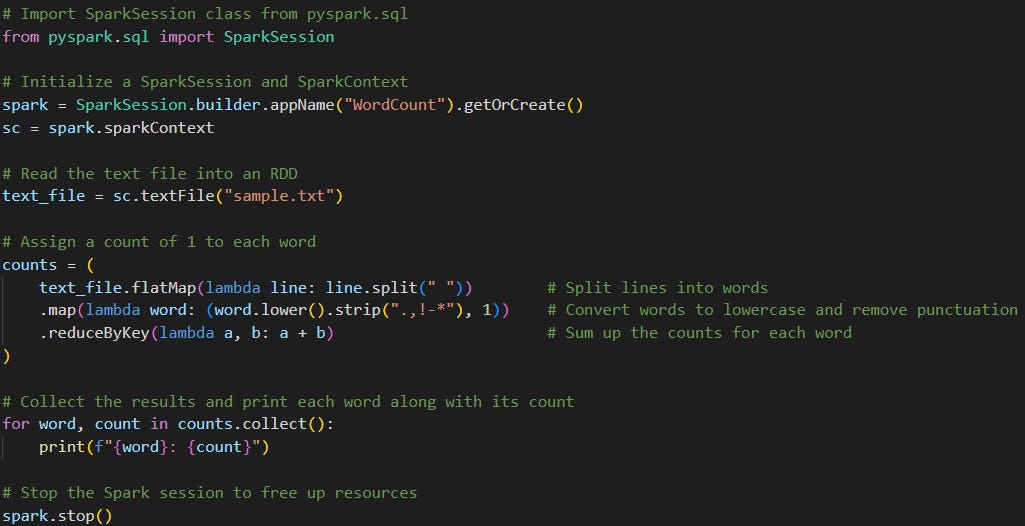
Key Points of the Script:
Data Cleaning:
Converting all words to lowercase to ensure consistency.
Stripping punctuation to avoid counting words like "data," and "data!" separately.
Transformation Operations:
flatMap(): Applies a function to all elements and flattens the result.map(): Transforms each element individually.reduceByKey(): Combines values with the same key using a specified aggregation function.
Action Operation:
collect(): Triggers the execution of the transformations and brings the result.
Run the Script
python word_count.pyExpected Output:
to: 2
insights: 1
passionate: 1
engineers: 1
knowledge: 1
from: 1
our: 1
welcome: 1
pipeline: 1
data: 2
sharing: 1
journeys: 1Note: The counts may vary depending on the exact content of your sample.txt.
Congratulations, you’ve just completed your first Spark application! 🎉

Best Practices
As you begin working with Apache Spark, here are some best practices to keep in mind:
Prefer DataFrames and Datasets over RDDs
DataFrames and Datasets offer significant performance optimisations through the Catalyst optimiser and are easier to use for most data processing tasks.
Leverage Lazy Evaluation
Spark uses lazy evaluation for transformations, meaning it delays computations until an action is called. This helps Spark optimise the execution plan, so it's important to structure your code to make the most of this feature.
Use Built-in Functions
Spark provides a rich set of built-in functions. Utilize these functions instead of writing custom code when possible, as they are optimised for performance.
Avoid Collecting Large Datasets to Driver
Be cautious with actions like
.collect()and.take()when dealing with large datasets, as they bring data into the driver program and can cause memory issues.
Conclusion
In this guide, we've introduced Apache Spark and its core concepts. You learned how to install Apache Spark, create a simple Word Count application, and understand the basics of Spark's data processing capabilities.
This is just the tip of the iceberg, Apache Spark has a vast ecosystem that includes modules for SQL processing, machine learning, streaming data, and graph computations. Stay tuned for future posts where we'll dive deeper into Spark's advanced features and real-world use cases.
Join The Conversation!
We hope you found this guide helpful. If you have any questions, comments, or experiences you'd like to share, we'd love to hear from you!
If you're interested in more posts like this, be sure to subscribe for upcoming tutorials, deep dives, and insights. Let's learn and grow together in the exciting world of data engineering!