
Pandas vs. Polars vs. DuckDB vs. PySpark: Benchmarking Libraries with Real Experiments
A hands-on benchmark comparing CSV loading, filtering, aggregation, sorting, and joins on 5GB (100M rows).

As the size of our data grows, our data pipelines can start running into performance issues. Occasionally, we also need to run ad-hoc scripts, which can take a long time to run. That’s when the question arises: Can we use a better solution? Depending on the size of the data, its characteristics, and the transformations involved, different tools can produce very different results. This situation came up for us recently, and it prompted us to explore what alternatives are available.
In our previous post, we compared Pandas1 vs. Polars2 and saw that Polars consistently outperformed Pandas in key operations, often by several times, thanks to its multi-threaded execution and columnar storage.
In this post, we’re taking things further by adding DuckDB3 and PySpark4 to the mix, while also increasing the size of our input data.
Our goal is to compare Pandas, Polars, DuckDB, and PySpark across practical tasks, rather than focusing on textbook definitions.
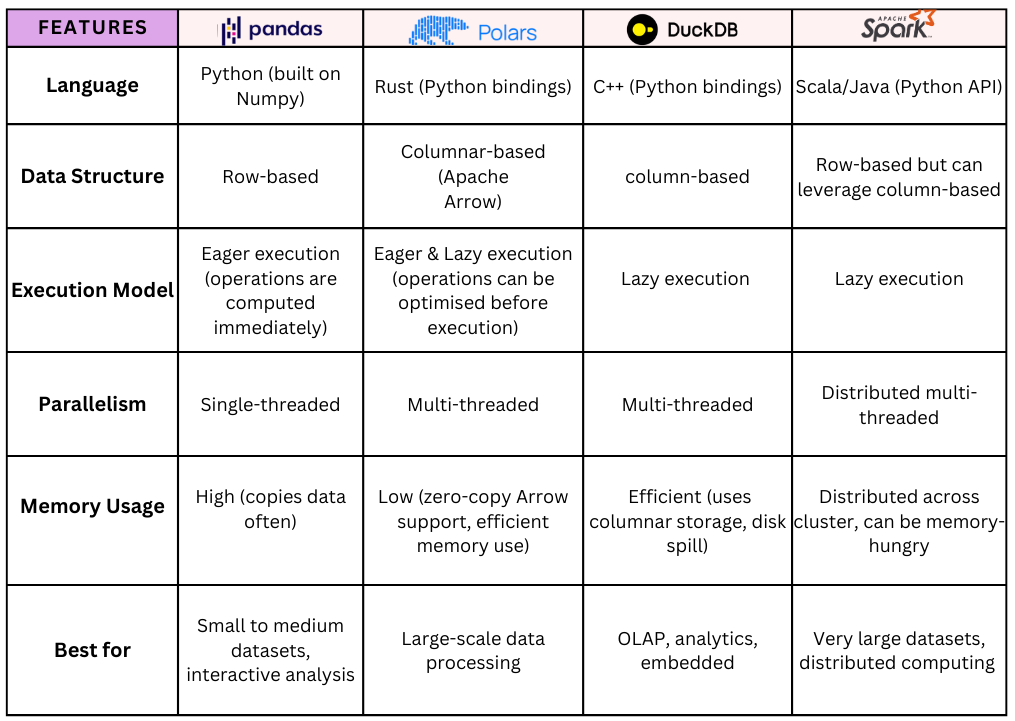
Quick Overview of Libraries
Here’s a high-level overview of the libraries:
Benchmarking and Performance Comparison
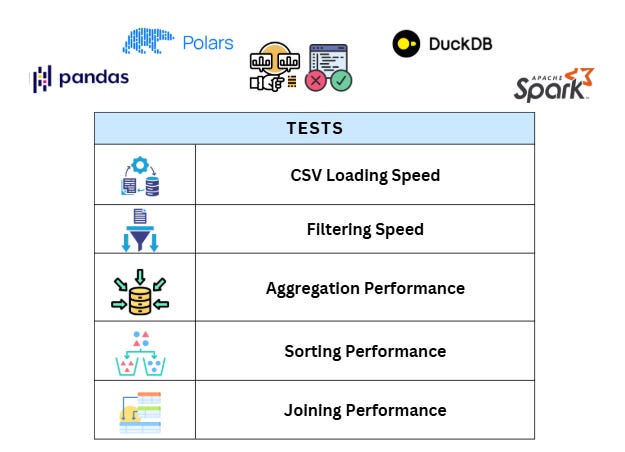
We'll run six key tests to evaluate the performance of those libraries.
CSV Loading Speed: Measure the time to read a CSV file (~5GB).
Filtering Speed: Select a subset of rows based on conditions.
Aggregation Performance: Compute group-wise sum and mean.
Sorting Performance: Sort a dataset by a column.
Joining Performance: Merge two datasets using a common key.
Note: All code was run using Python 3.13.2 on a MacBook Pro with an M2 chip and 16 GB of memory.
Benchmark Data
Total Rows: ~100 million
File Size: ~5GB
Columns:
id: Unique identifier (integer).
category: Categorical column (A/B/C/D).
value: Random float values (0-100).
timestamp: Generated datetime values.
Note: In this comparison, we run PySpark locally on a single machine. While Spark is usually deployed in distributed environments across clusters for very large datasets, here we use it on a single node to better capture performance at our dataset’s scale.
1. CSV Loading Speed
We'll measure execution time and memory usage for loading the CSV file.
Before jumping into the comparison, we also write a short function to keep track of the memory usage of the operation:

Scripts:
Pandas
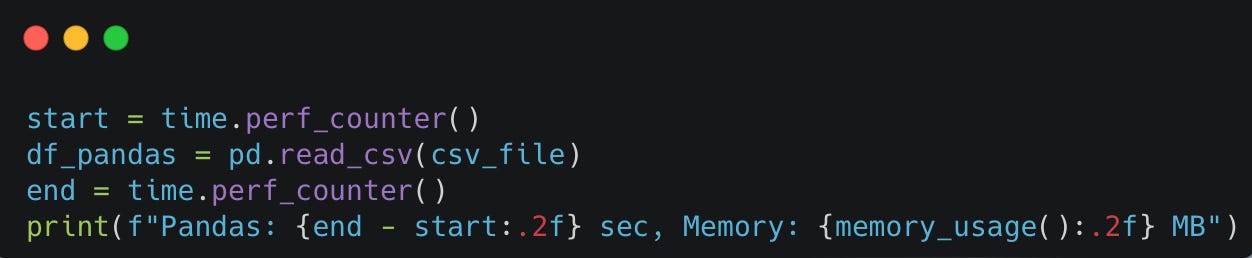
Polars

DuckDB
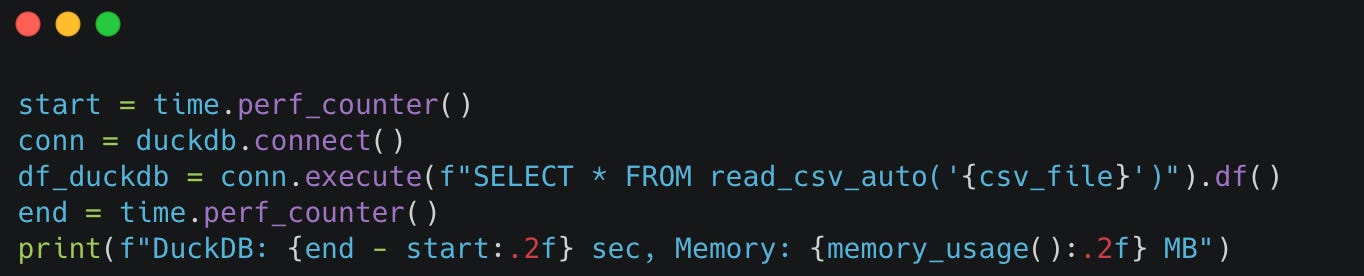
Pyspark
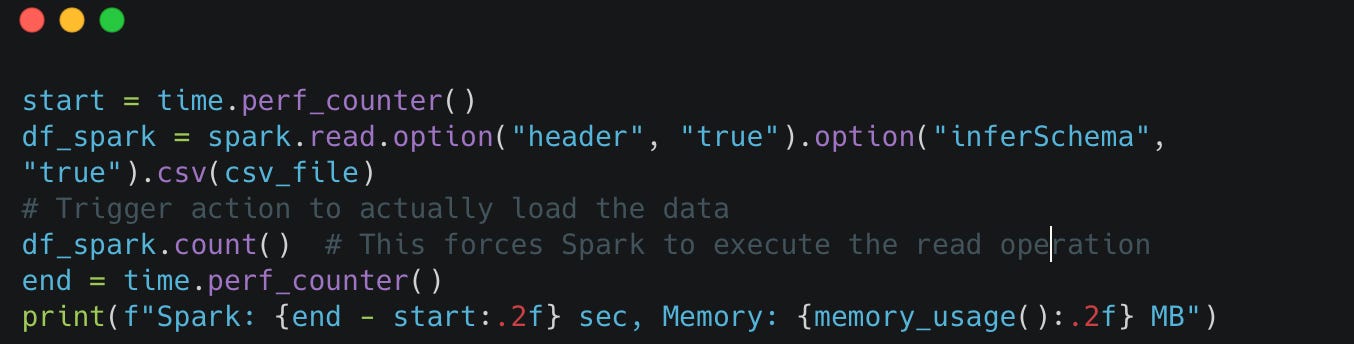
Findings:
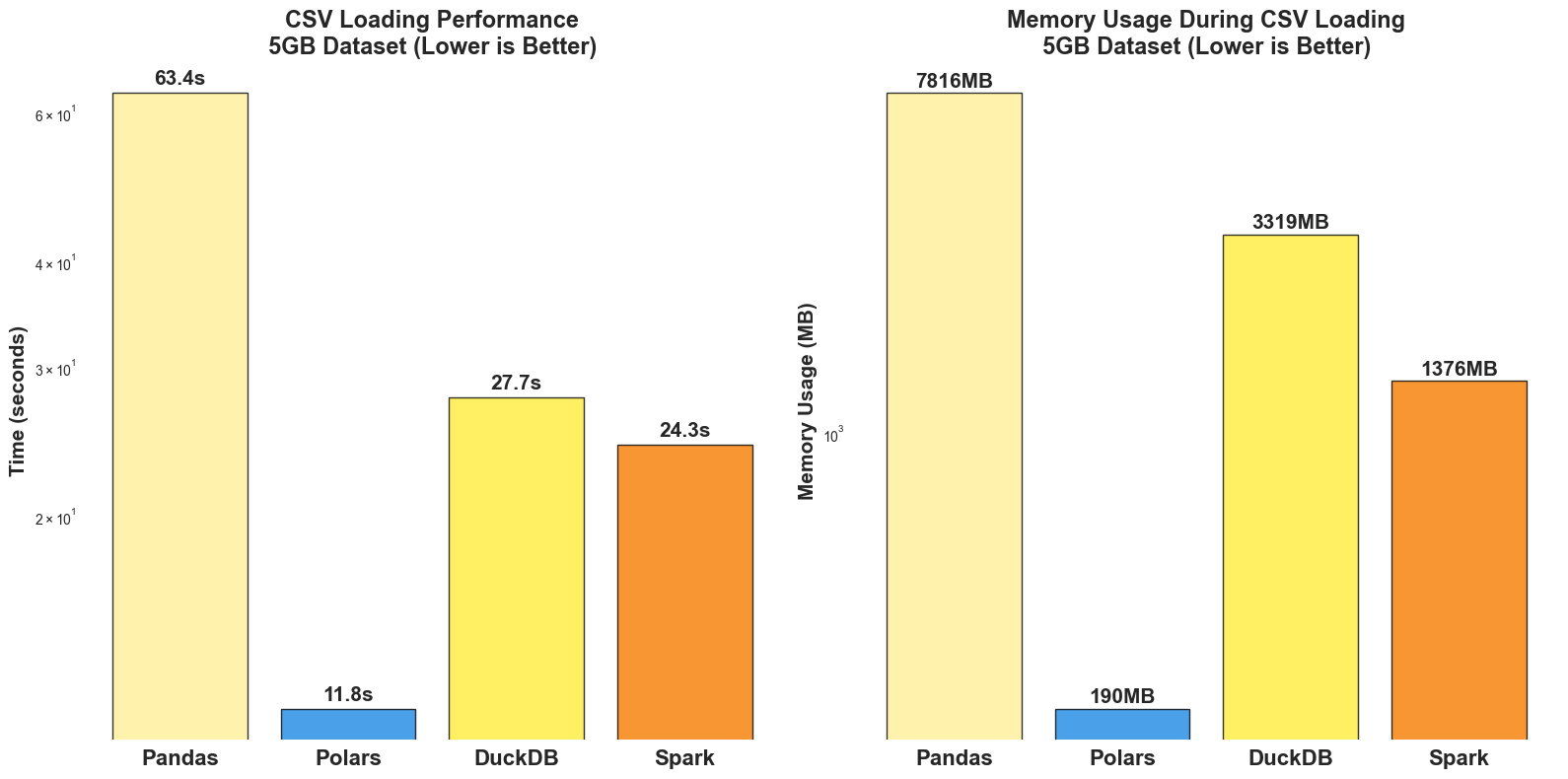
Polars is 5.4x faster than Pandas (11.83s vs 63.39s)
Polars uses 41x less memory than Pandas (190MB vs 7.8GB)
DuckDB and Spark show similar performance (~28s and ~24s)
2. Filtering Performance
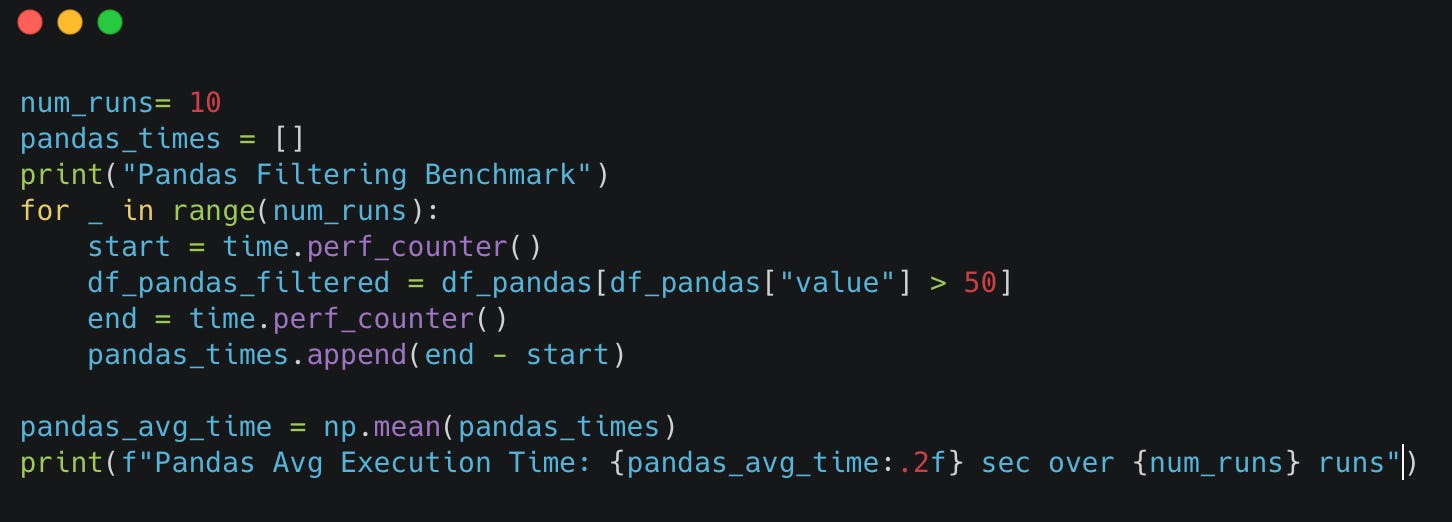
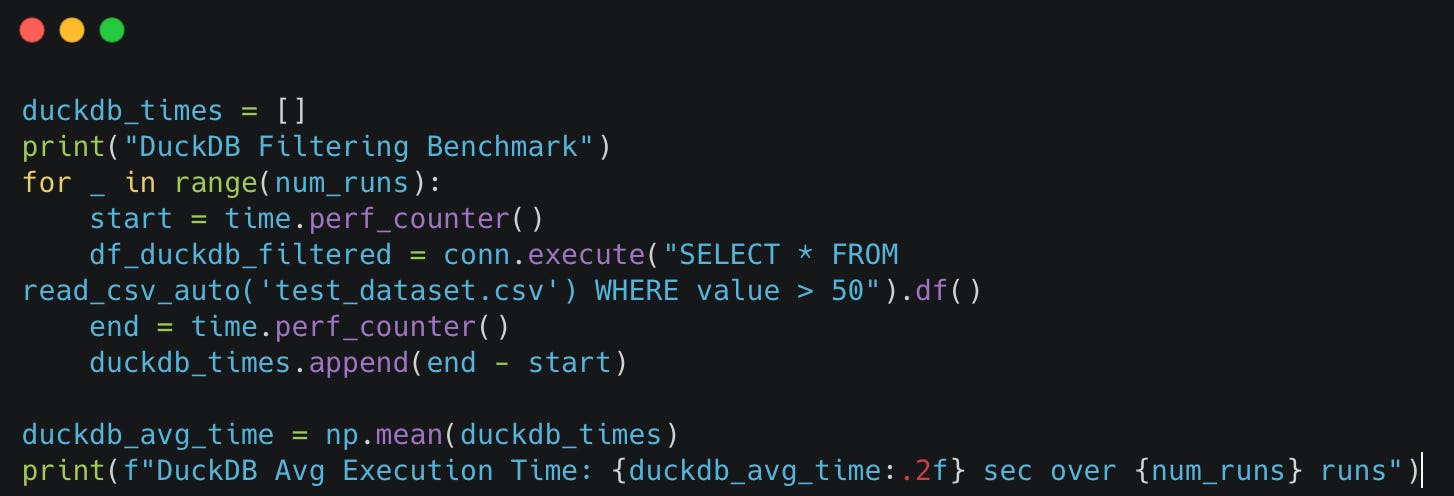
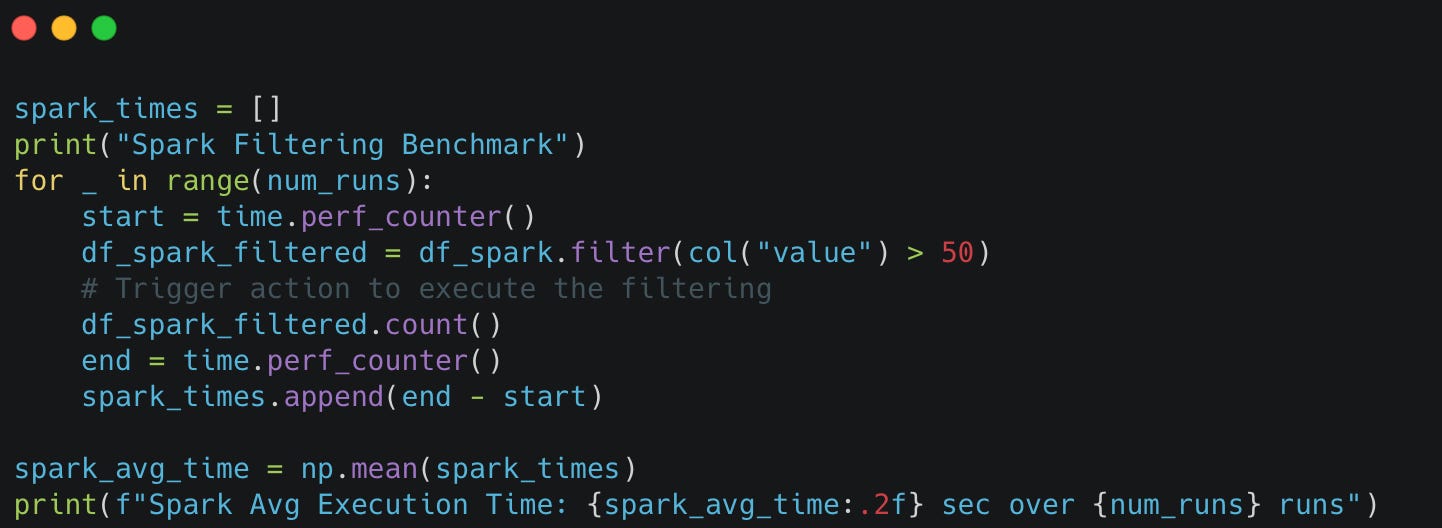
We'll measure execution time for filtering rows where the value column is greater than 50. We will run the scripts 10 times and then consider the averages to make the comparison fairer.
Pandas
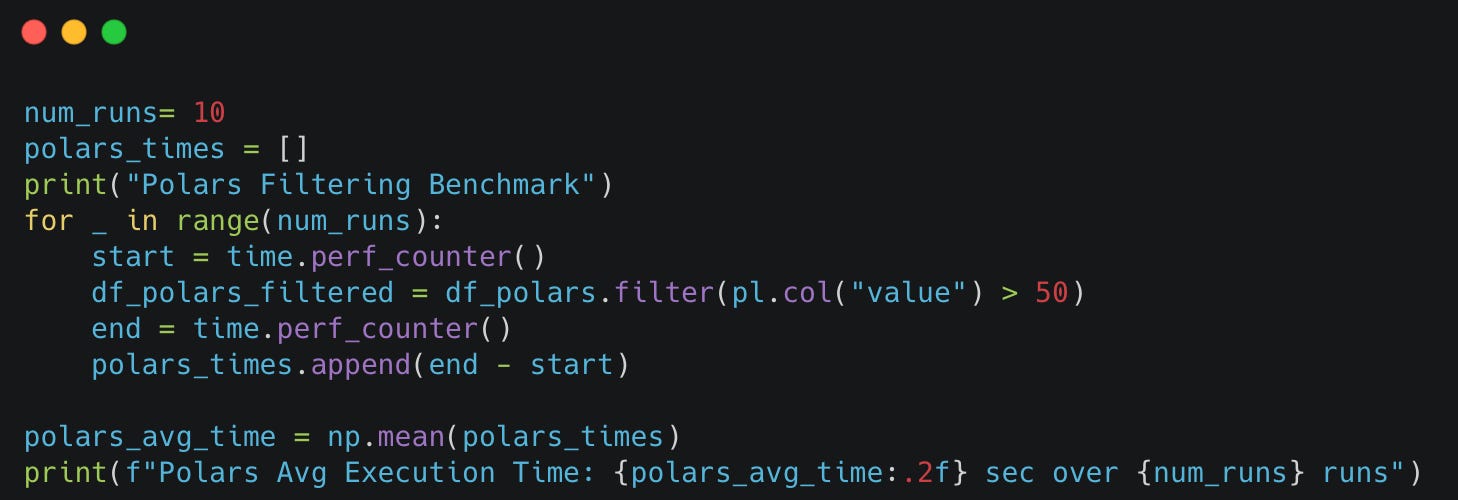
Polars
DuckDB
Pyspark
Findings:
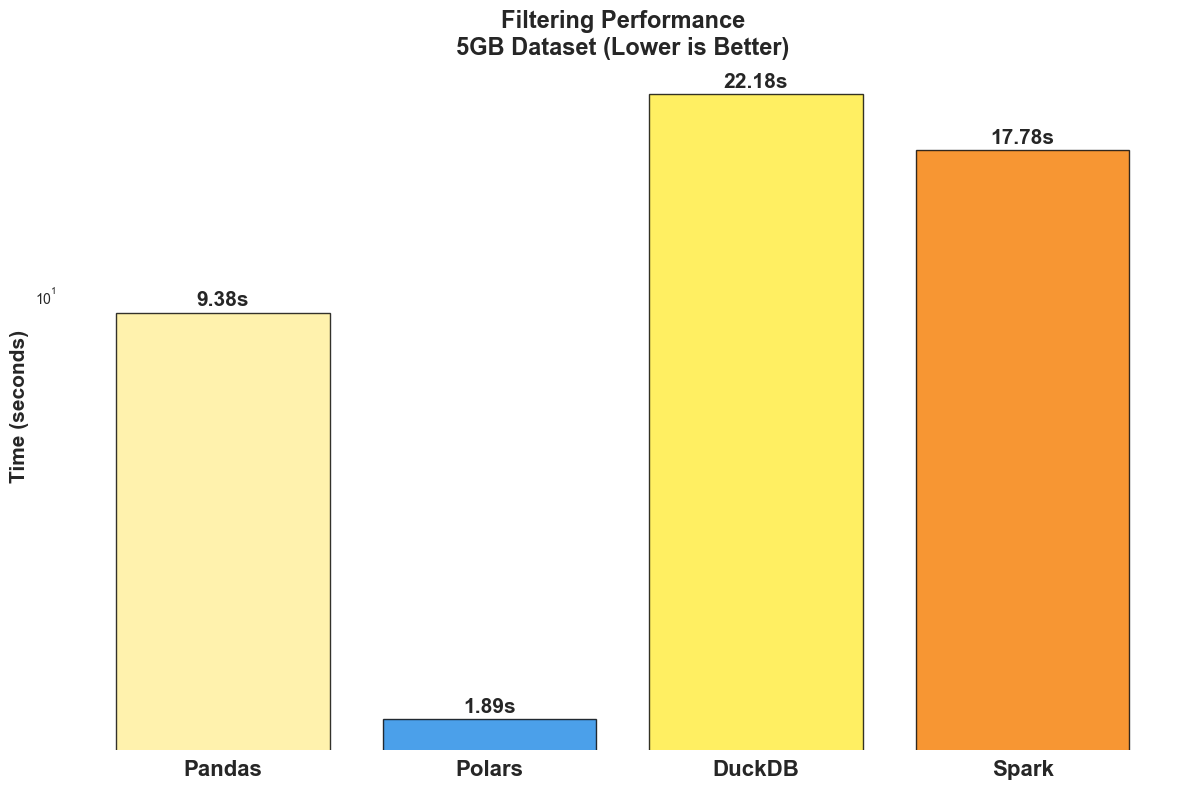
Polars dominates with 1.89 seconds (5.0x faster than Pandas).
Pandas performs well at 9.38 seconds for this operation.
DuckDB struggles with 22.18 seconds (likely due to SQL overhead).
Spark shows moderate performance at 17.78 seconds.
Note: If we frequently filter large datasets, Polars provides a massive performance boost, making it an excellent choice for fast data transformations.
filtering operations showcase Polars' vectorised processing capabilities. With a 5.0x speedup over Pandas, Polars processes 100 million rows in just 1.89 seconds. This performance advantage becomes even more significant when filtering large datasets in production data pipelines.
3. Aggregation Performance
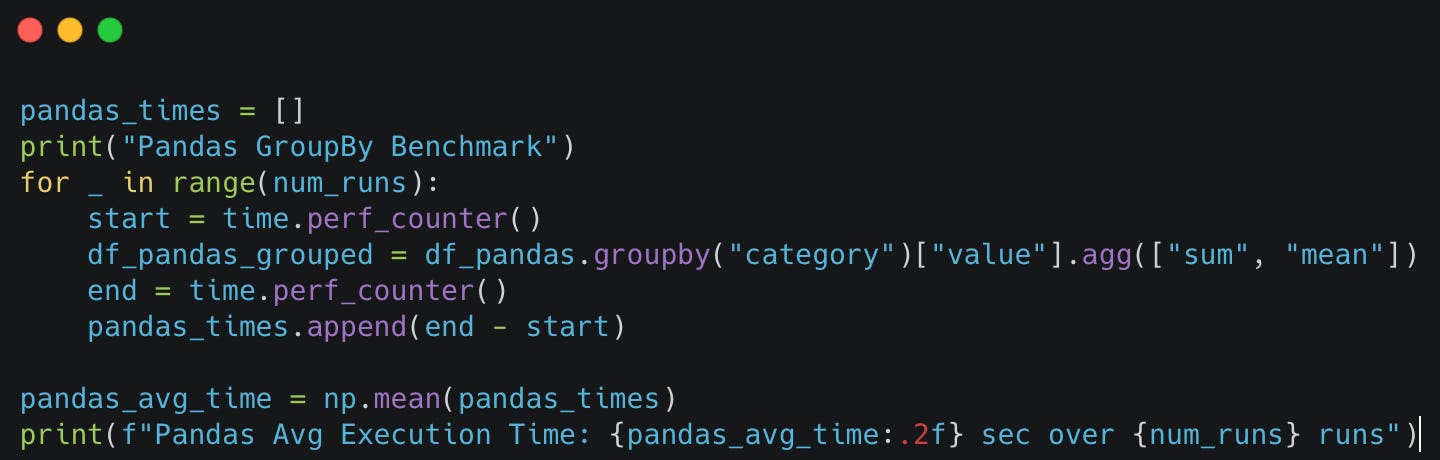
We'll measure execution time for grouping by the category column and calculating the sum and mean of the value column.
Pandas
Polars
DuckDB
Pyspark
Findings:
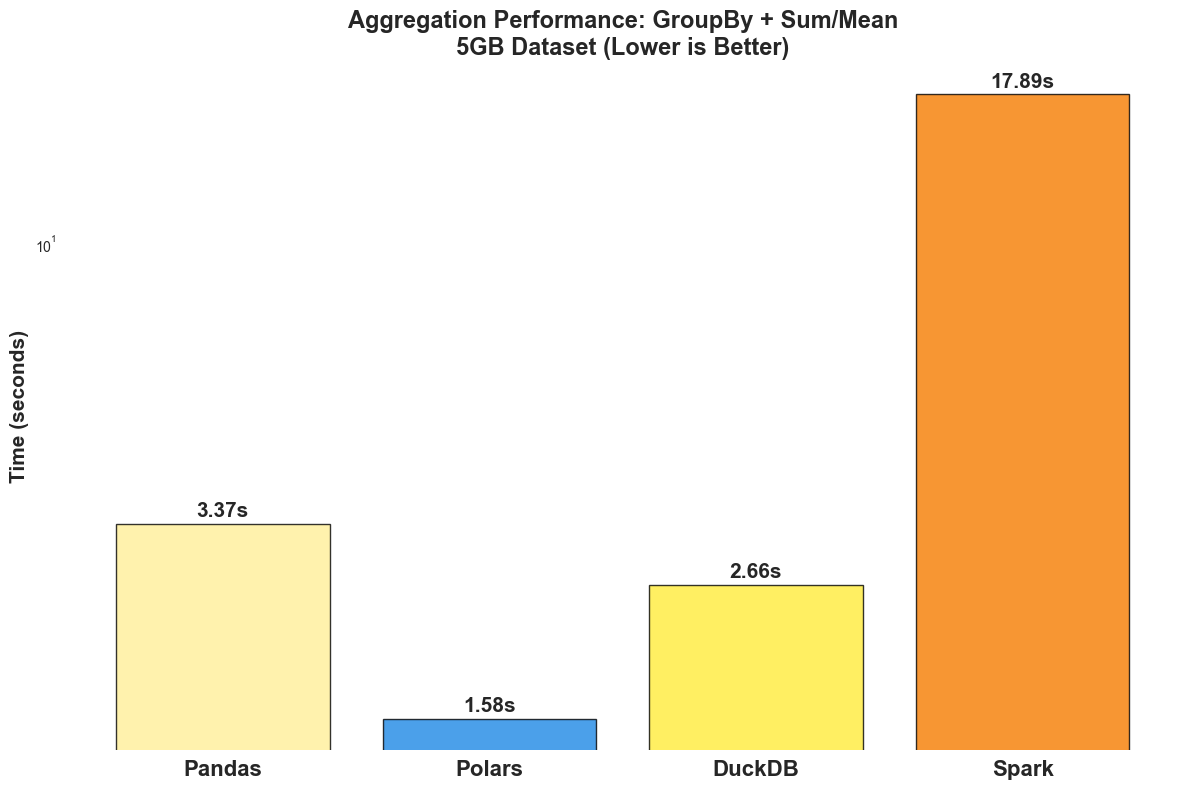
Polars wins with 1.58 seconds (2.1x faster than Pandas).
DuckDB shows strong performance at 2.66 seconds (1.3x faster than Pandas).
Pandas performs reasonably at 3.37 seconds.
Spark struggles with 17.89 seconds (overhead for this dataset size).
4. Sorting Performance
We'll measure the execution time for sorting the dataset by the value column in descending order.
Pandas
Polars
DuckDB
Pyspark
Findings:
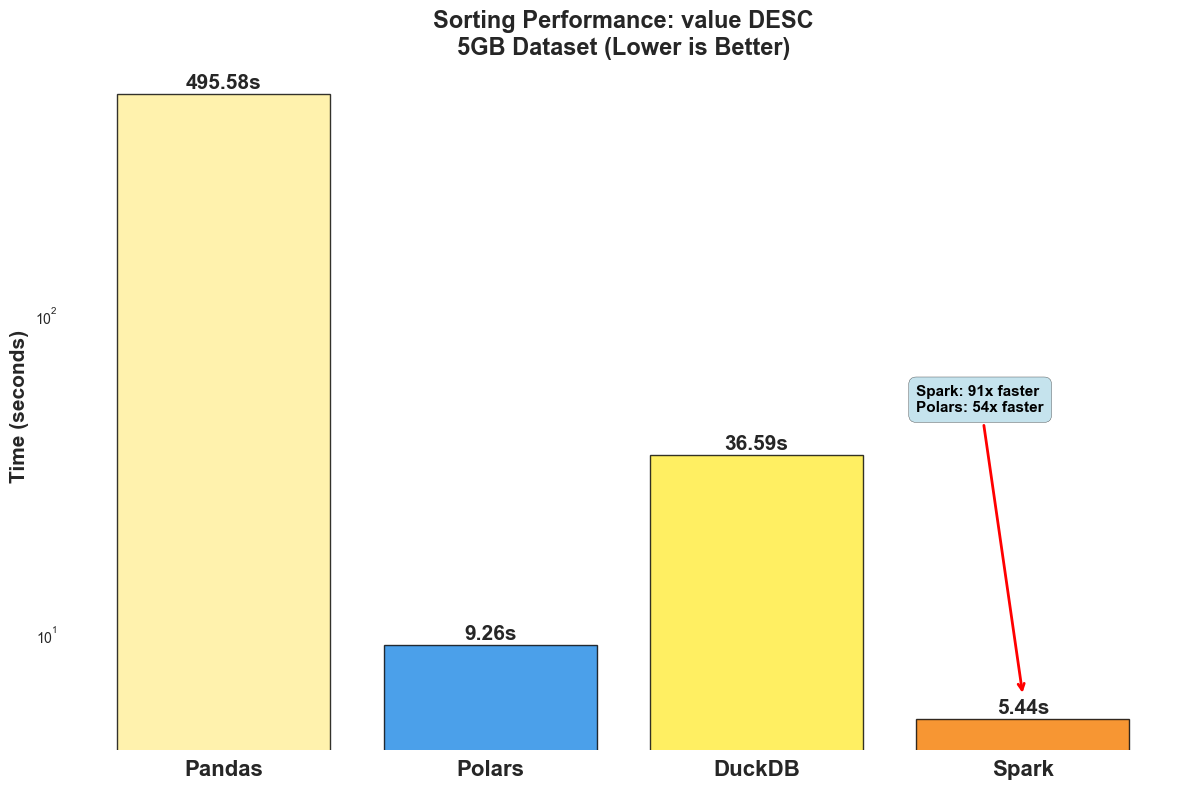
Sorting is one of the most computationally expensive operations in Pandas.
Findings
Spark dominates with 5.44 seconds (91x faster than Pandas).
Polars shows strong performance at 9.26 seconds (54x faster than Pandas!).
Pandas struggles dramatically with 495.58 seconds (single-threaded limitation).
DuckDB performs poorly at 36.59 seconds.
5. Join Performance
We will measure the execution time for joining two datasets on the id column.
Datasets:
Main dataset:
test_dataset.csv(~5GB, 100 million rows)Join dataset: A random sample of 1 million rows from the main dataset
Pandas
Polars
DuckDB
Pyspark
Findings
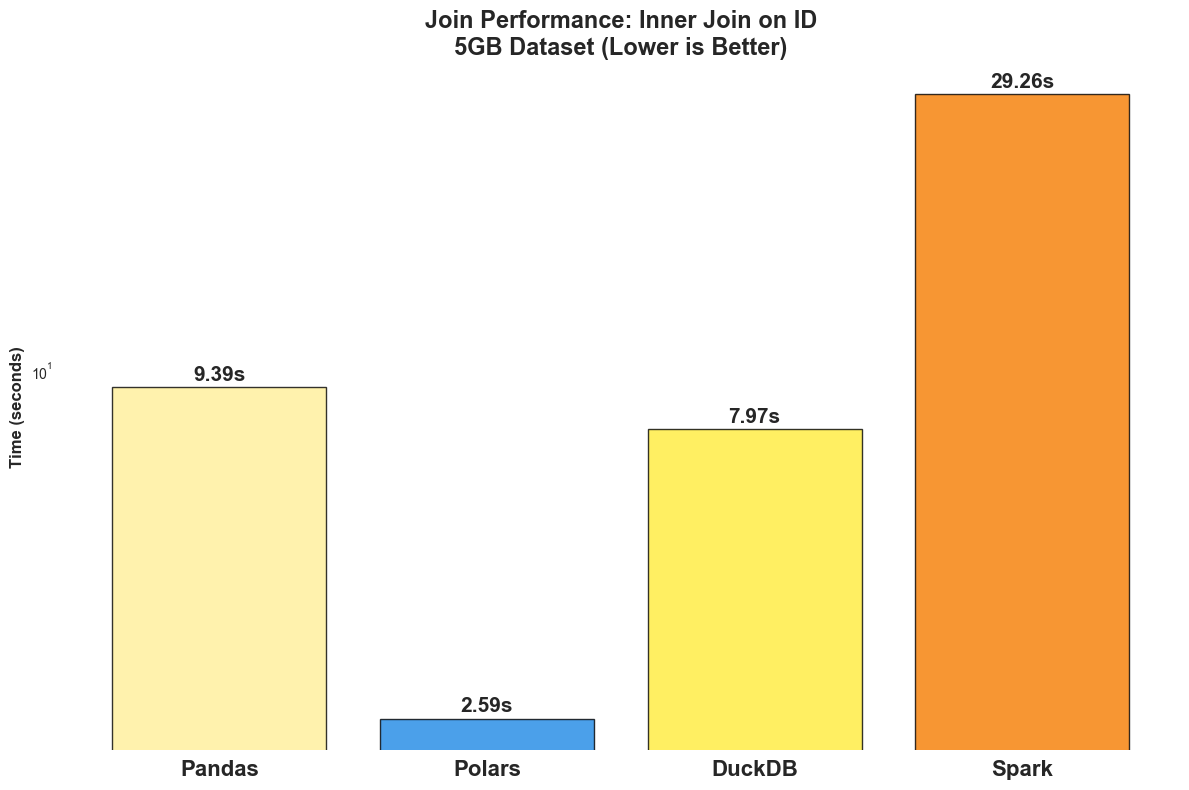
Polars dominates with 2.59 seconds (3.6x faster than Pandas).
DuckDB shows strong performance at 7.97 seconds (1.2x faster than Pandas).
Pandas performs reasonably at 9.39 seconds.
Spark struggles with 29.26 seconds (overhead for this dataset size).
Benchmark Results Summary
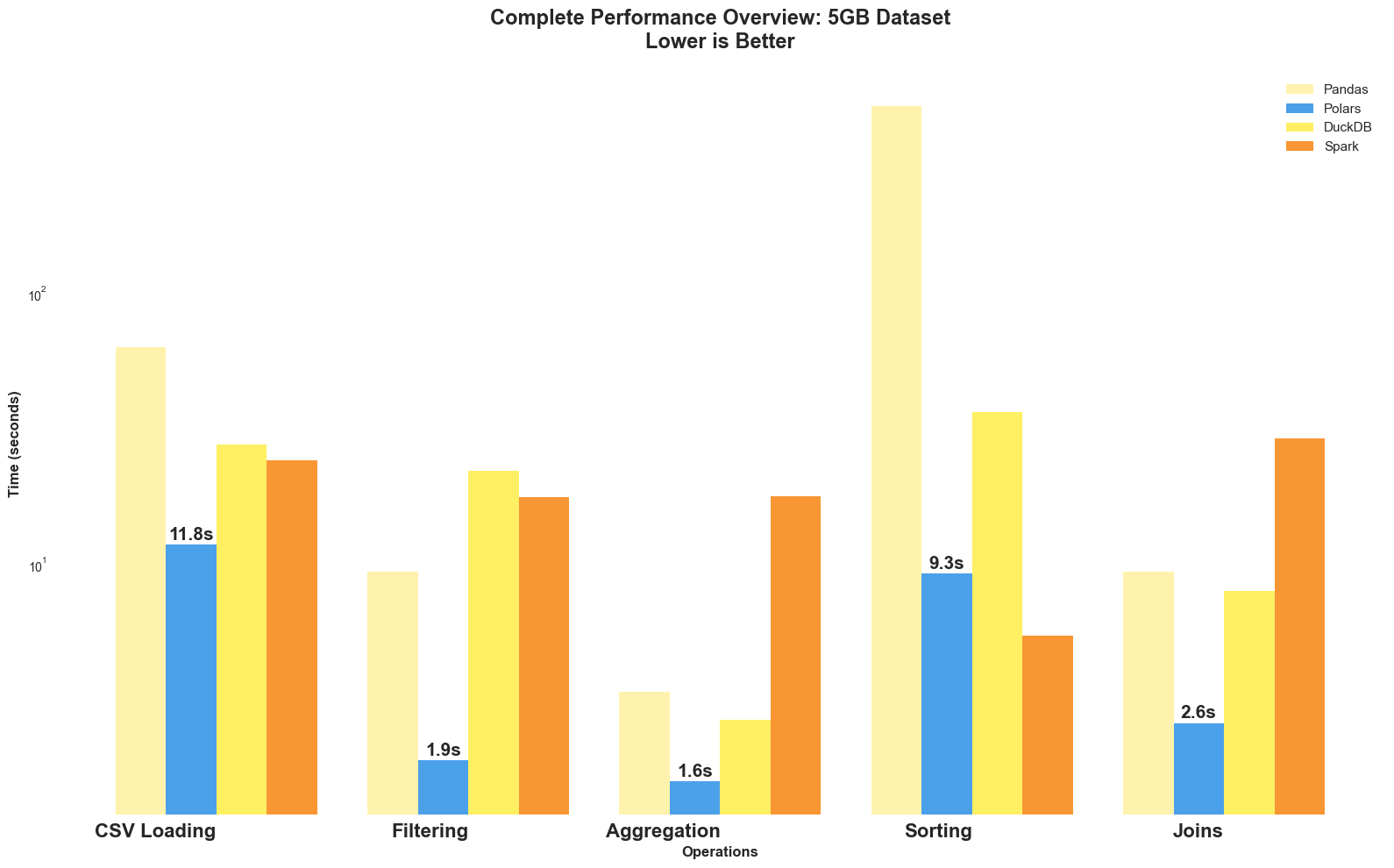
Polars was the fastest overall, loading CSVs much quicker and using far less memory than Pandas, and it was also much faster at filtering, aggregating, and joining data. Spark was the fastest at sorting, but was slower on other tasks when run locally. DuckDB did well on aggregations and joins but was slower for filtering and sorting. Pandas worked, but was the slowest because it runs on a single thread.
In short, Polars is the best for most tasks on a single machine, DuckDB is good for SQL-style operations, and Spark is best for sorting or large distributed jobs.
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!

Enjoy Pipeline to Insights? Please share it with others! Refer
3 friends and get a 1-month free subscription.
10 friends and get a 3-month free subscription.
25 friends and enjoy a 6-month free subscription.
Our way of saying thanks for helping grow the Pipeline to Insights community!
https://pandas.pydata.org/
https://pola.rs/
https://duckdb.org/
https://spark.apache.org/docs/latest/api/python/index.html