

Think of SQL optimisation as diving into the depths of the ocean. If you dive with the wrong equipment or an uncalibrated oxygen tank, you’ll expend unnecessary energy and risk cutting your exploration short. Choosing the right file formats is like selecting a calm, clear diving spot, while understanding your query ensures you navigate smoothly. A well-optimised query, much like a perfectly executed dive, lets you explore efficiently, conserve resources, and surface with remarkable discoveries and less effort. 🤿🌊

Using various practical examples, we highlighted how columnar storage, pre-sorting data, and optimal data formats can significantly enhance query performance. Each example focused on showcasing DuckDB's capabilities in modern analytical workloads.
Day 43: Primary Key vs. No Primary Key
Goal: To test the impact of primary keys in selective and aggregation tasks.

Details:

Day 44: BIGINT Joins vs. VARCHAR Joins
Goal: To test the performance of BIGINT and VARCHAR Joins.

Details:

Day 45: Indexes in Filtering and Aggregation
Goal: To test the performance effect of indexing on filtering and aggregation tasks.

Details:

Day 46: Columnar Vectorisation
Goal: To test the impact of Vectorised Execution in DuckDB.

Details:

Day 47: ORDER BY RANDOM() vs. TABLESAMPLE
Goal: To test the performance of specialised functions in row sampling.

Details:

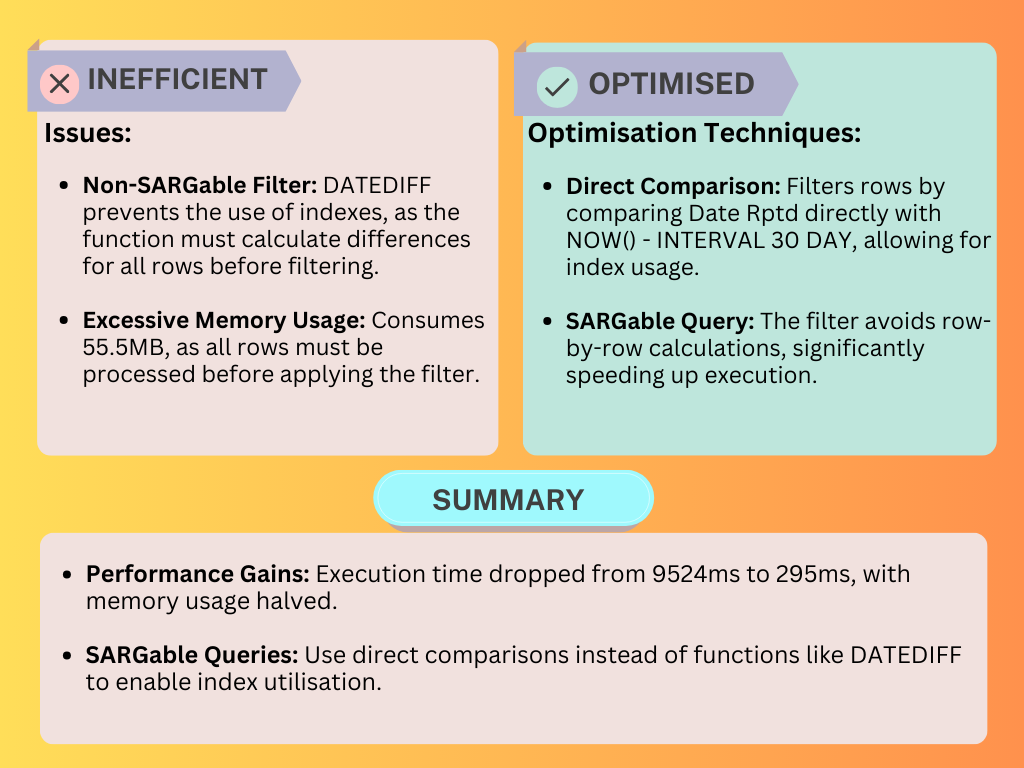
Day 48: DATEDIFF vs. Direct Comparison
Goal: To test the performance of different timestamp filtering approaches in DuckDB.

Details:
Day 49: JOIN Before vs. After Filters
Goal: To test the performance difference when joining before and after filtering.

Details:

Conclusion
In this seventh week of our "100 Days of SQL Optimisation" journey, we continued exploring DuckDB's performance and focused on optimisation techniques for real-world scenarios:
Primary Keys and Indexing: Highlighted the impact of primary keys and indexes on filtering and aggregation performance, emphasising their role in query efficiency.
Data Sampling: Demonstrated how specialised sampling methods like
TABLESAMPLEoutperform generic approaches likeORDER BY RANDOM()in terms of execution time and resource usage.Efficient Filtering and Joins: Showed the importance of applying filters before join operations to reduce data volume and improve query plans.
SARGable Queries: Replaced non-SARGable operations like
DATEDIFFwith direct comparisons to enable index utilisation and reduce memory usage.Columnar Execution: Leveraged vectorised execution and intermediate filtering to improve query performance by reducing redundant computations.
Optimised Data Types: Compared
BIGINTandVARCHARfor joins, showcasing how choosing optimal data types can significantly enhance join performance.
These optimisations underline the importance of leveraging efficient data structures, SARGable queries, and pre-processing techniques to achieve faster and cleaner SQL operations in DuckDB.
If you're enjoying this journey, stay with us for the next week as we explore even more powerful SQL techniques. Subscribe to keep learning how to optimise your queries and make your SQL skills sharper every day!
If you missed the Week 6 recap, you can catch up by checking it out here:

If you’re interested in using DuckDB, the dlt library is a fantastic tool for effortlessly ingesting datasets into DuckDB. Check out our post to learn more about how dlt simplifies data importing from various sources.
