
Week 16/34: Data Pipelines and Workflow Orchestration for Data Engineering Interviews (Part #1)
Understanding Data Orchestration in data engineering and use cases

Building strong and reliable data pipelines is crucial for all businesses today. As data grows and processing becomes more complex, managing these pipelines efficiently is essential. This series will explore the key role of data pipeline orchestration in making data engineering work smoothly.
In the next 3 posts of our interview preparation series, we will explore data pipeline orchestration, its importance, use cases, and interview questions.
Here’s the plan for the posts:
Fundamentals of Orchestration in Data Engineering
Common Tools in Data Workflow Orchestration with Hands-on Practices
Best Practices & Common Interview Questions
For the previous posts of this interview series, check here: [Data Engineering Interview Preparation Series]1

In the world of data engineering, we often start simple. Write a script here, schedule a job there, and you manage dozens of interconnected processes before you know it. These pipelines transform raw data into valuable insights, but as they grow, managing them manually quickly becomes overwhelming.
That's when proper orchestration becomes essential (not just helpful but crucial) to maintaining consistency and reliability in your data processes.
What Exactly Is Data Orchestration?
Data orchestration is the process of coordinating and automating the execution of complex data workflows. Think of it as an orchestra conductor ensuring each instrument (or, in our case, each data task) plays at the right time, in the right sequence, and in harmony with the others.
At its core, orchestration includes:
Defining dependencies between tasks.
Scheduling when tasks should run.
Monitoring execution.
Handling failures gracefully.
Providing visibility into the entire process.
Without orchestration, data engineers often find themselves building increasingly complex scripts filled with conditional logic, error handling, and timing mechanisms, turning what should be a straightforward data transformation into a maintenance nightmare.
The Evolution of Orchestration in Data Engineering
The journey of orchestration tools mirrors the evolution of data engineering itself:

Early Days: Cron and Shell Scripts
Initially, simple cron jobs and bash scripts were sufficient. A nightly script might extract data, transform it, and load it into a database. But as dependencies grew, these solutions quickly became difficult to manage.
Middle Period: Workflow Management Systems
Tools like Oozie and Luigi emerged, offering more structured approaches to defining workflows. They introduced concepts like directed acyclic graphs (DAGs) to represent task dependencies.
Modern Era: Comprehensive Orchestration Frameworks
Today's solutions, like Apache Airflow, Prefect, and Dagster, provide robust ecosystems for defining, scheduling, monitoring, and troubleshooting complex data workflows.
Note: We wanted to share this evolution because some companies still rely on older orchestration methods. Although these cases are now rare, they're not entirely gone. Knowing how orchestration tools evolved helps you understand legacy systems you might encounter and why modern solutions have become the industry standard.
Key Terms and Concepts in Data Orchestration
Before diving deeper, let's clarify some essential terms you'll encounter frequently in orchestration:
1. Directed Acyclic Graph (DAG)
A DAG is a visual representation of tasks within a workflow, clearly showing their order and dependencies. "Acyclic" means tasks flow in one direction (there are no loops or cycles). DAGs ensure pipelines are well-defined, logical, and easy to maintain.
2. Task
A task is a single, clearly defined action within a workflow, such as extracting data, transforming datasets, running a model, or sending notifications. Each task is designed to achieve a specific outcome and can succeed or fail independently.
3. Workflow
A workflow is a group of related tasks executed together as a sequence. For example, a daily sales report workflow might include tasks for data extraction, cleaning, transformation, and reporting. Workflows provide structure, manage complexity, and clearly outline end-to-end data processes.
4. Dependencies
Dependencies are rules defining task order and relationships within a workflow. They ensure tasks run in the correct sequence. For example, transforming data depends on first extracting the data successfully. Orchestration tools automatically handle these dependencies, ensuring tasks don't run until all prerequisites are satisfied.
5. Idempotency
An idempotent task is designed to produce the same outcome whether executed once or multiple times. Idempotency is critical in orchestration because tasks may occasionally be retried after failures or re-executed during troubleshooting. Designing tasks to be idempotent prevents unintended side effects or duplicated data.
6. Scheduling and Backfilling
Scheduling defines exactly when and how frequently workflows should run. Backfilling refers to executing workflows for past time periods to handle historical data or recover from downtime. Good orchestration platforms make scheduling and backfilling straightforward.
7. Retry and Error Handling Strategies
Retry strategies define how orchestration systems respond to failures. For instance, they might retry a task several times with increasing delays (exponential backoff). Robust error handling ensures that temporary issues don't permanently halt critical processes.
Roles Typically Involved in Data Orchestration
Data orchestration often requires collaboration between different teams and roles. While Data Engineers are usually responsible for orchestration workflows, other roles often participate in defining, using, or supporting these processes:
1. Data Engineers
Typically own and manage orchestration workflows end-to-end. They design, build, deploy, and monitor data pipelines, ensuring that all data tasks run efficiently, reliably, and securely.
2. Analytics Engineers
Often involved in defining transformation tasks and business logic within workflows. They collaborate with Data Engineers to ensure that analytical models and reports accurately reflect business requirements.
3. Data Scientists
Use orchestration workflows for machine learning pipelines, including model training, validation, deployment, and monitoring. They collaborate closely with Data Engineers to automate and operationalise ML processes.
4. Business Analysts and Data Analysts
Rely on orchestrated workflows for accurate, timely data delivery to reporting and analytics platforms. They often define requirements and monitor data quality outcomes, working closely with Data Engineers.
5. DevOps Engineers
Support infrastructure, security, and scalability of orchestration environments. They manage underlying resources (e.g., cloud servers, containers), ensuring orchestration tools run smoothly and securely.
6. Data Architects
Help define the overall strategy, standards, and architecture for orchestration and data workflows. They collaborate with Data Engineers to align orchestration tools and practices with broader organisational goals.
Core Problems Solved by Data Orchestration
Data orchestration addresses several core challenges in the data engineering lifecycle. Beyond simply automating tasks, it significantly improves reliability, visibility, governance, and security within data processes.
1. Dependency Management
Managing dependencies is a fundamental challenge in data workflows. Orchestration tools explicitly define these dependencies, automating task execution in the proper order.
Consider a simple workflow:
Task A: Extract data from an external API.
Task B: Clean and transform the extracted data.
Task C: Load transformed data into a warehouse.
Task D: Generate reports.
Task B can only begin once Task A is finished successfully. Orchestration automatically handles these dependencies, reducing manual effort and potential errors.
2. Scheduling and Timing
Data workflows typically follow recurring schedules, such as:
Hourly aggregations
Daily reconciliations
Weekly reports
Monthly archiving processes
Orchestration platforms provide sophisticated scheduling capabilities beyond basic cron jobs, including:
Complex schedules across different time zones.
Automated handling of historical data backfills.
Easy schedule modifications aligned with changing business needs.
Management of concurrency and execution time windows.
3. Error Handling and Recovery
Without orchestration, task failures can cause extended downtime or data inaccuracies. Orchestration addresses these issues through robust error management, offering:
Instant alerts upon failure (via messaging or emails).
Detailed logging and error information for quick diagnosis.
Automatic retries based on configurable strategies.
Conditional logic for different failure scenarios.
Workflow resumption directly from the failure point.
These capabilities ensure rapid recovery, minimising disruption.
4. Visibility and Monitoring
As pipelines grow complex, visibility into task execution becomes critical. Orchestration provides comprehensive monitoring and analytics, including:
Real-time dashboards tracking current workflow status.
Historical insights into execution times and performance bottlenecks.
Clear records of success and failure rates.
Resource usage analytics for performance tuning.
This transparency makes pipelines easier to maintain and optimise.
5. Governance and Compliance
Effective orchestration supports data governance and compliance by ensuring:
Comprehensive audit trails for every workflow execution, aiding compliance audits.
Standardised, documented, and repeatable workflows.
Easy tracking and verification of data lineage and transformations, crucial for regulatory purposes.
These aspects help organisations maintain high-quality, compliant data practices.
6. Security and Access Control
Data orchestration also significantly enhances security through centralised management and control:
Central management of permissions and role-based access to workflows.
Prevention of unauthorised or unintended data operations by enforcing strict execution controls.
Secure handling of sensitive data through managed, traceable workflows.
Reduced security risks by limiting direct, manual interactions with production systems.
By controlling how data tasks execute, orchestration reduces security vulnerabilities across the data engineering lifecycle.
When Do You Need Orchestration?
You might be wondering when it's time to invest in orchestration. Here are some signs:
You find yourself writing complex error handling and retry logic.
Troubleshooting failures takes significant time.
You need to ensure data is processed within specific time windows.
Multiple team members need visibility into pipeline execution.
Your workflows have complex branching logic or conditional execution.
Common Use Cases for Data Orchestration
Data orchestration is valuable across various scenarios in data engineering and analytics. Here are some of the most frequent and important use cases:
1. Data Analytics and Reporting Pipelines
Automating data extraction, transformation, loading (ETL/ELT), and reporting processes. For example, generating daily sales reports or monthly business reviews, ensuring data is timely and accurate.
2. Machine Learning Pipelines
Managing end-to-end machine learning workflows, from data preparation and model training to validation, deployment, and monitoring. Orchestration ensures repeatable and reliable execution of complex ML tasks.
3. Real-Time and Streaming Data Processing
Coordinating real-time data ingestion, processing, and analytics workflows, such as processing user behaviour or sensor data streams. This ensures low latency and accurate real-time insights.
4. Data Migration Projects
Automating the movement and transformation of large datasets between databases, data warehouses, or cloud storage systems, making migrations efficient and reducing manual effort.
5. Data Quality and Validation Processes
Consistently applying data quality checks, validation rules, and anomaly detection tasks across datasets, maintaining high data integrity.
6. Backup, Archiving, and Disaster Recovery
Regularly scheduled workflows to automatically back up databases, archive historical data, or replicate data to remote systems for disaster recovery purposes, minimising data loss and business disruption.
A Real-World Example
Let's look at a practical scenario: generating daily sales reports from e-commerce data.
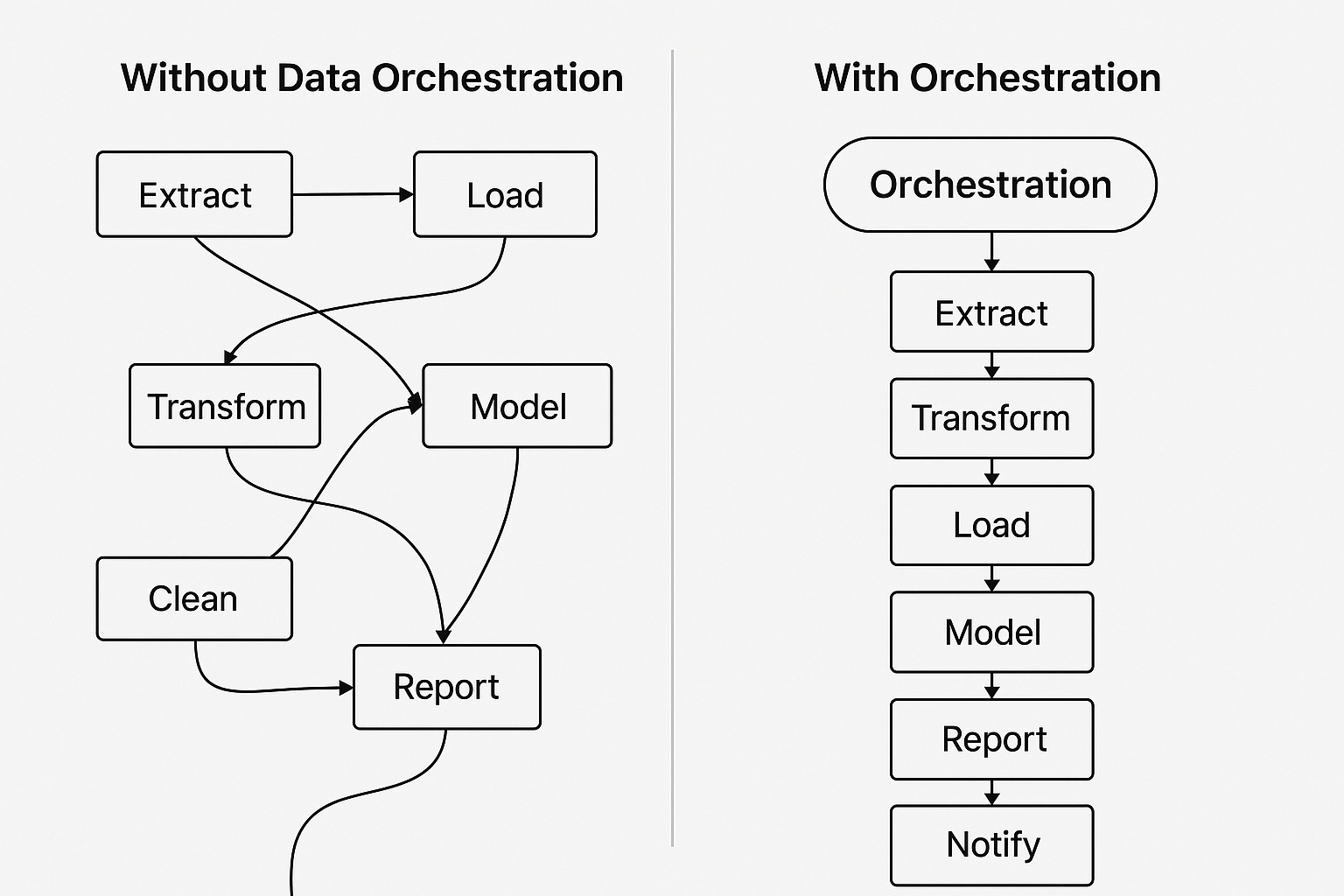
Without Orchestration:
You might have several independent scripts:
One script extracts transaction data from your database.
Another pulls inventory levels.
A third script combines these datasets and calculates key metrics.
Finally, a script generates and distributes the reports.
Each script must handle errors, logging, and timing separately. If the inventory extraction script fails, downstream scripts might run with incomplete data or fail unexpectedly, causing confusing outcomes and extra troubleshooting.
With Orchestration:
You define a single, clear workflow:
Task dependencies are explicitly defined (e.g., reporting only starts after successful data extraction and processing).
If any step fails, dependent tasks immediately halt, preventing incorrect results.
Notifications and alerts trigger instantly, allowing quick resolution.
The full pipeline status is visible in one centralised dashboard.
Execution history and detailed logs make troubleshooting straightforward.
Orchestration simplifies complex processes, making your data workflows reliable, transparent, and easier to manage.
Conclusion
In this post, we explored the fundamentals of data orchestration, including its core concepts, key benefits, and practical use cases. We discussed;
The evolution from basic scripts to orchestration frameworks
Why have modern tools become industry standards
How orchestration improves data engineering workflows
Common use cases of data pipeline orchestration
In the next post in this series, we'll explore specific orchestration tools and frameworks, compare their features, and help you choose the right one for your needs. We'll also dive deeper into implementation patterns and best practices that can make your orchestrated workflows more robust and maintainable.
If you are interested in orchestration in practice, you can check out the below post where we use Dagster to schedule a data ingestion task.

We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
https://pipeline2insights.substack.com/t/interview-preperation