


Centralised Orchestration in Dagster Using Code Locations
How to manage independent projects under one Dagster instance

In previous posts of our Data Engineering Interview Preparation Series1, we explored data orchestration and workflows and implemented hands-on projects using Dagster2. If you missed them, you can catch up here:



Now, we’re going to take things a step further and dive deeper into Dagster by looking at the code locations concept.
Let’s start with this scenario:
Imagine we're managing two independent pipelines:
They could be separate projects.
Or owned by different teams.
Or built with different environments or dependencies.
And we're responsible for orchestrating these workflows using Dagster. What would we do? Do we create separate Dagster servers? What if we keep them separate but still manageable from a central location and a single Dagster server?
That’s where code locations come in. They allow us to:
Isolate codebases.
Manage them independently.
Still operate everything under one Dagster web server.
The code and project files are available in the repository here3.
Our example project includes two dlt4 pipelines handling two distinct data sources:
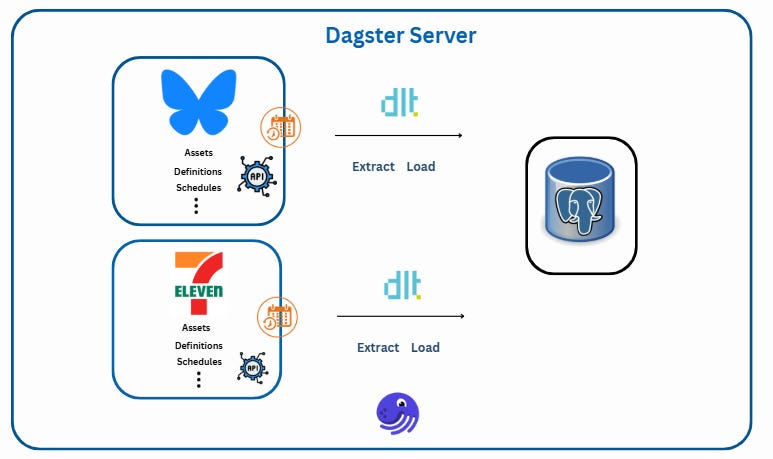
Bluesky Social Media Posts: Collecting public posts around fuel prices.
7-Eleven Fuel Price API: Gathering near real-time fuel price data from Australian gas stations.
Both pipelines load data into a PostgreSQL database and are scheduled to run at different frequencies.
If you are not familiar with dlt, a Python data ingestion library, please check out the introduction post here:

But before jumping into implementation, let’s quickly define a few important Dagster concepts that you'll encounter throughout the setup.
Assets
Assets in Dagster represent the data objects that our pipelines create, update, or manage. Think of it as any piece of data that our code produces and saves somewhere, whether that's a CSV file on disk, a database table, or a trained ML model. This asset-centric approach allows us to focus on what we're building, not just how we're building it.
Common examples of assets include:
Database table or view
File (local machine or AWS S3)
A machine learning model
To define an asset in Dagster, we use the @asset decorator from the dagster module.
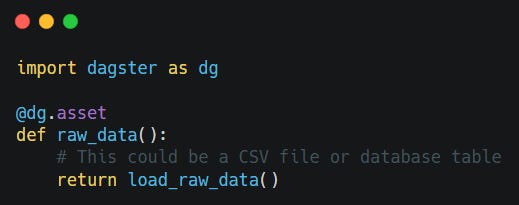
Since we use dlt with Dagster, we use the @dlt_assets decorator. It converts our dlt data pipeline into Dagster assets, making it easy to manage and orchestrate within the Dagster framework. If you'd like to learn more about how Dagster integrates with dlt, check out the official documentation.
Definitions
The definitions serves as the central manifest of your Dagster project. It contains an Definitions object that brings together everything Dagster needs to understand, operate, and orchestrate our data pipeline, including assets, jobs, schedules, sensors, and resources.

In short, the Definitions object tells Dagster:
“Here’s everything that belongs to this project and how it all fits together.”
Example:
Let’s say we’re building a pipeline to process customer data. Our assets might include:
Raw customer records
Cleaned customer profiles
A customer insights report
Our definitions.py would specify:
What each of those assets is
How they depend on one another
When and how they should be executed (via jobs, schedules, or sensors)
By bundling all this into a single Definitions object, Dagster gets a complete, connected view of our pipeline: what to run, when to run it, and how it all flows together.
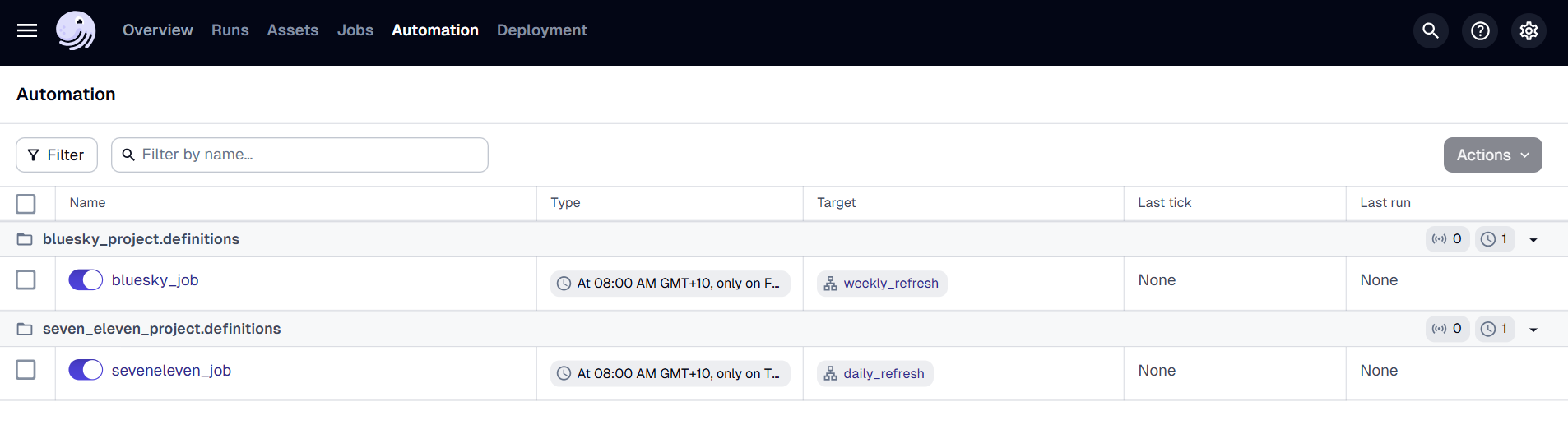
Schedules
Schedules are like timers for our data pipeline; they automatically trigger jobs to run at specific times or intervals. Think of them as setting an alarm clock for our workflows.
With schedules, we can, for example:
Run a daily sales report every morning at 6 AM.
Update the customer database every hour.
Train a machine learning model every Sunday at midnight.
They help us automate recurring tasks so our pipelines stay fresh without manual intervention.
Jobs
Jobs are collections of assets or operations (ops) that execute together as a single unit of work. Think of a job as a "batch of work"; it defines what should run, in what order, and how.
Jobs bring together the logic of our pipeline into a defined execution plan.
Examples:
A job might be performed:
Fetch data from an API, clean the data, and load it into the database.Or:
Train a machine learning model, validate the results, and deploy the model
Jobs are essential for organising reusable workflows and can be triggered manually, on a schedule, or in response to events (via sensors5).
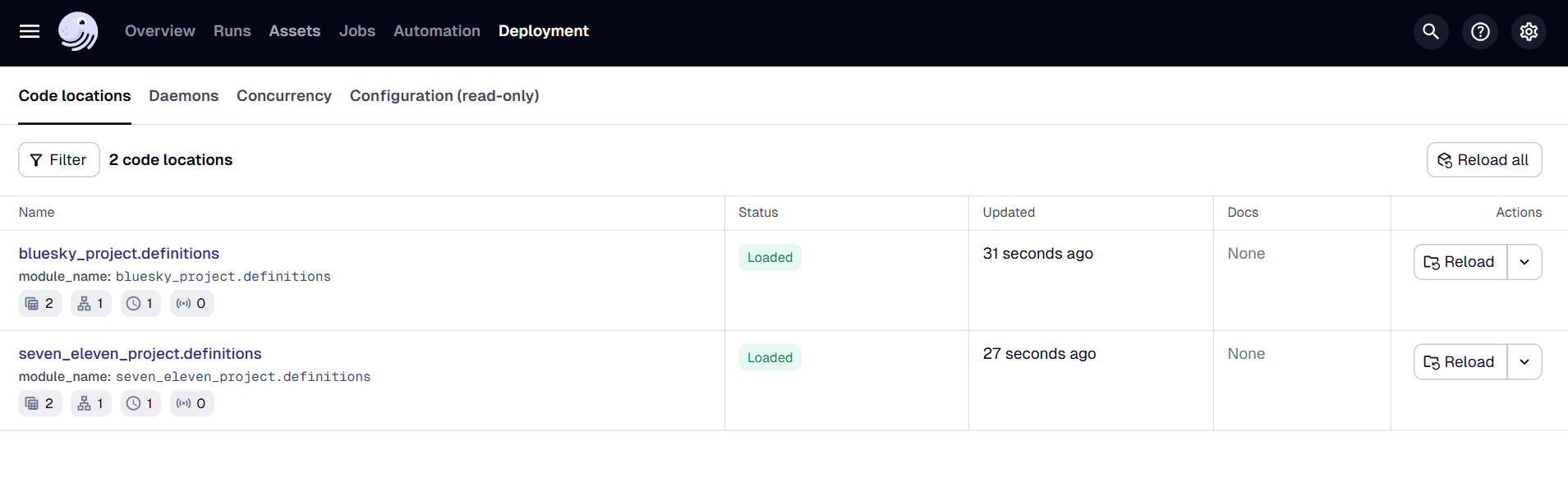
Code locations

Code locations in Dagster let us split our project code into independent units (like folders or repositories). Each unit has its own environment, dependencies, and workflows, but they are all still managed from a single Dagster deployment.
Hands-on example:
In this example, we have two independent Dagster projects:
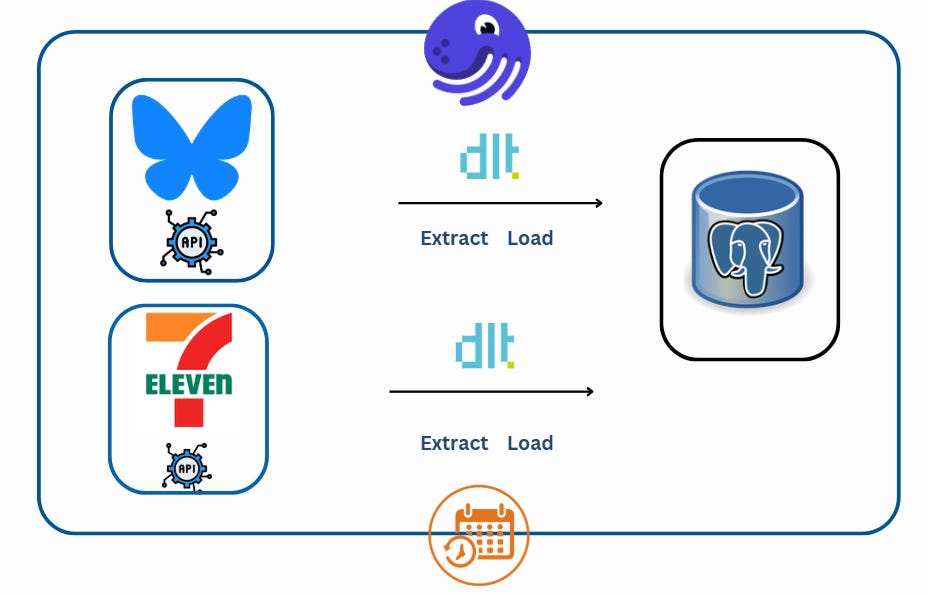
bluesky_project: Ingests data from the Bluesky API and is scheduled to run weekly.
seven_eleven_project: Ingests data from the 7-Eleven API and is scheduled to run daily.
Each project contains its own:
pipeline script
Assets
Jobs
Schedules
Definitions
We’ve placed these in separate folders inside a central repository named company_orchestrator/.
You can find the repository for this implementation here6.
How does Dagster know where our projects are?
A workspace.yaml7 is used to configure code locations in Dagster. It tells Dagster where to find our code and how to load it
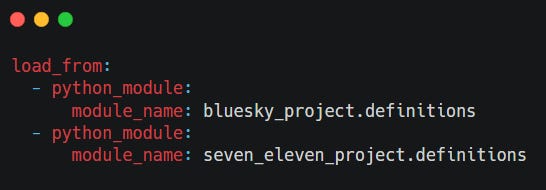
Also, We require Central definitions.py at the root of the repository (company_orchestrator/) to merge the Definitions from both projects.

The definitions.py file at the root of your project is intended to combine the Dagster definitions from both the bluesky_project and seven_eleven_project modules. This allows us to orchestrate and manage assets, schedules, and resources from both projects in a single Dagster instance.
Key Benefits:
Centralised orchestration: We can run, schedule, and monitor all assets and jobs from both projects in one Dagster UI.
Modular development: Each project can be developed and tested independently, but deployed together.
Scalability: Easy to add more projects or data sources in the future by merging their definitions
Project Flow Example:
To run the project, we can simply run :
dagster dev -w workspace.yaml
Command Breakdown
dagster dev: Launches Dagster's development server (Dagit UI + daemon services8)-w workspace.yaml: Specifies the workspace configuration file to use
Example Flow in our Project
To run the project, we can simply run:
dagster dev -w workspace.yaml
dagster dev: Launches Dagster's development server (Dagit UI + daemon services)-w workspace.yaml: Specifies the workspace configuration file to use
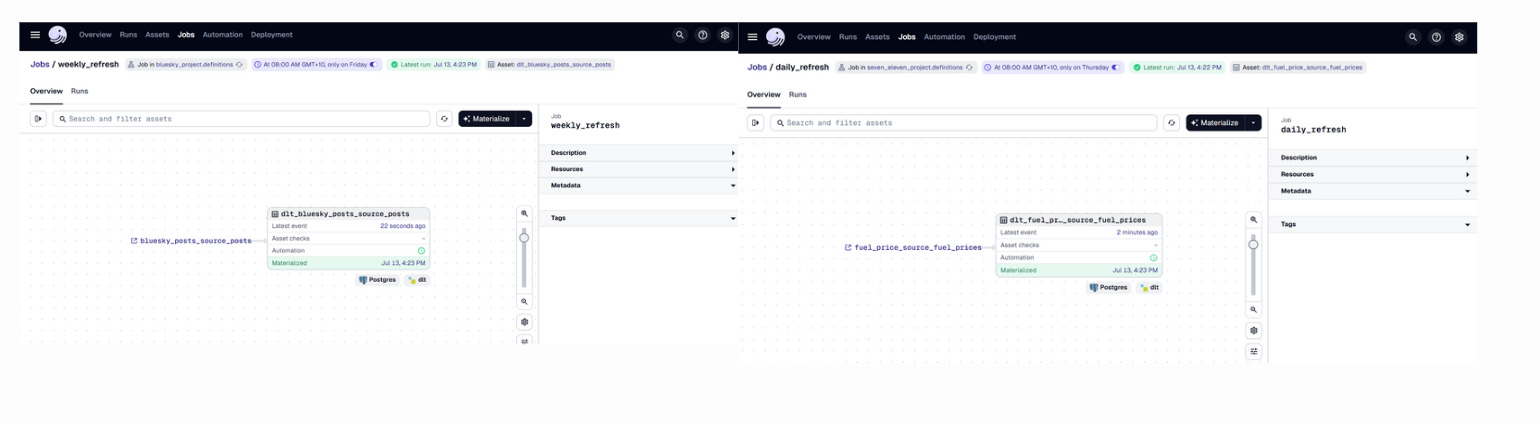
Dagster reads workspace.yaml:
Finds bluesky_project.definitions and seven_eleven_project.definitions.
Dagster loads the Definitions objects from those modules.
Dagster UI shows us all the assets, jobs, and schedules defined in those modules.
Conclusion
In this post, we learned how to use code locations in Dagster to manage multiple independent pipelines, each with its own assets, jobs, and schedules, while still controlling everything from a single Dagster instance.
By using workspace.yaml and a central definitions.py, we can keep projects modular, easy to maintain, and ready to scale.
This setup is ideal for teams working on different data workflows but wanting a unified orchestration system.
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Enjoy Pipeline to Insights? Please share it with others! Refer:

3 friends and get a 1-month free subscription.
10 friends and get 3 months free.
25 friends and enjoy a 6-month complimentary subscription.
Our way of saying thanks for helping grow the Pipeline to Insights community!
https://pipeline2insights.substack.com/t/interview-preperation
https://dagster.io/
https://github.com/pipelinetoinsights/company_dagster_orchestrator
https://dlthub.com/docs/intro
https://docs.dagster.io/guides/automate/sensors
https://github.com/pipelinetoinsights/company_dagster_orchestrator
https://docs.dagster.io/deployment/code-locations/workspace-yaml
https://docs.dagster.io/deployment/execution/dagster-daemon