
Week 8/31: Programming for Data Engineering Interviews
Understanding Common Python Practices in Data Engineering

Programming is a fundamental skill for Data Engineers, and most roles require a strong foundation in Software Engineering. Data Engineers are expected to write scalable, maintainable, and efficient code, ensuring smooth data pipelines and system integrations.
Since this series focuses on Data Engineering Interviews, we assume that readers already have basic programming skills. Instead of covering fundamental syntax, this post highlights concepts, best practices, and real-world techniques that Data Engineers should practice to perform well in interview processes.
When it comes to hands-on coding assessments, companies generally use one of two approaches in their interview process:
LeetCode-style algorithmic challenges are typically used by large tech companies (e.g., FAANG, Fortune 500).
Practical technical assessments, where candidates work on real-world data engineering tasks like data transformation, file handling, and API integrations.

These days, most companies prefer the second approach, evaluating candidates based on how they handle realistic data scenarios rather than abstract algorithmic problems. However, some big tech firms still use LeetCode-style questions as part of their online screening process.
In this post, we will focus on the practical programming skills tested in technical assessments, covering common coding tasks expected in Data Engineering interviews. In the next post, we’ll tackle Data Structures & Algorithms and explore how to approach LeetCode-style questions.
Topics Covered in This Post:
String Manipulation: Cleaning, formatting, and extracting structured data from text using Python’s built-in string methods and regular expressions (re library).
File Handling: Working with structured and unstructured data files using pandas, os, and JSON libraries to read, write, and process CSV, JSON, and text files efficiently.
Working with Databases: Querying and interacting with databases using psycopg2, SQLAlchemy, and DuckDB.
Data Processing & Transformation: Handling missing data, filtering, and aggregating datasets using pandas.
API & Web Scraping: Fetching data from APIs, handling authentication, and scraping web pages using requests and BeautifulSoup for structured data extraction.
After covering the topics, we work through a technical assessment, a realistic interview task that many companies use to evaluate candidates.
Interacting with storage systems (e.g., S3, HDFS) and file transfer protocols (e.g., FTP, SFTP) is also a crucial part of Data Engineering. These topics will be covered in the ETL and ELT Processes posts in this series.
To access all posts of this series, check here: [Data Engineering Interview Preparation Series]
String Manipulation
String manipulation is a commonly overlooked skill in Data Engineering interviews, yet it plays a crucial role in cleaning, transforming, and extracting meaningful information from raw data. Whether it's parsing logs, processing user input, or extracting key identifiers, strong string-handling skills can significantly improve data processing efficiency.
Common Tasks in String Manipulation
In Data Engineering, string manipulation is frequently required for various tasks, including:
Splitting and Joining Strings: Breaking text into parts or merging components into a structured format.
Cleaning and Formatting Text: Removing special characters, extra spaces, or normalising cases for consistency.
Extracting Patterns with Regular Expressions (Regex): Finding structured information in unstructured text.
Parsing Logs and Raw Data: Extracting relevant information from log files, error messages, or semi-structured text.
Handling Encodings and Unicode Issues: Ensuring text is properly encoded and avoiding errors when working with different languages or character sets.
1.1.Splitting Strings
Splitting and joining strings are fundamental operations in data engineering and are commonly used for data cleaning, transformation, and extraction. These operations help in scenarios such as:
Extracting key attributes (e.g., domain names from emails, table names from file paths).
Parsing delimited text (e.g., breaking CSV lines, splitting log messages).
Standardising and structuring data for further analysis.
In the following snippet, we split each email at the '@' symbol to extract the domain name:
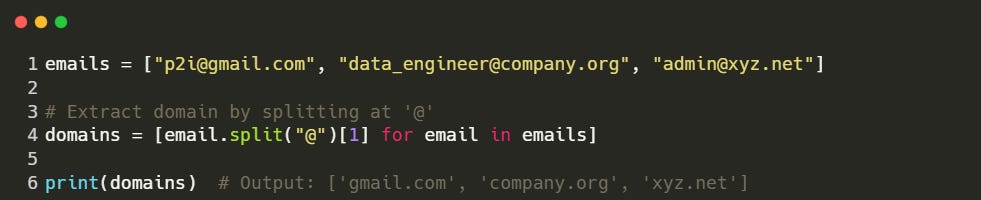
Use Case: This method is useful for categorising users based on their email domain (e.g., distinguishing corporate vs. personal email accounts).