


Storage Fundamentals For Data Engineers
Why organised and durable storage is the cornerstone of Data Engineering?

Storage is at the heart of the Data Engineering lifecycle. It is fundamental to every stage of Data Engineering: ingestion, transformation, and serving. Data is stored multiple times throughout its lifecycle, ensuring it’s accessible for later processing whenever needed.
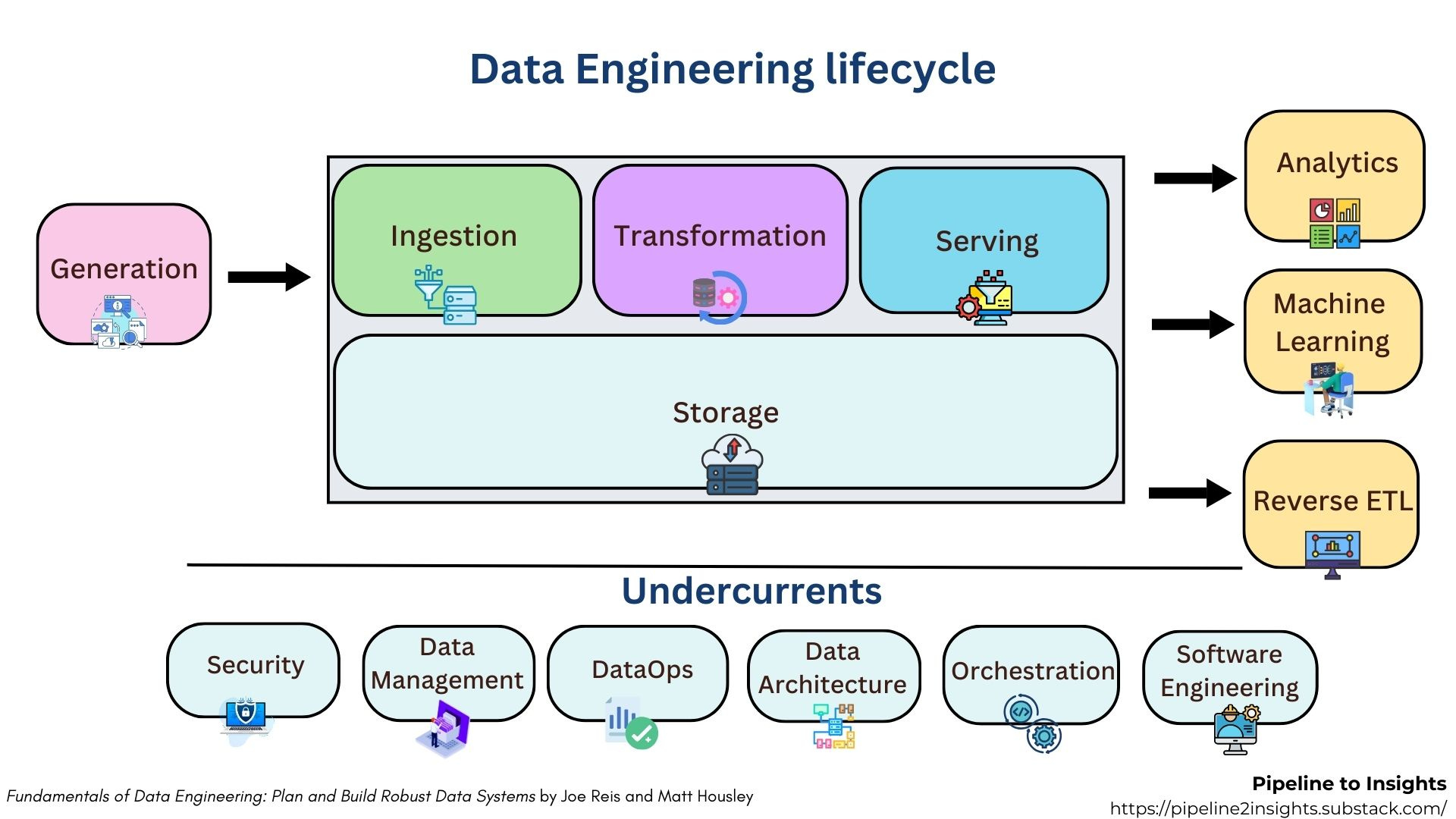
Selecting the right storage solution depends on understanding the data's use case and future retrieval needs, which is crucial for building an effective data architecture.
As a Data Engineer, you’ll often work at a high level, focusing on broader architectures rather than the specifics of data movement between storage systems. However, a deep understanding of the underlying storage solutions is crucial for effectiveness. Failing to grasp these fundamentals can lead to performance bottlenecks and inflated costs.
For example, relying on direct row inserts for data ingestion can lead to potential performance bottlenecks and increased costs, resulting in wasted time and budget.

In this blog post, we’ll be diving into the hierarchy of data storage from the ground up, drawing inspiration from Fundamentals of Data Engineering by
and Matt Housley, as well as insights from the Data Engineering professionals Course on Coursera/deeplearning.io.The Storage Hierarchy

1. Raw Hardware Ingredients:
Solid-State Storage(SSD): High-speed storage using flash memory. It offers faster performance, greater reliability, and energy efficiency compared to traditional hard drives.
Disk: Physical storage like hard drives (HDDs) or solid-state drives (SSDs) store data long-term. Traditional hard drives are slower but generally 2-3 times cheaper than solid-state storage.
RAM: High-speed, temporary memory used to run applications. Data is lost when the power is off, and it’s around 30-50 times more expensive than solid-state storage.
Networking: Enables data transfer between systems. Critical for cloud environments and distributed storage, ensuring seamless communication and efficient resource sharing.
Serialisation: Transforms data into a storable or transmittable format. Essential for efficient data storage, transmission, and interoperability between systems.

2. Storage Systems (Databases and Object Storage):
Databases: Systems designed to organise and manage structured data for quick querying. This can involve SQL (relational) or NoSQL (non-relational) databases.
Object Storage: Primarily used to store unstructured data, such as files or backups, in the cloud (e.g., AWS S3).

3. Storage Abstractions (Data Warehouses, Data Lakes, Lakehouses):
Data Warehouses: Optimised for analysing structured data.
Data Lakes: Used to store vast amounts of raw, unstructured data in its original format.
Lakehouses: Combines data lakes and warehouses, offering both raw storage and analytics.
With the storage abstraction tools, you’ll focus on configuring parameters to meet your needs for latency, scalability, and cost, rather than managing underlying storage details.
Who are you working with?
As a data engineer working with storage, you will collaborate with people who own your IT infrastructure including DevOps, security, and cloud architects.
Determining whether Data Engineers can independently deploy infrastructure or require other teams to manage these changes is critical. This ensures streamlined, efficient collaboration and minimises delays.
Your responsibilities will depend on the organisation’s level of data maturity:
Early-Stage Organisations: You'll likely manage the entire data storage system and workflows, taking ownership of end-to-end processes.
Mature Organisations: Your role may focus on overseeing specific components, and collaborating with teams dedicated to data ingestion, and transformation.
For more details about Data Maturity, check out our previous post.

Ensuring storage systems are secure, maintain high data quality, offer sufficient capacity, and deliver efficient performance during queries and transformations is crucial to meeting the needs of downstream users.
What type of storage solution should you use?

Choosing the right storage solution depends on factors like your use cases, the amount of data, how often it's ingested, and the format and size of the data. There is no one-size-fits-all solution; each storage option has unique strengths and weaknesses. With numerous technologies available, identifying the best fit for your data setup can be complex.

Conclusion
Understanding the storage hierarchy is crucial for data engineers who aim to optimise performance and manage costs effectively. From foundational hardware like SSDs and RAM to advanced concepts like data warehouses and lakehouses, mastering these elements can significantly impact your projects. This knowledge empowers you to make informed decisions, avoid performance bottlenecks, and design scalable, efficient systems that align with your organisation's needs and future growth.
In the upcoming weeks, we will share our learning about the Undercurrents of the Data Engineering Lifecycle. So Stay tuned 🙂
If you found this post valuable and want to stay updated on the latest insights in data engineering, consider subscribing to our newsletter.
You might also enjoy these posts about the Data Engineering Lifecycle:
Data Ingestion: Batch vs. Stream, Which Strategy is Right for You? 🙂

Source systems and data ingestion represent the biggest bottlenecks in the data engineering life cycle.
The Crucial Midpoint of Data Engineering: Data Transformation

The transformation stage is where Data Engineers become chefs, cleaning, chopping, and blending until everything is just right. The raw data turns into insights-ready information, prepped and plated for analytical…
From Data to Decisions: A guide to serving insights for maximum impact

Now, we’re at the exciting final leg, serving that refined data so analysts, data scientists, and ML engineers can work their magic.
If you'd like to learn more about Data Engineering Fundamentals, check the following:
[Fundamentals of Data Engineering Book] by
[Data Engineering Professional Course] on Coursera/Deeplearning.ai.
Join the Conversation!
What are your experiences with the storage hierarchy in your data engineering projects? We'd love to hear your thoughts and insights. Share your experiences in the comments below and join the discussion!
Great insight