
7 key factors every Data Engineer Should Consider When Choosing Tools
What I wish I knew before choosing my Data Engineering Stack for my team

As data engineers, we might find ourselves working alone and making tool decisions on our own. At every stage of the data engineering lifecycle, we face a wide range of tools and technologies to choose from. Each decision carries a cost, not just in money, but also in time, complexity, and potential missed opportunities. The tools we choose can either help our team move faster or slow us down. So, how can we make smarter, more effective choices?
If you're interested in learning more about the Data Engineering lifecycle, check out our Data Engineering lifecycle series [here]1.
Over the years, I might have found myself wondering how to choose the right tools. With experience using different tools across various roles, and seeing new ones pop up through LinkedIn posts, meetups, or industry buzz, the question remains: which tool truly fits my needs? Should I use Airflow2 or Dagster3? Airbyte4 or dlt5 for ingestion? And the list goes on.
This post is a summary of what I’ve learned from my experience, courses, videos, and reading. It was also inspired by a subscriber-only video from Seattle Data Guy’s Substack6 by SeattleDataGuy , which offered thoughtful perspectives on tool selection and trade-offs. I’ll share 7 key factors to consider when choosing data engineering tools to help us make smarter decisions:
Define Business Requirements
Assess People and Skills
Research Carefully
Choose Between Build, Buy, Open Source, or Hybrid
Evaluate Costs Beyond Price
Engage Stakeholders Early
Design for Change
1. Define Business Requirements

Before jumping into technical evaluations, step back and ask:
What are we building, and why?
"Is it a data warehouse, an ML pipeline, or something else?"
How will it be used?
Is it embedded in an application, used internally, or exposed to external users?
Who are the users?
Engineers, analysts, business users, or customers?
Start by turning our business goals into clear, practical requirements. This helps us focus on tools that truly match our needs, not just what’s trending or heavily marketed.
Don’t ask, “What’s the best tool?”
Instead ask, “What tool fits our goals, timeline, and team the best?”
2. Assess People and Skills

A tool is only as effective as the people who use it.
Are we working solo or as part of a team?
Does the team have experience with this kind of tool?
How steep is the learning curve?
If a tool looks powerful but our team doesn’t have the right skills yet, it may slow us down, unless we're ready to invest in training or hiring.
Choose tools that match our team’s current strengths, or plan ahead to build the skills we’ll need.
3. Research Carefully

Research is essential, but not all advice applies to our context.
We might come across one blog saying Airflow is the best orchestration tool, while another swears by Dagster. Reviews, rankings, and hot takes can be helpful, but they can also be conflicting and confusing. That’s why we need to dig deeper.
Talk to real engineers and consultants who’ve used the tools in production.
Ask them:Why did they choose it?
What worked well, and what didn’t?
Would they choose it again?
Build a knowledge-sharing network.
We don’t need to figure it all out alone. Start attending meetups, conferences, or even casual coffee catch-ups with other data professionals. Networking isn’t just for finding jobs, it’s also how we find answers.Read with a critical eye.
Case studies and articles are great, but always ask:
“Does this apply to my team, my scale, and my constraints?”
Be skeptical of generic advice. The best tool in someone else’s setup might be the worst choice for ours.
4. Choose Between Build, Buy, Open Source, or Hybrid

When selecting a tool, think about how much control, flexibility, and support we need. There’s no one-size-fits-all answer, each approach has trade-offs.
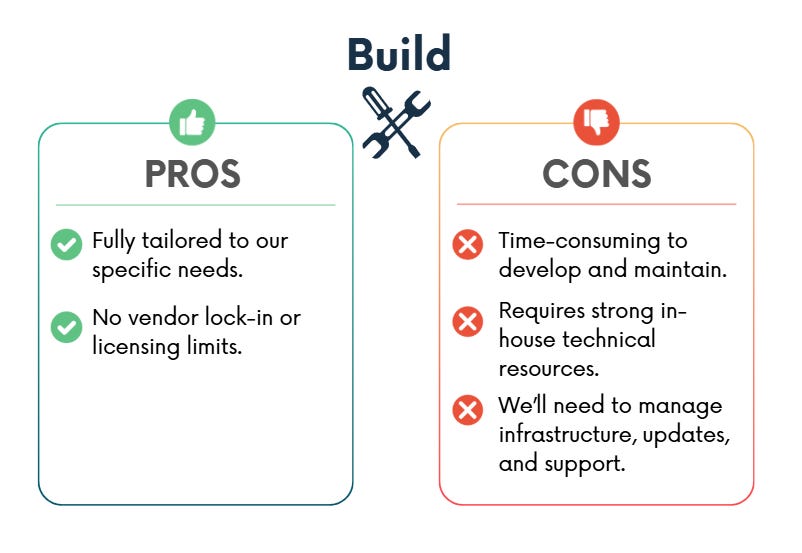
Build
We may choose to build our own solution when we need complete control, deep customisation, or a competitive edge, and our team has the time, skills, and budget to support it long-term.
Buy
Buying is ideal when we want a tool that works out of the box with vendor support and quick setup.

Open Source
Open source tools are often flexible and community-driven, but come with their own challenges.
Some tools labelled as ‘open source’ may be limited unless we pay for their enterprise version.”
“Free” doesn’t mean zero effort. Setup, support, and upgrades can be time-intensive.
Before committing, check how active the community is and whether the project is well-maintained.
Hybrid Approach
In some cases, a hybrid model works best:
Start with a vendor or open-source tool to move quickly, then build our own once our needs become clearer or more demanding.
Use managed tools to deliver value fast.
Transition to a custom solution when the limitations of the off-the-shelf tools start to slow us down.
If you want to learn more about build vs. buy decisions, I recommend reading The Hidden Costs of Build vs. Buy by Veronika Durgin.
Additional Considerations
Don’t pick tools just because they’re popular.
For example, Databricks is a powerful all-in-one platform offering orchestration, warehousing, and Spark processing capabilities, but if our company has a small data footprint, do we need the overhead and cost of distributed parallel processing? “Pay-as-you-go” doesn’t mean “pay for what we don’t use.”
Instead, choose tools based on our actual business needs, data size, and goals, not market hype.
Test Before We Commit
Before finalising our choice, test the tools in our real-world context:
Run Proof of Concepts (POCs) with sample data.
Simulate real data volumes and peak usage.
Measure latency, throughput, and resource use.
Compare performance and ease of use across multiple options.
A small upfront investment in testing can save months of regret later.
5. Evaluate Costs Beyond Price

As a data engineer, our job is to provide a positive return on the investment our organisation makes in its data systems. When choosing tools, don’t just look at the price tag. There are hidden costs that can impact our team and budget:
TCO (Total Cost of Ownership)
Think beyond upfront costs. TCO includes:
Direct costs: Licenses, cloud bills, salaries
Indirect costs: Downtime, training, support, maintenance
TOCO (Total Opportunity Cost of Ownership)
Ask ourselves:
What are we giving up by choosing this tool?
Are we getting locked into a vendor?
Will it slow us down in the future?
Will it be hard to switch later?
FinOps ( Financial Operations)
Cloud-first projects need cloud-first cost strategies:
Pay-as-you-go sounds good, but know what we're paying for.
Track costs clearly and plan for scale.
Cheaper tools can cost more in team time and frustration.
If you’d like to learn more about these cost factors, I recommend checking out the Data Engineering Professional7 course by Joe Reis on DeepLearning.ai.
6. Engage Stakeholders Early

Tools don’t exist in isolation, they impact users across the whole business. So, involve stakeholders early in the decision-making process and be transparent about our choices.
Communicate clearly why we recommend a particular tool and how it benefits each group.
Speak their language: avoid technical jargon and tailor our message to each audience, especially non-technical stakeholders.
Create helpful materials like documentation, videos, and guides to build user confidence with the new tool.
Remember, a tool’s success depends on adoption. The more inclusive and communicative we are, the smoother the transition will be.
7. Design for Change

No decision is permanent. Build our data stack with flexibility in mind.
Avoid monolithic systems; instead, choose modular, plug-and-play components.
Prioritise tools that are easy to replace or upgrade as our needs evolve.
Don’t over-optimise for the distant future, but also avoid locking ourselves into rigid solutions.
Choose tools that deliver value today and can adapt smoothly as our requirements change.
Conclusion
Choosing the right tools as a data engineer is more than just picking popular software; it’s a strategic decision that impacts our team’s productivity, our company’s costs, and the long-term success of our data initiatives. By focusing on our business requirements, understanding our team’s skills, researching carefully, weighing build vs. buy vs. open source options, and involving stakeholders early, weset ourselves up for smarter choices.
Remember, no decision is permanent. Design our stack with flexibility in mind so we can adapt as our needs evolve. The best tools are those that fit our current challenges while allowing room to grow and change without costly disruptions.
A strong data architecture is key to building scalable, reliable, and secure data systems. Keen to learn more? Check out this post:

Looking for practical tips to grow your impact, visibility, and career as a data engineer? Check out this post:

Want to learn from real-world mistakes and lessons to level up your data engineering skills? Check out this post

We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
https://pipeline2insights.substack.com/t/data-engineering-life-cycle
https://airflow.apache.org/
https://dagster.io/
https://airbyte.com/
https://dlthub.com/docs/intro
https://seattledataguy.substack.com/
https://www.deeplearning.ai/courses/data-engineering/
Great article! I especially liked "Assess People and Skills".
In my software engineering times, I needed to build a chat service for our live video streams. The requirement was to build it using Erlang. It's a solid choice for this kind of project.
However, nobody aside from me would be able to support it. So, I built the whole thing using Node.js. Now, they keep evolving this service, even though I left 8 years ago.