

Think of SQL optimisation as climbing a towering mountain. If you start with the wrong gear or an unsteady pace, you’ll exhaust yourself before reaching the summit. Choosing the right file formats is like mapping out the easiest trail while understanding your query ensures you ascend with precision and purpose. A well-optimised query, much like a perfectly planned climb, allows you to scale heights efficiently, conserve energy, and enjoy the breathtaking views at the top with minimal effort. 🧗♂️⛰️

This week, we explored DuckDB's capabilities, showcasing its performance across various scenarios. Using real-world datasets and practical examples, we demonstrated how techniques such as leveraging columnar storage, optimising key-value mappings, using efficient aggregate functions, and employing window functions can enhance query performance.
Day 50: STRING_AGG() vs. LIST()
Goal: To test the performance of STRING_AGG() and LIST() functions.

Details:

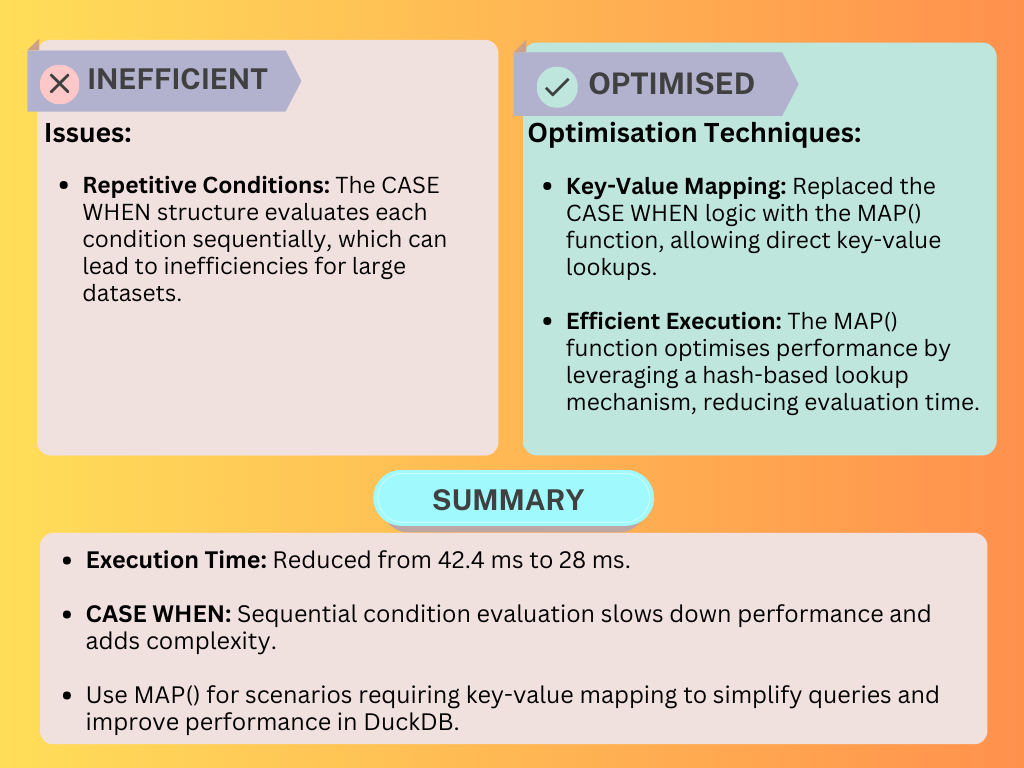
Day 51: CASE WHEN vs. MAP()
Goal: To test the performance of key-value mapping in DuckDB using MAP()

Details:
Day 52: Window Functions for Cumulative Totals
Goal: To compare window functions and subqueries for cumulative calculations.

Details:

Day 53: Unpivoting using UNION ALL vs. UNPIVOT()
Goal: To transform wide data into a long format.

Details:

Day 54: Effect of Unnecessary Sorting
Goal: To find the average victim age for each area in sorted order.

Details:

Day 55: Impact of Indexing in Column-Oriented Database
Goal: To retrieve data for a specific area.

Details:

Day 56: Correlated Subquery vs. CTE
Goal: To retrieve all crimes that occurred in areas where vehicles were reported stolen.

Details:

Conclusion
In this week 8 of our "100 Days of SQL Optimisation" journey, we continued to explore DuckDB's strengths by focusing on query optimisations tailored to modern analytical workloads:
Key-Value Mappings with MAP(): Replaced
CASE WHENstatements with the efficientMAP()function to streamline key-value mappings.Window Functions for Cumulative Calculations: Demonstrated how window functions simplify and speed up cumulative calculations compared to subqueries.
Unpivoting Data: Leveraged the
UNPIVOT()function to efficiently transform wide datasets into a long format, eliminating the need for repetitiveUNION ALLqueries.Avoiding Unnecessary Sorting: Highlighted the impact of removing redundant sorting operations, improving both execution time and resource utilisation.
Indexing in Column-Oriented Databases: Showcased how indexing significantly accelerates data retrieval by reducing scan times and memory usage.
Replacing Correlated Subqueries with CTEs: Used Common Table Expressions (CTEs) to replace inefficient correlated subqueries, improving clarity and execution performance.
These examples illustrate DuckDB’s ability to handle complex analytical tasks efficiently through optimised storage, advanced functions, and query techniques.
If you're excited to learn more about SQL optimisations, follow our 100-day journey. Subscribe to receive daily insights and make your SQL queries more powerful and efficient!
If you missed the Week 7 recap, you can catch up by checking it out here:

If you're looking to enhance your data modelling skills or prepare for a data engineering interview, check out:

We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Have you used DuckDB? Where did you use it, and what has your experience been like? We would love for you to share your insights so that we can learn from you.