


Zero-ETL: What It Is and What It Isn't
How Zero-ETL differs from ETL and ELT and when to use it

In the day-to-day life of a Data Engineer, selecting the right concepts and design patterns is critical to meeting diverse business requirements. One such emerging concept is Zero-ETL, which promises to simplify data integration and deliver real-time insights. In this post, we will explore Zero-ETL by covering the following points:
What is zero-ETL?
How does it differ from ETL and ELT?
Why is it not just an EL process?
When to consider using Zero-ETL?
1. What is Zero-ETL?
Zero-ETL is a concept in data integration that eliminates the traditional steps of Extract, Transform, and Load (ETL). Zero-ETL allows data to flow seamlessly between systems, enabling real-time or near-real-time analytics without the need for complex pipelines.
This approach became widely recognised when AWS introduced the term during their 2022 re:Invent conference, highlighting the integration of Amazon Aurora with Amazon Redshift.
Zero-ETL uses advanced technologies like database replication, federated querying, data streaming, and in-place analytics to enable organisations to:
Query and analyse data directly in its original format.
Minimise latency and eliminate intermediate steps.
Reduce the operational complexity of maintaining traditional ETL pipelines.
Core Features of Zero-ETL
Seamless Integration: Direct data movement between systems without separate pipelines.
Real-Time Insights: Near-instant data availability for analytics and decision-making.
Simplified Architecture: Reduced complexity compared to traditional ETL or ELT processes.
Cross-Silo Queries: Ability to query across data silos without data movement.
2. How is Zero-ETL Different from ETL and ELT?
ETL (Extract, Transform, Load): Data is extracted from a source, transformed to match the requirements of the target system, and then loaded into a destination, such as a data warehouse. This method is ideal for complex transformations but can introduce high latency.

ELT (Extract, Load, Transform): Data is extracted and loaded directly into the destination system. Transformations are performed within the target system using its computational power. This approach is faster than ETL but relies on the target system’s capabilities.
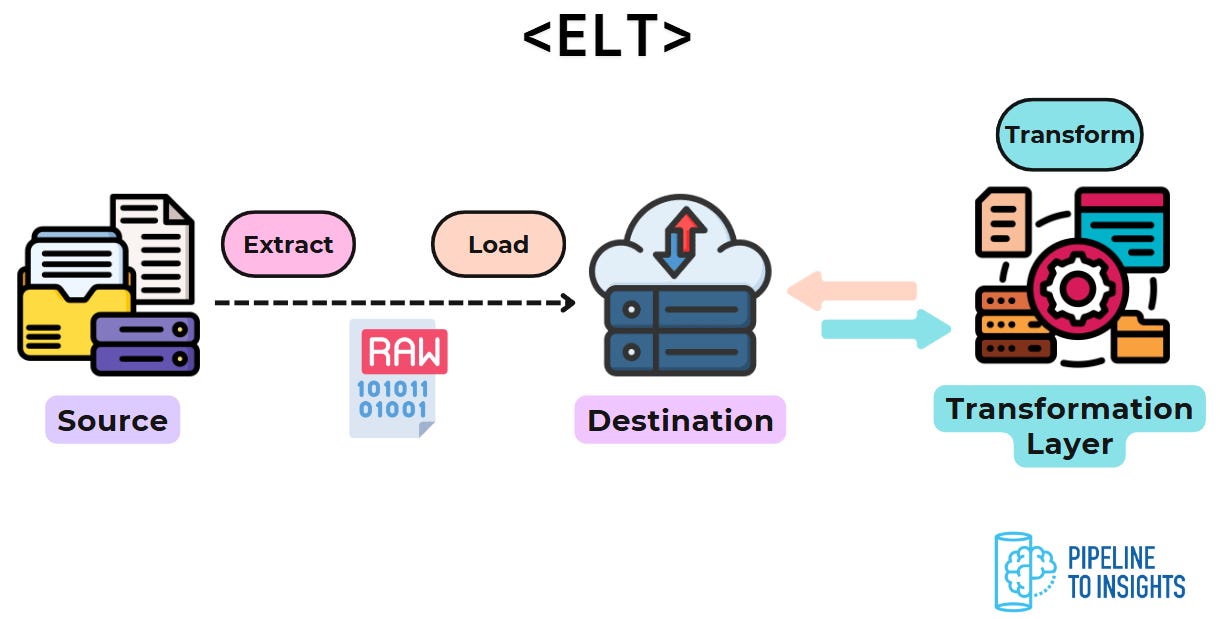
Note: For more details about ETL, ELT, and more common pipeline design patterns, check out:

Advantages vs. Disadvantages of ETL, ELT, and Zero-ETL

Let’s assume a scenario: A retail company wants to analyse customer purchasing patterns across multiple stores, with near real-time reporting (e.g., updates every 5 minutes, hourly, or as transactions occur) to ensure timely insights.
Using ETL:
Extract data from store databases at regular intervals.
Transform the data (e.g., clean, aggregate, and format) in a separate ETL tool.
Load the transformed data into a data warehouse for analysis.
Outcome: Analysis is delayed by the batch processing time, making it unsuitable for real-time needs.
Using ELT:
Extract data from the stores and load it into the data warehouse/Data lakehouse.
Perform transformations (e.g., aggregations, filtering) using the data warehouse’s processing capabilities.
Outcome: Faster than ETL but still involves latency due to batch loading and transformation times.
Using Zero-ETL:
Leverage direct integrations between store systems and analytical platforms.
Query and analyse the data in its original format without moving or transforming it beforehand.
Outcome: Near-real-time insights with minimal latency, enabling faster decision-making.
By understanding the trade-offs, data engineers can choose the right approach for their specific use cases, with Zero-ETL being advantageous for real-time analytics and operational simplicity.
3. Why is Zero-ETL Not Simply EL?

At first glance, Zero-ETL might seem like it is just EL (Extract and Load), as it bypasses the explicit transformation stage found in traditional ETL. However, some features of Zero-ETL make some difference.
Inherent Transformations: While Zero-ETL eliminates explicit transformation steps, transformations still occur inherently during query execution or data processing. Technologies such as schema-on-read, federated querying, and in-place analytics allow systems to dynamically adapt the data for analysis.
Real-Time Data Flow: Unlike EL, which typically involves periodic or batch data extraction and loading, Zero-ETL facilitates continuous data flow. Technologies like Change Data Capture (CDC) and streaming pipelines (e.g., Amazon Kinesis, Apache Kafka) ensure that changes in the source systems are replicated to the target in real time, enabling low-latency insights.
Direct Data Integration: Zero-ETL systems leverage direct integration services provided by cloud platforms, such as the integration between Amazon Aurora and Amazon Redshift. These services automate replication and make data query-ready without requiring manual extraction or intermediate loading.
Handling Semi-Structured and Unstructured Data: Zero-ETL architectures support schema-on-read capabilities, which enable flexible handling of unstructured or semi-structured data formats like JSON and XML. This approach avoids the rigid schema definitions required in EL and provides greater adaptability for modern data needs.
The term “Zero-ETL” has been a topic of debate, as it highlights the absence of explicit ETL stages. Some argue that it aligns more closely with a “Zero-EL” concept, given that transformations are often implicit rather than explicit. However, the names themselves hold little significance and are likely to evolve over time, sparking new debates while the core concepts remain unchanged. Whether it’s called Zero-ETL, Zero-EL, or EL 2.0, the focus should be on the underlying idea: enabling continuous data flow through technologies like CDC and streaming.

4. When To Consider Zero-ETL?
Zero-ETL is not a universal solution but offers value for specific scenarios and organisations. Its suitability depends on business needs, real-time data requirements, and infrastructure. Here are some key use cases:
Real-Time Analytics
Scenario: Businesses needing instant insights, such as customer behaviour tracking, vehicle traffic patterns, or financial transactions.
Application: Zero-ETL enables real-time access to newly generated data by eliminating batch processes, allowing teams to make data-driven decisions instantly.
Benefit: Improves responsiveness and operational efficiency.
Instant Data Replication
Scenario: Companies with transactional databases need rapid replication to analytical platforms.
Application: Using Zero-ETL with Change Data Capture (CDC) techniques, data is continuously replicated from transactional databases to data warehouses. Data analysts can retrieve and analyse the replicated data without delay.
Benefit: Reduces complexity and latency in data replication.
Streaming Data Ingestion
Scenario: Organisations relying on real-time data streams from IoT devices, applications, or logs.
Application: Zero-ETL integrates streaming platforms (e.g., Apache Kafka, Amazon Kinesis) directly with analytical systems, making data immediately available for analysis without intermediate storage.
Benefit: Ensures low-latency updates and eliminates the need for staging.
Machine Learning and AI
Scenario: Applications requiring up-to-date data for continuous machine learning model training.
Application: Zero-ETL supports real-time streaming and immediate data availability, enabling rapid updates to AI models, improving their accuracy and relevance.
Benefit: Enhances AI and ML performance with timely data.
Cost-Conscious Organisations with Simpler Transformation Needs
Scenario: Startups or small-to-medium enterprises with limited budgets and resources.
Application: Zero-ETL’s simplicity and reduced infrastructure costs make it a viable choice for organisations prioritising speed and cost-effectiveness over complex transformations.
Benefit: Simplifies implementation and reduces operational expenses.
Considerations for Adoption
While Zero-ETL offers speed, simplicity, and real-time capabilities, it comes with limitations:
Complex Transformations: Organisations requiring advanced transformations may find Zero-ETL insufficient.
Data Governance: Reliance on underlying systems for governance can challenge data accuracy and reliability.
System Ecosystem: Zero-ETL works best within tightly integrated ecosystems and may not suit diverse, decentralised environments.
Conclusion
As Zero-ETL continues to evolve, its ability to simplify data integration and provide real-time insights makes it a powerful tool for organisations with specific needs. However, it is crucial to evaluate its limitations and fit within your data ecosystem.
We Value Your Feedback
What are your thoughts on Zero-ETL? Have you implemented it in your workflows, or are you considering its potential for your organisation?
Further Reading
If you want to dive deeper into Zero-ETL we suggest the below articles since they provide different perspectives and use cases of it!
What is Zero-ETL by AWS
What is Zero-ETL? Introducing New Approaches to Data Integration by DataCamp
So What’s All This Talk about Zero-ETL Integration? by Anjan Banerjee
Why ETL-Zero? Understanding the shift in Data Integration as a Beginner by Sarah Lea
Zero ETL: What’s Behind the Hype? by Paul Lacey
Last year, in one use case, I was asked to implement a near real-time pipeline in AWS. I attempted to build a landing area in Redshift using materialized views with auto-updates triggered by changes, reading directly from the Kinesis data stream.
From my experience, this approach resulted in significant processing overhead, and the clients immediately shut it down due to the high costs. Personally, I didn’t like the lack of control over the quality of ingestion. I definitely plan to learn more about this topic.
For this specific use case, in the end, we opted for a refined ELT approach, ensuring dashboard updates within five minutes.
Great write, I like the practical aspects, I recently explored the same idea in my newsletter “The Data Modernisation Playbook”, can be read here: https://open.substack.com/pub/thedatamodernisationplaybook/p/003-zero-etl-the-future-of-data-integration?r=1tj5ll&utm_medium=ios