

Docker for Data Engineers
From introduction to implementation, learn how to build reliable, reproducible data pipelines using Docker

As a data engineer, we might find ourselves in different scenarios. Maybe we're part of a large team where others handle infrastructure, or perhaps we're the only data engineer managing the entire data platform. In either case, it's crucial to understand the tools and dependencies that support our development workflows.
When we're developing data pipelines, whether with tools like Airflow1, dbt2, or custom scripts, our code often depends on a specific set of configuration files, library versions, and databases. Packaging all these pieces together and ensuring they behave the same way across different environments could be challenging.
We’ve likely run into problems like:
Confusing setup instructions that break on a colleague’s laptop.
Struggles replicating production bugs locally.
This is where Docker becomes invaluable.
Docker helps us create reproducible, isolated environments. For data engineers, this means we can:
Run the same code with the same results across development, testing, and production.
Eliminate dependency conflicts.
Easily share and onboard team members with a standard setup.
Spin up tools like Airflow, Postgres, and dbt with minimal effort.
In this post, we’ll explore:
Virtual Machines vs Containers: Understanding the Key Differences
What is Docker?
Docker Components: Dockerfile, Images, Docker Compose, registries and volumes.
Docker Workflow: How everything fits together in practice.
Introduction to Kubernetes
Hands-On Project: Build a simple data pipeline using dbt and PostgreSQL inside Docker, with a GitHub repo3.
Virtual machine vers Container
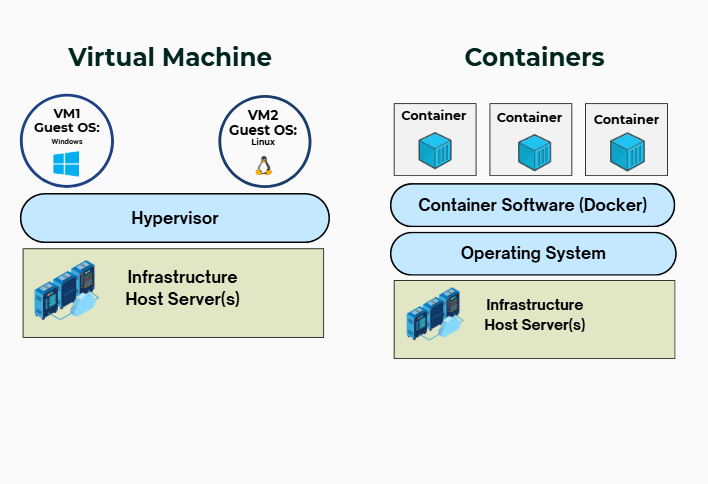
Containers and virtual machines both help run data applications in isolated environments, but they work very differently. Virtual machines (VMs) emulate entire computers using a hypervisor4 (as a virtual machine monitor) that simulates hardware like CPUs, memory, and disks. Each VM includes its own full operating system, which makes them heavier and slower to start. This setup offers strong isolation and flexibility, allowing multiple data apps to run inside one VM, but it also consumes more resources and disk space.
Containers, on the other hand, share the host system’s operating system and run on container runtimes. They don’t need to boot a full OS, so they start up very quickly and use much less space. Containers are lightweight and usually designed to run a single app each, making them highly efficient for deploying many apps at once.

Docker

Before Docker, there were other ways to isolate applications, but they were harder to use. It started with chroot in the 1980s, which let programs think they had their own folder, even though they were limited to just part of the system. Later, systems like BSD Jails5, Solaris Zones6, and Linux Containers (LXC)7 gave more control; they could isolate not just files, but also processes and networks. However, setting them up was complex and not very friendly for developers.
Docker made things much easier. It lets us package everything our data app needs into a container and run it anywhere with just a few simple commands. It also makes sharing containers easy through tools like Docker Hub.
"Docker is like cooking our favourite family recipe."
At home, it tastes perfect. But it's different at a friend’s place, maybe the salt, stove, or pans change the outcome.
Docker solves this for software. It packages everything our app needs: code, tools, and settings, so it runs exactly the same anywhere. Like bringing our own kitchen wherever we go.
Docker Components
As a data engineer, we're often building pipelines, managing databases, and orchestrating tools. Understanding Docker’s core components gives us the power to build portable, reproducible, and scalable environments, essential for real-world data projects.
a. Image

A Docker image is like a recipe or blueprint for running a data application. It defines everything needed to set up and run our data app, from the operating system and software packages to configuration files and commands. We can build our own image or use an existing one, then add custom layers, such as installing dbt, setting up environment variables, or including specific Python packages, to create a fully reproducible and portable setup.
Images are created using a Dockerfile, which lists all the steps and tools required to build the environment. Think of it as a list of ingredients and instructions: technologies our data app needs, the runtime it depends on, and how to launch it. Once built, the image can be shared or reused anywhere, making it easy to reproduce the same setup across different machines or environments.
This Dockerfile from the FreeCodeCamp Data Engineering Course creates a lightweight Docker image designed to run a Python ELT script that interacts with a PostgreSQL database.
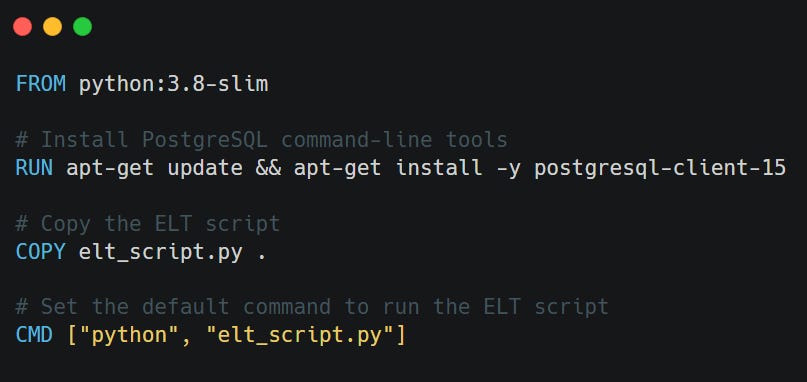
Here's a breakdown of what each line does:
FROM python:3.8-slim
Uses a minimal Python 3.8 base image.
The "slim" tag means it's smaller and faster, with fewer preinstalled packages.
RUN apt-get update && apt-get install -y postgresql-client-15
Installs the PostgreSQL client tools (version 15) so the Python script can connect to and run commands on a Postgres database.
psqland other CLI tools become available inside the container.
COPY elt_script.py .
Copies our local
elt_script.pyfile into the container's working directory.
CMD ["python", "elt_script.py"]
Sets the default command to run the ELT script when the container starts.
b. Container

A container is like a ready-to-serve dish made from the recipe (image).
It’s a running version of an image.
We can start, stop, delete, or run multiple containers at once.
Each container runs in its own little box, so it doesn’t affect our computer or other containers.
b. Registry

A Docker registry is a centralised place where Docker images are stored and managed. The most widely used registry is Docker Hub, which acts like a marketplace for container images. It allows users to upload (push) their own images and download (pull) others, including official and community-contributed ones. Public images are freely accessible, while private repositories offer more control. When we build a Docker image, we can assign it a name and tag, then push it to Docker Hub for reuse or sharing.
c. Docker compose

