Why Data Quality Is the Key to AI Success
Common data quality problems and their impact on AI

In the last two posts of our Data Quality series, we explored the fundamentals of data quality, including its definition, key dimensions, and real-world examples. We also shared insights from our careers and provided a roadmap for bridging theory with practice to implement effective data quality checks.
If you haven’t caught up yet, you can read the previous posts here: [Data Quality Series]1
In this post, we’ll dive deeper into the impact of data quality on AI. We’ll explore why data quality is crucial for AI and discuss key questions you can ask to assess the data quality within your organisation.
Note: These posts are based on our experiences and insights from the Master AI-Ready Data Infrastructure2 by Chad Sanderson, a pioneer in data quality/data contracts and co-author of the Data Contracts book.
Before we dive into the details, let's check out Chad's definition of data quality.

Data quality refers to the measure of data's condition, suitability, and effectiveness for its intended use in operations, decision-making, and planning. Data quality issues occur when the expectations of data producers, do not meet the expectations of data consumers.
Let’s start by discussing who are the data producers and consumers.
Consumers and Producers
Data Producers
Data producers are the engineers, developers, and third-party platforms responsible for generating raw data. They serve as the foundation for all AI training, analytics, and decision-making processes by providing the initial data inputs.
Data Consumers
Data consumers are individuals, systems, or applications that use processed data to extract insights, make informed decisions, and drive business outcomes. While they have limited visibility into upstream systems, they rely on data for various functions. Key consumers include AI/ML engineers and data scientists who develop models, analysts who generate insights, business teams (Sales, Marketing, Executives) who drive strategy, and customer service and product teams who enhance user experience.

Both data producers and consumers play a critical role in the AI ecosystem, ensuring that high-quality data drives innovation and decision-making.
Why is Data Quality Essential to AI?

The Foundation of Learning
AI systems learn from data, without it, they can’t function. The quality, accuracy, and relevance of data determine how effectively an AI model learns and adapts over time.
Garbage In, Garbage Out
An AI model is only as good as the data it's trained on. If the data is inaccurate, biased, or incomplete, the model's outputs will be equally unreliable, reducing the system’s effectiveness.
Impact on Decision-Making
AI plays a critical role in automating decisions. High-quality data ensures that these decisions are accurate, reliable, and trustworthy, increasing confidence in AI-driven processes.
Poor Data Can Break AI Models
Inconsistent or low-quality data can cause AI models to degrade over time or even fail entirely, leading to costly inefficiencies and requiring constant retraining.
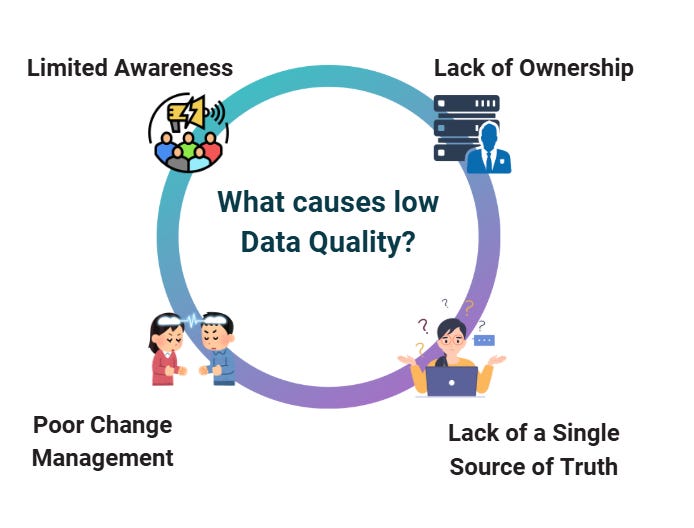
Why Data Quality Issues Occur?