
Week 13/34: Spark Fundamentals for Data Engineers
Understanding Apache Spark and its functionalities for data engineers

Before diving into Data Engineering with Databricks as part of our interview series, we encourage you to familiarise yourself with Apache Spark and common interview questions related to it. Since Databricks is built on top of Spark, some interview questions may focus solely on Spark concepts.
Spark is an open-source distributed computing system that requires manual setup and optimisation, whereas Databricks, built by Spark’s original developers, is a fully managed cloud platform with performance enhancements and easier deployment.
By mastering Spark, you'll be better prepared to navigate Databricks, optimise big data workflows, and take advantage of advanced capabilities with ease.
In this post, we cover:
Spark architecture with an analogy
Spark ecosystem
Scenario-based Spark interview questions with detailed answers.
If you like to:
Learn the basics of Spark
Explore key components:
Resilient Distributed Datasets (RDDs)
DataFrames
Spark SQL
See how to use Spark with a simple application
Check our previous post here :

For the previous posts of this series, check here: [Data Engineering Interview Preparation Series]1
Spark Architecture
Have you ever noticed that restaurants prepare meals much faster than we do at home? If you understand how this works, then you already have a fundamental understanding of how Apache Spark operates.
Let’s elaborate on this statement!

In a restaurant, three key roles ensure smooth operations:
Master Chef: Oversees the entire process, assigns tasks, and ensures everything runs efficiently.
Assistant Chefs (Workers): Handle different parts of meal preparation, working in parallel.
Restaurant Manager: Allocates resources, ensuring there are enough workers on busy days and optimising efficiency on slower days.
This mirrors Spark’s architecture!
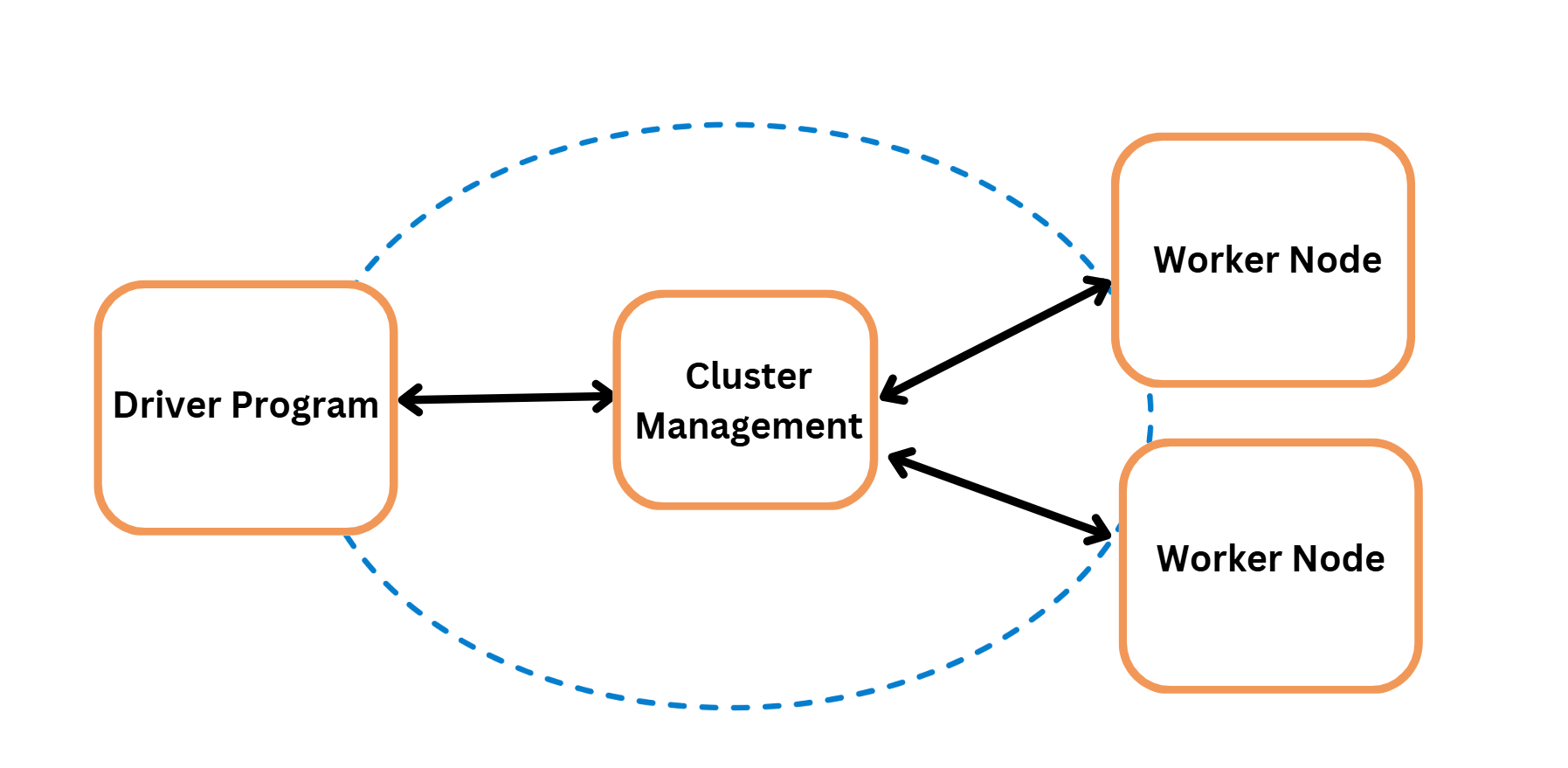
Just like a restaurant divides tasks to serve meals quickly, Spark processes large-scale data efficiently through parallel computing.
Spark does this by utilising three core components:
Driver Program (Master Chef): Initiates the process, understands the computation required, and distributes tasks across worker nodes.
Worker Nodes (Assistant Chefs): Execute assigned tasks in parallel, enhancing speed and efficiency.
Cluster Manager (Restaurant Manager): Allocates computing resources and manages workload distribution.
This parallel processing capability makes Apache Spark a powerful tool for handling big data workloads efficiently.
Spark Ecosystem
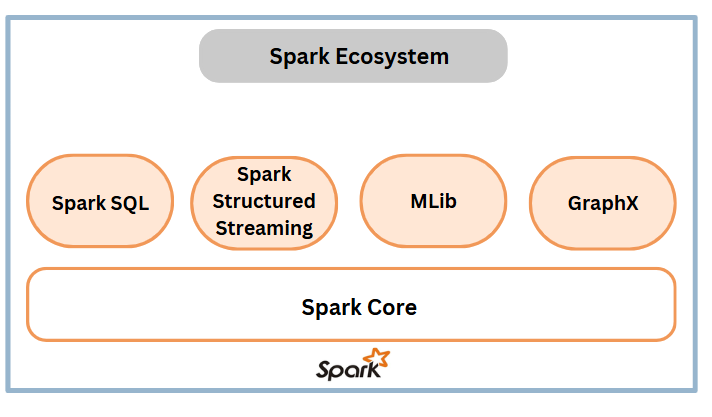
The Spark ecosystem refers to the collection of components, libraries, and tools that work with or extend the core Apache Spark platform. It consists of several core components designed for distributed data processing.
1. Spark Core (The Foundation of Spark)
Spark Core is the foundational engine of Apache Spark, responsible for:
Task scheduling: Managing execution across distributed nodes.
Memory management: Efficiently handling data storage and caching.
Fault tolerance: Ensuring resilience in case of node failures.
Spark Core operates on two key data structures:
Resilient Distributed Datasets (RDDs): Immutable collections of objects distributed across a cluster.
DataFrames: Structured, table-like data representations that simplify querying and transformations.
However, users typically don’t interact with Spark Core directly. Instead, Spark provides higher-level APIs and specialised libraries to make working with big data easier.
2. Key Libraries in the Spark Ecosystem
Each Spark library extends its core functionality, allowing users to handle different data processing tasks:
Spark SQL: Enables querying structured data using SQL and DataFrame APIs. It supports multiple formats like Parquet, CSV, and Delta Lake.
Structured Streaming: Designed for real-time data processing using micro-batching (processing data in small batches over time). It can ingest data from sources like Kafka, socket streams, files, and other streaming data sources. Unlike traditional batch processing, it continuously processes data in near real-time and can provide real-time analytics and insights.
MLlib: Spark’s machine learning library, offering tools for classification, regression, clustering, and recommendation.
GraphX: A library for large-scale graph processing, available in Scala and Java.
PySpark: The Python API for Apache Spark, allows users to write Python code while Spark handles distributed execution behind the scenes. This makes Spark accessible to data engineers and data scientists who prefer Python.
Spark also offers APIs for Scala, Java, and R to support different programming preferences.
3. Spark’s Two Data Structures (RDDs vs. DataFrames)
Spark processes large datasets efficiently by distributing them across multiple machines. The two main data structures in Spark are:
RDDs (Resilient Distributed Datasets)
The original distributed data structure in Spark.
Designed for fault tolerance and large-scale data processing.
Lacks a structured format, making operations like filtering and grouping more complex.
DataFrames

Provide a structured, table-like format with rows and columns, similar to relational databases.
Built on top of RDDs but optimised using Catalyst Optimiser and Tungsten Execution Engine for better performance.
Support efficient, high-performance transformations with simple methods.
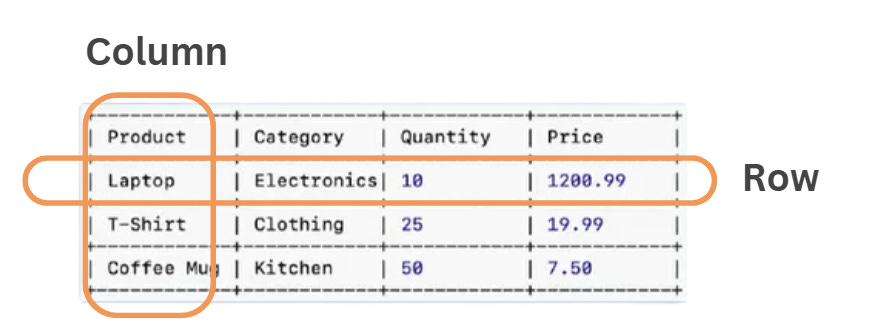
Both RDDs and DataFrames support data distribution across multiple machines, allowing Spark to handle large datasets in parallel. However, due to their ease of use and better performance, DataFrames have become the preferred choice in Spark.
4. Navigating Spark’s Official Documentation
When working with Spark, understanding its official documentation is essential. You can access it at spark.apache.org.
You may have noticed that Spark includes several key terms and components that might be difficult to grasp at first. To make them easier to understand, let's dive deeper into these components with real-world examples.