
Data Modelling Fundamentals: Normalisation, 3NF and Dimensional Modelling
Normalisation, 3NF, and dimensional modelling, with insights into Star and Snowflake schemas for efficient database and warehouse design

In this post, we will explore essential data modelling concepts for database and data warehouse design. We’ll cover
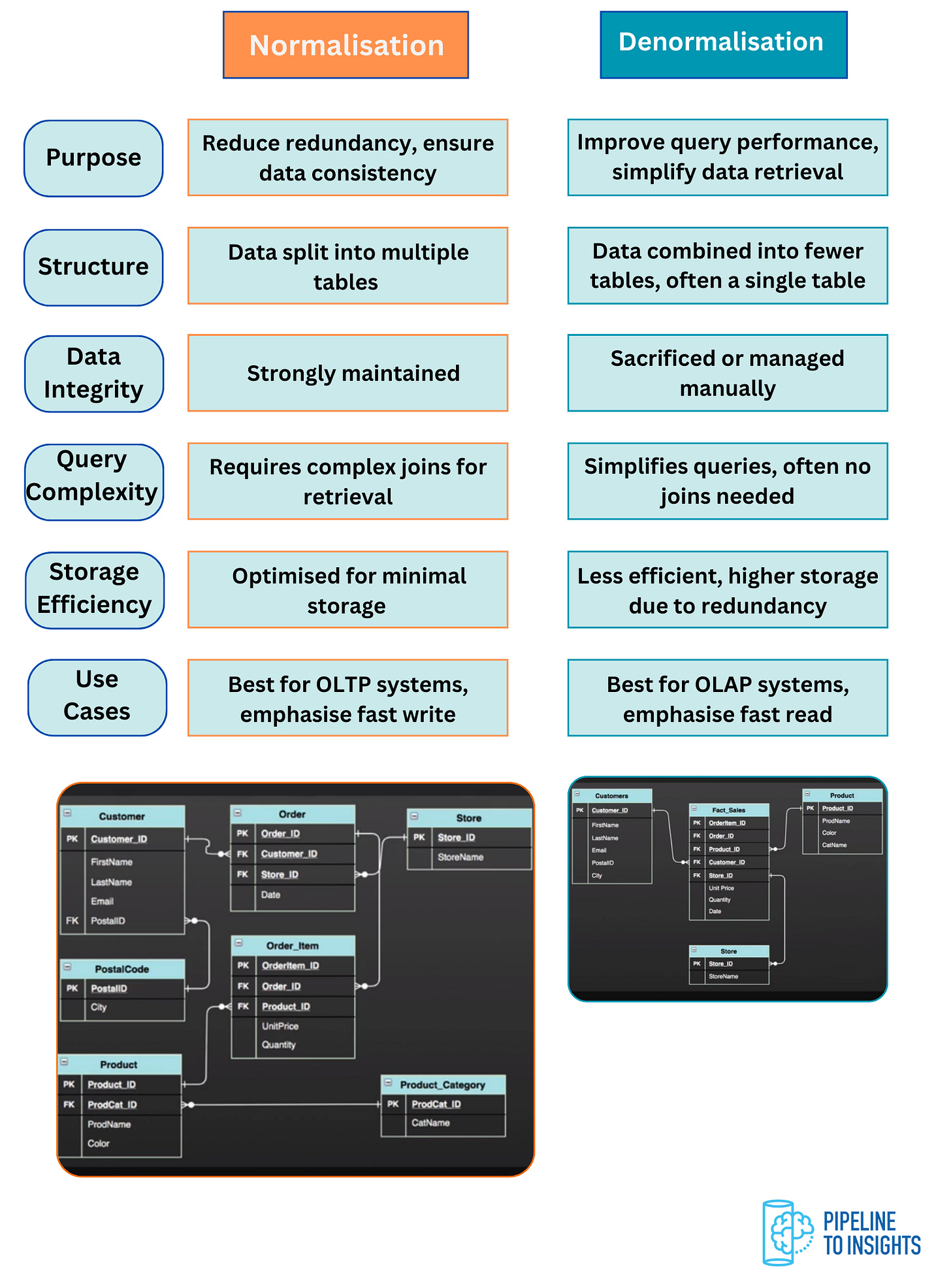
Normalisation vs. Denormalisation
Understanding the differences between these two approaches.
Use cases for each in database and data warehouse design.
Implications on performance, storage, and data integrity.
3NF (Third Normal Form)
A detailed explanation of this important normalisation standard.
Dimensional Modeling
Exploring its core concepts
Star Schema vs. Snowflake Schema
Comparing these two data warehouse design approaches: the Star vs. Snowflake Schema
If you're interested in learning more about data modelling, including definitions, various types of data models, ER diagrams, and the differences between OLTP and OLAP systems, be sure to check out our previous post:

Normalisation vs. Denormalisation
In data modelling, we often encounter two techniques.
Normalisation is the process of breaking larger tables into smaller, related tables to reduce redundancy and ensure data consistency. The goal is to simplify the database, eliminate duplicates, and organise data efficiently.
Denormalisation involves merging data from multiple tables into one to make data retrieval faster.

Before going into details of normalisation and different normalised forms, we will describe Relational Data Modelling.
Relational Data Modeling
Relational data modelling organises data into tables with rows and columns, minimising redundancy and linking tables through foreign keys. It provides flexibility, and data independence, and is based on mathematical principles, forming the foundation for relational databases.
If you're interested in the history of relational data modelling, check out:
But how do we normalise our data or database? Through Normal Forms!
What is Normal Forms?

Normal forms are a set of rules in database normalisation that define how to organise data into structured tables to reduce redundancy, ensure data consistency, and maintain integrity. Each normal form builds upon the previous one to improve database design.
The primary normal forms include:
First Normal Form (1NF)
Second Normal Form (2NF)
Third Normal Form (3NF)
Optional higher forms include:
Fourth Normal Form (4NF)
Fifth Normal Form (5NF)
Sixth Normal Form (6NF)
3NF is the most commonly used, so we'll focus on that in this example. To understand 3NF, we start with 1NF and 2NF, showing how each step improves the database design. These normal forms are cumulative, meaning each builds on the previous one.
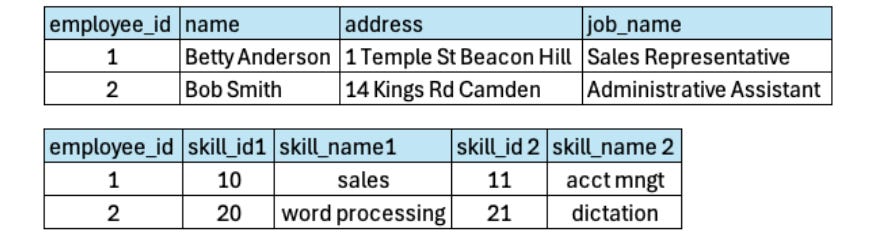
Let's assume we have employee and employee skill data in the following format.

The First Normal Form – 1NF
The criteria of the first normal form are:
Each cell must hold no more than one value so we need to split such columns into separate columns. (This property is called Atomicity)

Each row in a table must be unique, which means there needs to be at least one column (or a combination of columns) that can uniquely identify each row. This unique column is called the Primary Key.
Note: The primary key is often automatically generated by the system, such as an ID number, to ensure every row is distinct.
Each column must have a unique name.
You can define the following:
skill_id1,skill_name1,skill_id2, andskill_name2.There should be no repeating groups in a table. If any repeating groups exist, they should be moved into a separate table.
The repeating group (skill_id1, skill_name1, skill_id2, skill_name2) will be moved to a separate table to eliminate redundancy.
So at the end, we have two tables in the First Normal Form.
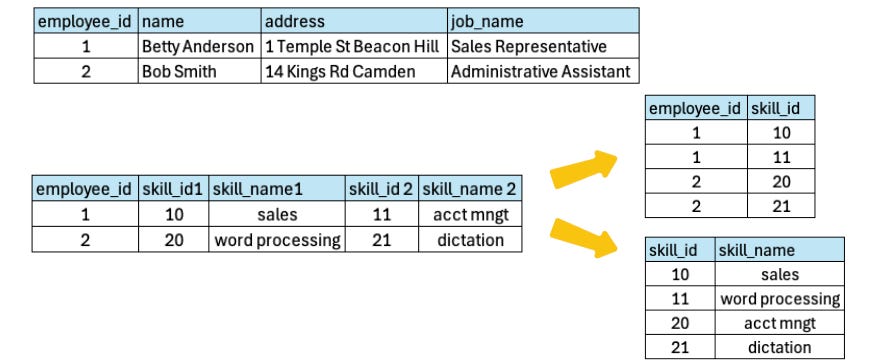
The Second Normal Form – 2NF
The criteria of the second normal form are;
It should satisfy all the criteria of 1NF.
All data in a table must depend on the primary key, and any column that does not depend on the primary key should be split into its own table.
Note: A Foreign Key is a primary key from one table that is used to link it to another table.
So at the end, we have three tables in the second Normal Form.
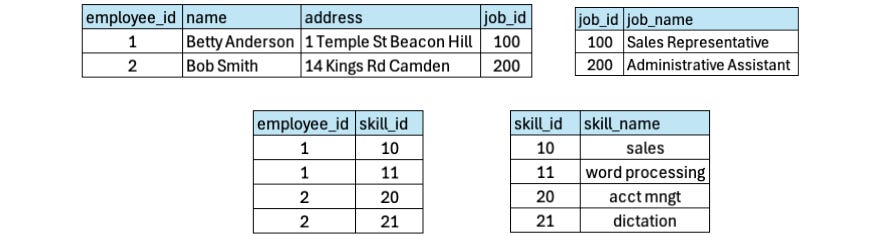
The Third Normal Form – 3NF
The criteria of the third normal form are;
It should satisfy all the criteria of 2NF.
The primary key must fully define all columns and all columns might not depend on any other key.
In this example, employee_id determines the name and address, but the name and address don’t depend on any other key. However, employee_id does not determine job_name, which breaks the rules of the Third Normal Form (3NF).
So at the end, we have four tables in the third Normal Form.
To conclude:

Dimensional Data Modelling
Dimensional Data Modelling is a technique that organises data into two categories: dimensions (such as users, and listings) and facts (like logins or purchases). This approach, popularised by Ralph Kimball, optimises data warehouses for efficient querying and reporting.
For more details, check out Kimball Group's resources.

The key part of Dimensional Modelling:
Fact table: Stores the most basic unit of measurement of a business process.
Dimension table: Stores the who, what, when, and where of each business process.
Primary key
Foreign key
Dimensional data modelling is very powerful because you can use facts and dimensions to answer very complicated questions about the relationships of the who and what inside your data. It also has enforced integrity that offers guaranteed quality!
Pros and Cons of Dimensional Modelling

Dimensional Modelling Design Process
In the dimensional modelling approach, four key steps guide the design process:
Select the business process: Identify the specific business activity or event to be analyzed, such as sales, orders, or inventory.
Declare the grain: Define the level of detail the fact table will represent, such as individual transactions or daily summaries.
Identify the dimensions: Determine the descriptive attributes (e.g., product, time, customer) that provide context for the facts.
Identify the facts: Choose the numeric metrics (e.g., sales amount, quantity) to be measured and analyzed.
These decisions are made collaboratively, considering both business requirements and the constraints of the source data.
After defining the process, grain, dimensions, and facts, the design team finalises details like table and column names, sample domain values, and business rules. Active participation from business data governance representatives ensures the design aligns with business goals and gains stakeholder approval.
In the next post of our interview preparation series, we’ll provide a step-by-step example of designing a dimensional model. Stay tuned!🙂
Star vs Snowflake Schema
Two common data modelling approaches are star schema and snowflake schema:
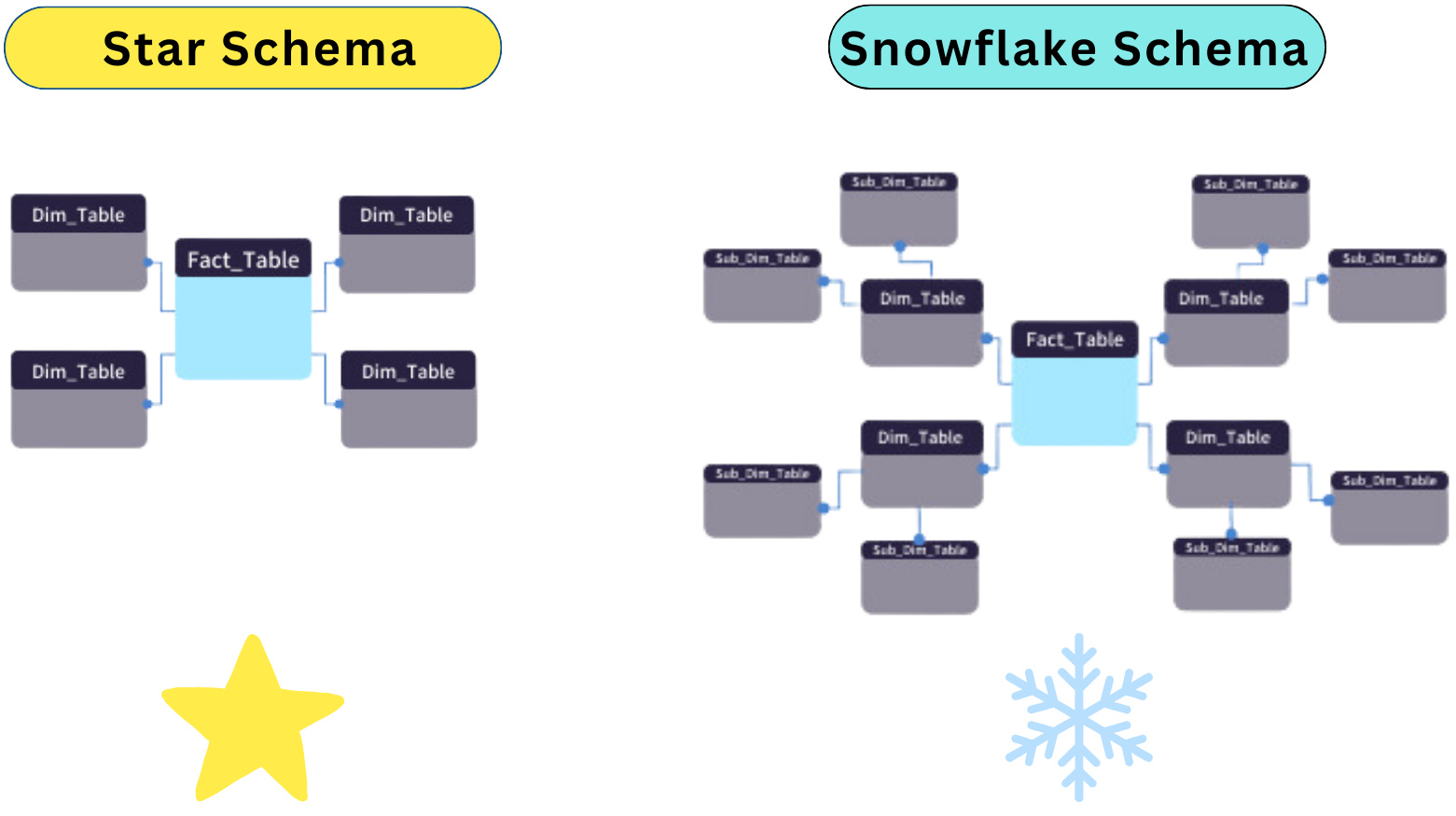
Star Schema
A star schema is a dimensional modelling technique used in databases and data warehouses to organize data for easy analysis and understanding.
Key Features
Simple Structure
Consists of a single fact table at the center, surrounded by dimension tables.
The structure resembles a star, with the fact table as the core and dimension tables as the points.
Dimension Tables
Dimension tables do not join with each other, so they do not have foreign keys.
They provide descriptive attributes for the facts, supporting detailed analysis.
Fact Table
Contains numerical data and keys that link to the dimension tables.
Represents measurable business metrics (e.g., sales, revenue, etc.).
Snowflake Schema
The Snowflake Schema is an extension of the Star Schema, where dimension tables are normalized into multiple related tables. This design reduces data redundancy but increases complexity.
Key Features
Normalised Structure
Dimension tables are broken down into smaller, more specific tables.
This normalisation reduces redundancy by storing unique values in separate tables.
Fact Table
Similar to the Star Schema, the fact table remains at the centre, storing measurable business metrics.
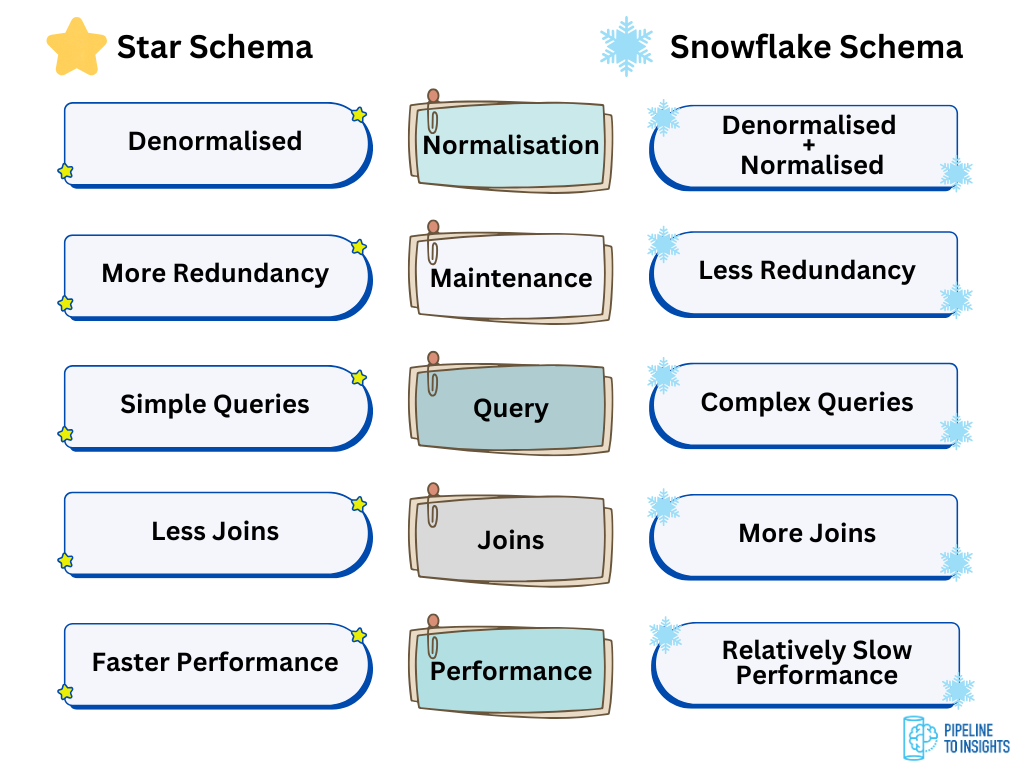
While the Snowflake Schema is more space-efficient and better for data integrity, it trades off query performance and simplicity. It is best suited for use cases where disk space optimisation is a priority over fast query speeds.
Star Schema vs. Snowflake Schema
Conclusion
In this post, we've covered various data modelling techniques and concepts essential for database and data warehouse design. We explored;
Normalisation vs. Denormalisation
The rules of each normal form
3NF (Third Normal Form)
Dimensional modelling
Star schema vs. Snowflake schema
In the upcoming posts, we'll dive into slowly changing dimension types for tracking data changes over time, One Big Table (OBT), a denormalised method that combines multiple tables into one large table, and Data Vault, a hybrid approach for managing historical data and ensuring flexibility in large-scale data warehouses.
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Hi Sunday,
Thank you for your comment,
Sure we try our best to help, could you please elaborate the other two data models ? Are they database schema ?
Is your end goal to have a JSON schema ?
Thanks for this,please I need more info about unification of 2 data models and JSON in Schema.