

Week 19/31: Cloud Computing for Data Engineering Interviews
Understanding Cloud Computing and Infrastructure as Code (IaC) and their roles in Data Engineering

In the last decade, cloud computing has reshaped Data Engineering.
For Data Engineers, cloud computing is no longer optional.
Cloud services are the foundation of modern data pipelines. From storing the raw data to orchestrating sophisticated transformation workflows, the cloud offers services and tools designed to support every stage of the data lifecycle.
Almost all companies today, from early-stage start-ups to large enterprises, are running their services and data platforms on the cloud. As a result, employers actively seek candidates with hands-on experience with at least one major cloud provider such as AWS, Azure, or Google Cloud Platform (GCP).
Interviewers are no longer just looking for traditional ETL or SQL skills; they want engineers who can design scalable data systems, build resilient pipelines, and manage cloud resources efficiently. These abilities have become fundamental for standing out in both entry-level and senior-level interviews.
In this post, we will discuss:
What is Cloud Computing?
The most common cloud services and platforms that Data Engineers work with.
The must-know tools that are frequently discussed in technical interviews.
Infrastructure as Code (IaC) and Terraform.
Cloud best practices for Data Engineers.
What is Cloud Computing?
At its core, cloud computing is the delivery of computing services such as storage, processing power, databases, networking, and software over the internet, instead of relying on local servers or personal machines.
Rather than buying and maintaining physical hardware, companies can rent the resources they need from cloud providers like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP). These resources are available on demand, can scale almost infinitely, and are charged based on usage, offering a flexible and cost-efficient alternative to traditional infrastructure.
In the context of Data Engineering, cloud computing allows teams to:
Store structured and unstructured data.
Run data processing workloads at scale.
Build automated, reliable, and distributed data pipelines.
And deploy solutions quickly across different regions of the world.
In interviews, candidates are often asked about their experience with specific services, their ability to design cloud-native architectures, and their familiarity with data engineering concepts in the cloud.
Note: As the co-authors of Pipeline To Insights, we have participated in 50+ Data Engineering interviews total, and in every single one, at least one or two questions were related to cloud services.
Whether it was a general question like "Are you familiar with [AWS / Azure / GCP]?" or a more practical scenario like "How would you design [X] using [Y cloud service]?", cloud expertise consistently came up.
This is a list of the Data Engineering tasks and the services from the three biggest cloud providers offered for them.
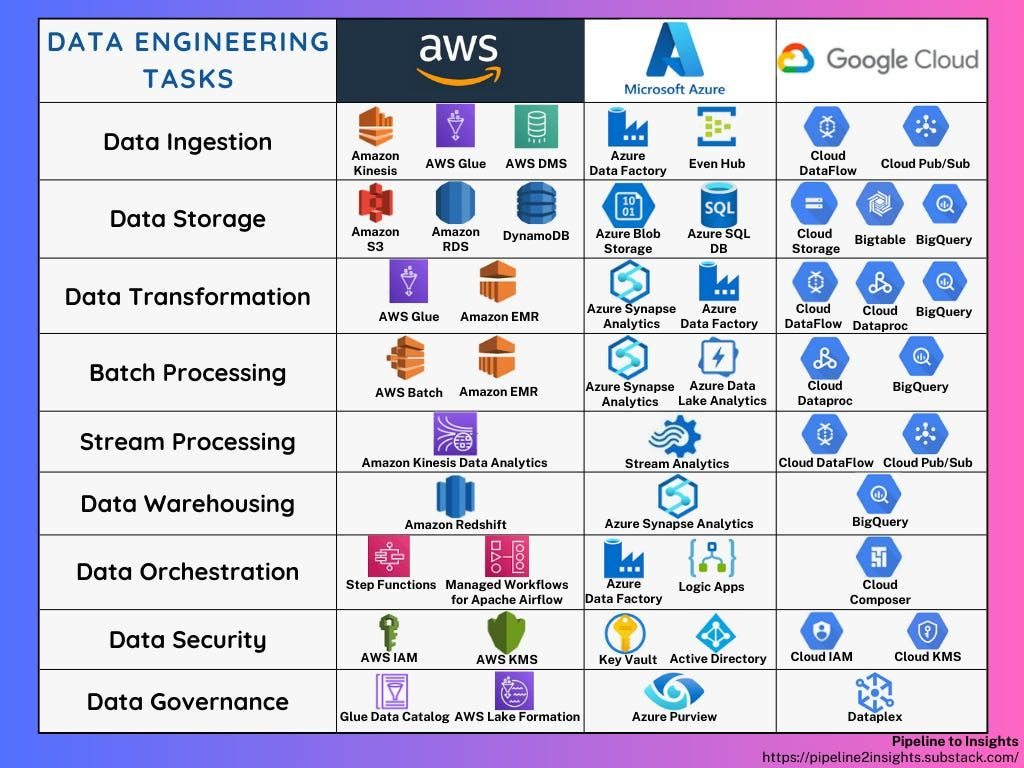
In the next section, we will focus on some of the most common tools.
Common Cloud Services Used by Data Engineers
When working with cloud platforms, Data Engineers typically utilise a core set of services that support the components of the data engineering lifecycle and undercurrents.
If you are not familiar with the data engineering life cycle or need a reminder, you can check our Data Engineering Lifecycle Series here: [link]1
1. Storage Services
Key Services:
AWS S3 (Simple Storage Service)
Azure Blob Storage
Google Cloud Storage (GCS)
These services are object storage solutions, capable of handling massive volumes of unstructured and semi-structured data efficiently and cost-effectively.
Candidates are often asked how they would design a scalable data storage system. Knowing how S3 or GCS works, storage classes (e.g., Standard vs. Glacier in AWS), and best practices for organising buckets is commonly expected.
2. Compute Services
Key Services:
AWS EC2
Azure Virtual Machines
GCP Compute Engine
These services allow Data Engineers to launch virtual machines to run data pipelines, custom scripts, or even data processing frameworks like Apache Spark. Understanding compute instance types (memory-optimised, compute-optimised), availability, and cost considerations is crucial.
3. Managed Database Services
Key Services:
AWS RDS (Relational Database Service)
Azure SQL Database
Google Cloud SQL
These services abstract away the operational burden of backups, patching, and scaling databases like PostgreSQL, MySQL, and SQL Server. Interviewers may ask, “How would you architect a pipeline that writes into a relational database?” or “How would you ensure high availability and scaling?”.
4. Data Warehousing Services
Key Services:
Amazon Redshift
Google BigQuery
Azure Synapse Analytics
These are specialised databases optimised for fast read queries across very large datasets (hundreds of GBs to petabytes). Common interview topics include "How would you design a reporting pipeline for a company's analytics needs?" or "How would you partition data in a warehouse to optimise performance?"
Note: In addition to these cloud-native options, many companies use:
Snowflake: Popular for its architecture, decoupling storage and compute, automatic scaling, and cross-cloud compatibility.
Databricks: Popular for unifying big data processing, analytics, and warehousing, especially when implemented using a lakehouse architecture.
For Snowflake and Databricks, you can check out the posts below.


5. Big Data and Streaming Services
Key Services:
Batch processing:
AWS EMR
Azure Databricks
GCP Dataproc
Streaming data ingestion:
Amazon Kinesis
Azure Event Hubs
Google Pub/Sub
These services allow real-time data ingestion from applications, sensors, and websites, and support distributed processing frameworks like Apache Spark. Interviewers may ask questions like “How would you build a streaming pipeline for real-time analytics in Azure?"
Demonstrating knowledge of concepts like stream and batch processing, event time and ingestion time, and Spark/Kafka basics can make a big difference.
For batch vs. stream data ingestion, check out:

6. Monitoring and Alerting Services
Key Services:
AWS CloudWatch
Azure Monitor
Google Cloud Operations Suite
These services are for monitoring cloud services within a cloud provider. Questions like “How would you monitor a pipeline?” or “How would you alert the team if there is a failure in a pipeline?” are very common.
For more details on monitoring, check out:

Important Services and Tools for Data Engineers
Beyond knowing the basic building blocks of cloud platforms, interviewers increasingly expect Data Engineers to be familiar with key services and tools that enable scalable, event-driven, and reliable data systems.
1. Serverless Data Processing: Allows running lightweight data transformation, ingestion, or orchestration tasks without managing servers. With serverless, we simply write our code, and the cloud provider automatically handles resource provisioning, scaling, and billing based on actual usage.
Key Services:
AWS Lambda
Azure Functions
Google Cloud Functions
2. Orchestration and Workflow Management: Useful for managing complex multi-step workflows, scheduling jobs, and handling dependencies between tasks.
Key Services:
AWS Step Functions (state machine orchestration)
AWS MWAA (Managed Workflows for Apache Airflow) (fully managed Airflow service on AWS)
Google Cloud Composer (managed Apache Airflow on GCP)
Azure Data Factory (visual ETL orchestration platform)
For more details on Orchestration and Workflow Management, check out weeks 16, 17, and 18 in our interview preparation series: [Data Engineering Interview Preparation Series]2
3. Monitoring and Observability: Helps ensure cloud pipelines and infrastructure stay healthy, performant, and cost-efficient.
Key Services:
AWS CloudWatch Logs, Metrics, and Alarms
Azure Monitor Insights
Google Cloud Logging and Monitoring
Setting up effective logging, metrics collection, dashboards, and proactive alerts helps detect issues like failed ETL jobs, high latency, or cost spikes early.
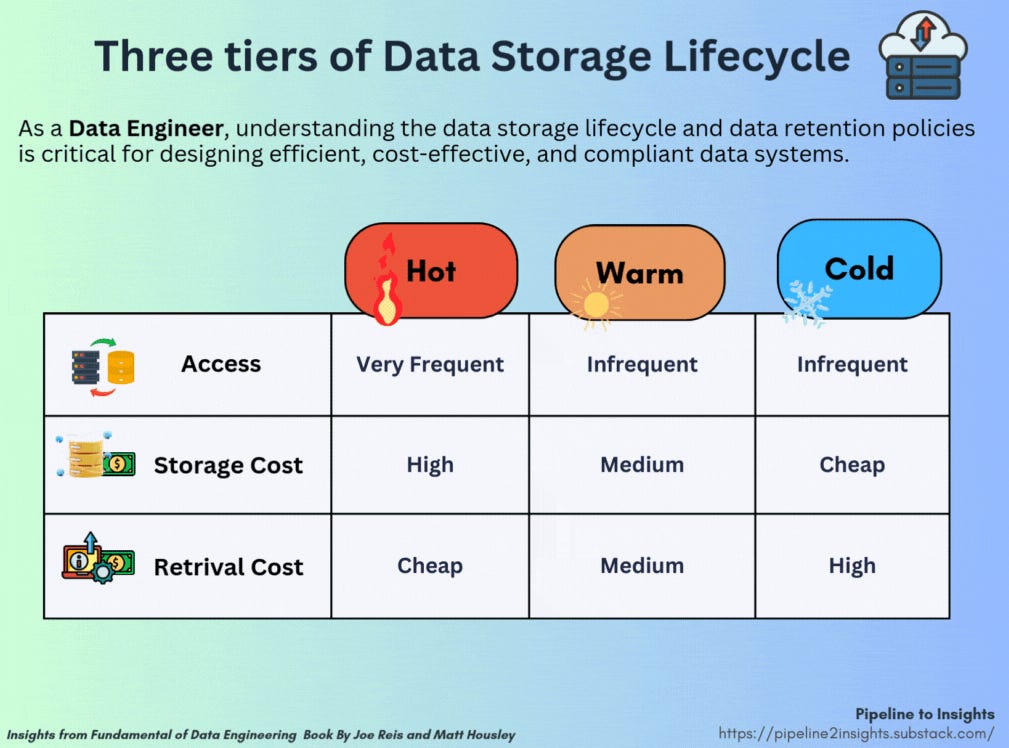
Infrastructure as Code (IaC)
 | Digital Power")
Modern data systems are not just about pipelines, databases, and APIs.
Data systems require building a reliable infrastructure to host, connect, and operate various services and blocks. This is where Infrastructure as Code (IaC) becomes an essential skill, especially for Mid and Senior Data Engineer roles.
Modern data systems need infrastructure that is:
Consistent across environments (development, staging, production),
Scalable to meet varying workloads,
Easily maintainable and auditable,
Cost-efficient and secure.
Infrastructure as Code means defining and managing the cloud resources through code (instead of manual clicks on cloud consoles). This allows us to:
Version-control infrastructure alongside application code,
Reproduce environments easily across development, staging, and production,
Automate deployments to avoid human errors,
Scale infrastructure confidently, knowing it is consistent and repeatable.
Note: Building on the cloud services questions we mentioned earlier, we also found that in almost every interview, there was a follow-up question like:
"How did you develop or implement the infrastructure for your data pipelines or platform?"
Popular IaC Tools:
Terraform (most popular, cloud-agnostic, works with AWS, Azure, GCP, and more).
AWS CloudFormation (AWS-specific IaC service).
Azure Resource Manager (ARM) templates (for Azure environments).
Among these, currently, Terraform stands out as the industry standard across multi-cloud setups because of its:
Simple and declarative language,
Large ecosystem of modules and providers,
Reusability and modularity for building scalable infrastructure.
Example Use Cases for Terraform in Data Engineering
Common real-world tasks a Data Engineer might automate with Terraform:
Provisioning data storage (S3, GCS, Blob Storage)
Deploying compute resources for batch processing (EC2, GCP Compute Engine)
Managing database services (RDS, BigQuery datasets)
Automating security policies (IAM roles, bucket policies, service accounts)
Setting up workflow orchestrators (MWAA environments, Composer deployments)
Here’s a basic example showing how Terraform can be used to create a database instance in AWS:
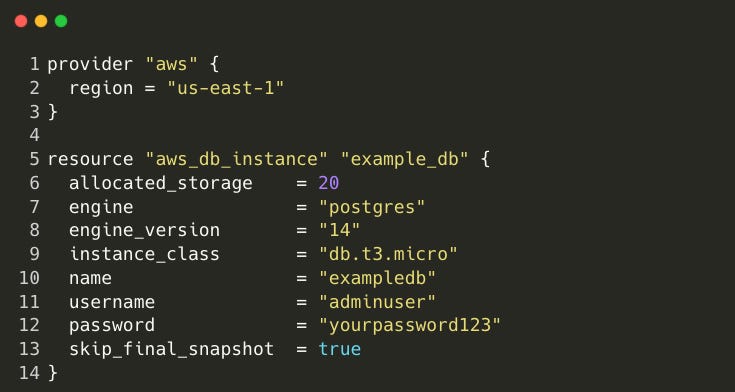
If you’re interested in learning more about Infrastructure as Code (IaC), check out our mini-series3 where we cover Docker, Terraform, and Kubernetes.
Cloud Best Practices for Data Engineers
Building data pipelines and infrastructure in the cloud offers great flexibility, but it also introduces new challenges.
To succeed both in real-world projects and interviews, it’s important to not only use cloud services but also use them well.
1. Design for Failure and Recovery
Cloud environments are inherently distributed, and failures (even minor ones) are inevitable. Pipelines should be designed to:
Retry transient failures automatically,
Resume from the last successful state when possible,
Alert engineers proactively rather than silently failing.
2. Optimise for Cost Efficiency
Cloud services are billed based on usage, and costs can escalate quickly if not managed carefully. Data Engineers should:
Choose appropriate storage classes (e.g., S3 Standard vs Glacier),
Optimise compute instance types (e.g., memory-optimised vs compute-optimised),
Schedule shutdowns for non-production environments,
Monitor and alert on unexpected cost spikes.
3. Consider Security at Every Layer
Data security and compliance are critical when working in the cloud. Good practices include:
Encrypting data at rest and in transit,
Applying the principle of least privilege when assigning IAM roles and permissions,
Managing secrets securely using services like AWS Secrets Manager, Azure Key Vault, or GCP Secret Manager.
4. Build Observability into the Systems
Reliable data systems are observable. This means they have:
Metrics (e.g., pipeline duration, failure rates),
Logs (for tracing execution and errors),
Dashboards (for real-time system health),
Alerts (for early warnings about issues).
5. Manage Infrastructure as Code
As discussed earlier, using tools like Terraform to manage cloud infrastructure ensures:
Repeatability across environments,
Easier disaster recovery,
Faster onboarding for new team members,
Safer rollbacks and updates through version control.
Many of these best practices directly address common pitfalls that Data Engineers encounter when working with cloud environments. If you’d like to dive deeper into typical mistakes and how to avoid them, check out our post:

Conclusion
Cloud computing has become a core foundation of Data Engineering, and a key focus in interviews for both entry-level and senior roles. From building scalable storage layers to orchestrating complex workflows and managing infrastructure with code, cloud skills are no longer optional; they are expected.
In the next post, we will dive deeper into one of the fundamental areas for cloud-based data engineering: Data Storage Paradigms.
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
https://pipeline2insights.substack.com/t/data-engineering-life-cycle
https://pipeline2insights.substack.com/t/interview-preperation
https://pipeline2insights.substack.com/t/devops-for-dataengineers