Implementing Data Quality Framework with dbt
How to Identify, Address, and Implement Data Quality Solution using dbt

Imagine you’ve just joined a company and encountered data quality challenges. Processes need to be reworked, insights shared with stakeholders fall short of expectations, data delays slow down pipelines, and even seemingly valuable source data is too flawed to generate real impact.
What would you do? Where would you start?🤔💭
You’re not alone! Many of us have faced similar challenges throughout our careers. In this post, we’ll share a step-by-step guide to help you take the initiative and address these issues effectively.
Before diving into this post, we highly recommend checking out our previous post to familiarise yourself with the fundamentals. We covered:
What is Data Quality?
An introduction to data quality dimensions
Examples for each dimension, along with insights from our careers

Understanding the definition of data quality, its dimensions, and metrics is one aspect of the journey. However, the real challenge lies in connecting these concepts and applying them to extract meaningful insights. In this post, we aim to bridge that gap by presenting a practical scenario that a data engineer, analytics engineer, or a similar professional might encounter in a company. We will then outline a structured roadmap to effectively address the issue, demonstrating how data quality principles translate into real-world impact.
Scenario
You’ve just joined a company as a Data Engineer or a similar role, and your first task is to create a data ingestion pipeline for your AI Engineer.
After gathering requirements and exploring the company's SQL Server data, you identify 8 tables to prototype the pipeline. The goal is to enable the AI Engineer to perform analytics and build models. However, after further analysis and discussions with stakeholders, you discover a major roadblock, the source tables lack the necessary data quality to meet business requirements and support the AI Engineer’s needs.

Now, it’s time to take action!
In this post, we’ll walk through a clear, step-by-step approach to building a data quality framework that addresses these challenges and ensures your data is reliable, accurate, and ready for AI-driven insights.
Step 1
The first step is to understand the fundamentals of data quality, including its definition, key dimensions, and common measurement techniques.

You can find this in our previous post here.
Step 2
The second step is to list the data quality issues you encountered while working with the tables intended for the pipeline.

Step 3
The third step is to discuss with downstream stakeholders (in this case AI engineers) to understand what better data quality means to them. It is also good to talk with upstream stakeholders (software engineers, third parties, and so on…) to understand the system that these data generated from. Remember as we mentioned in the previous post, data quality issues might arise since the system was designed for specific operational or transactional purposes.

Step 4
Based on the information and requirements gathered in the previous three steps, document all findings and create a comprehensive list of tables along with their associated data quality issues.

Next, use your understanding of data quality dimensions to categorise each issue according to its corresponding dimension. Aligning issues with their definitions will help quantify data quality and provide insights into the necessary quality checks to implement.
Step 5

Choose a tool to implement your quality checks based on the info you prepared in step 4.
Solution
First, we should mention that the best way to improve data quality is by addressing it at the source. Collaborating with software engineers or those responsible for managing source systems is the ideal way to improve its quality gradually. However, this process can be challenging, as it often requires many meetings and input from different stakeholders to find a solution. For now, we assume this is the only way we can improve data quality. In the future, it's a good idea to work closely with stakeholders to improve quality right from the start.
Step 1
We researched and summarised our understanding in the previous post.
Step 2
Based on the tables we identified for the project, we listed the tables and quality issues.

Step 3
We spoke with downstream stakeholders to define data quality standards and identify what "good" looks like.
For example, for the Customer table:

You can find good examples for the rest of the tables in the final step.
Step 4
Based on the dimensions and the issues listed in the second step, we created this table:
Step 5
Tooling for Data Quality Checks
We use dbt (data build tool) to implement the quality checks. It is a widely adopted tool across small, medium, and enterprise companies due to its robust testing capabilities. Additionally, dbt is highly SQL-friendly, making it accessible to anyone proficient with SQL.
dbt tests can be categorised into Data Tests and Unit Tests, depending on specific requirements.
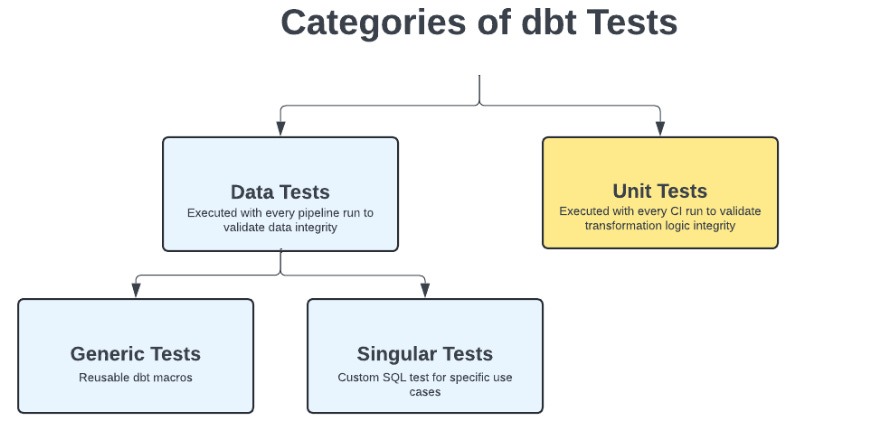
1. Data Tests
These tests are executed with every pipeline run to ensure the quality and integrity of your data. They can be further divided into:
Singular Tests
A singular test is an SQL file that contains a query to identify records that fail specific conditions or rules. It’s a straightforward test that directly checks for data quality issues. this test is specific to the practical model.Generic Tests
A generic test is defined in a YAML file and references a macro that holds the SQL logic for the test. This type of test allows for greater flexibility and reuse. The macro can be configured with Jinja templates and accepts additional parameters, making it adaptable to various scenarios. A generic test typically involves a SELECT statement that returns records failing the condition. Can be applied to any models
For both singular and generic tests, dbt compiles the code into a SQL SELECT statement and runs it against the database. If any rows are returned, it indicates a failure, and dbt will flag it.
2. Unit Tests
Unit tests focus on validating your transformation logic. These tests compare predefined data with the expected results to ensure that your transformation logic is accurate. Unlike data tests, which are executed on every pipeline run, unit tests are usually run during the Continuous Integration (CI) process when new code is introduced. Unit tests were added to dbt Core starting from version 1.8.
By leveraging both data and unit tests, dbt allows you to create a robust testing framework that ensures the quality of both your data and your transformation logic.
For this Scenario, we focus only on Data tests. We also use tests from dbt expectations.
We suggest becoming familiar with dbt, especially its testing features, as they provide a flexible framework for data validation.
Database
In this example, we assume our source data resides in DuckDB, an in-process SQL OLAP database management system. If you’re working with different databases/data warehouses like SQL server, Postgres SQL, Snowflake, Databricks SQL, BigQuery or any other data source, don’t worry, dbt supports them all. For further details, we recommend reviewing the official dbt documentation here.
By using dbt, you'll be able to implement comprehensive quality checks and streamline your data validation process efficiently.
Now, let's implement quality checks for each table. For every table, we’ve defined the dimensions, what good quality looks like, the checks to apply, the type of test, and how we'll implement it.
You can also find the full GitHub repo of this implementation here: [GitHub Repo]1
Note: All data in this example are dummy and for learning purposes.
Table: Customer

Test: expect_column_values_to_match_regex ( from expectations)
Type: Generic
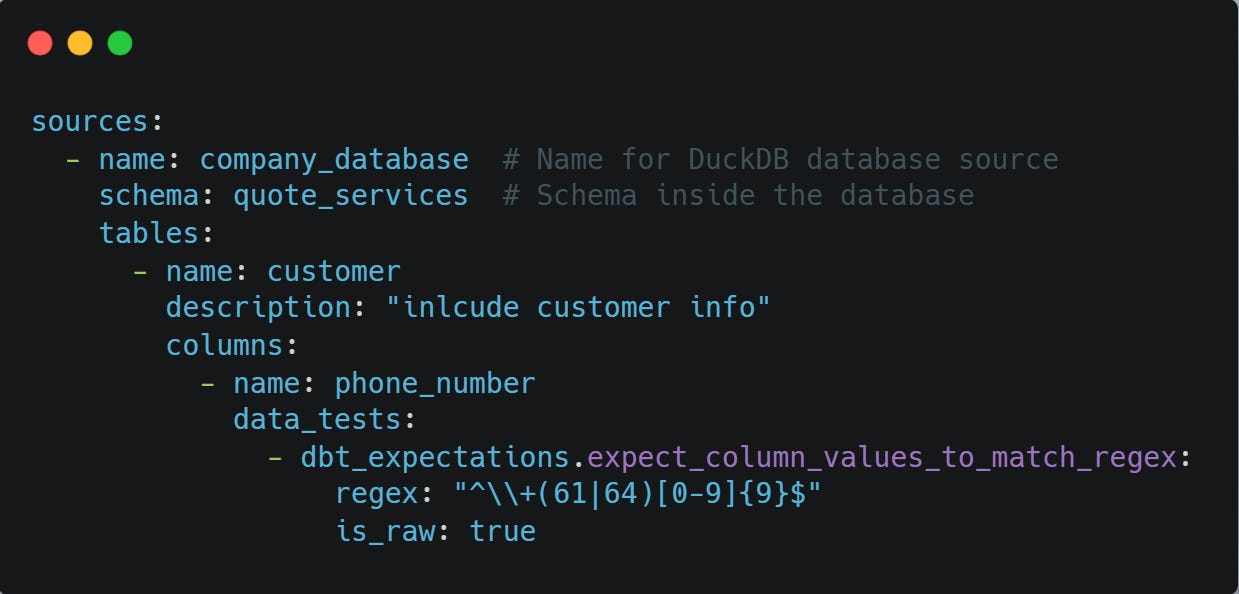
Table: Material

Test:- dbt_expectations.expect_column_values_to_be_in_set ( from expectations)
Type: Generic
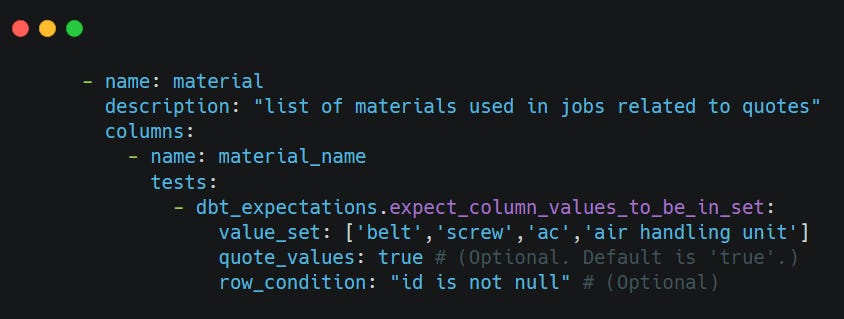
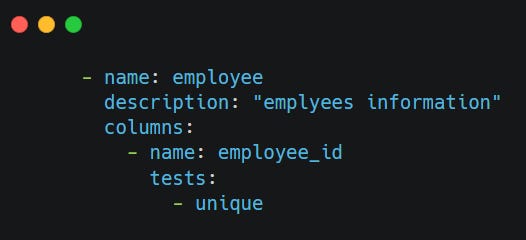
Table: employee
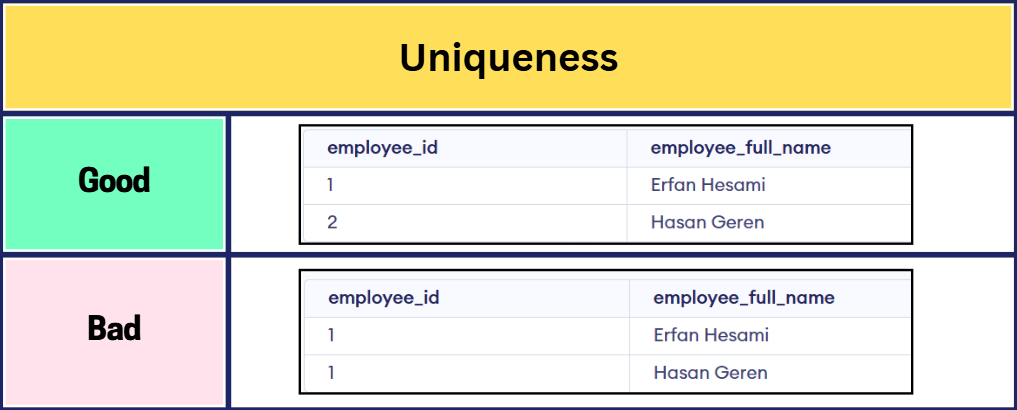
Test: Unique
Type: Generic