
Getting Started with OpenMetadata: An Open-Source Data Catalogue Solution
What is OpenMetadata, how to deploy it, our hands-on experience, and many more insights.

We just joined a company and have been assigned our first project. As we start exploring the data, we ask our manager where to find the relevant tables. He suggests tables starting with sv001, sv003, or something similar, and tells us to confirm with Tom. Tom is a busy person, but eventually, we manage to schedule a time to speak with them. We explain what we need, and they share the table names.
Everything seems fine at first. We start exploring the tables and their columns, but soon we notice columns like DivID or QTypeCD only contain IDs with no obvious meaning. We don’t know which ID represents what, so we have to reach out again. We’re referred to software engineers, sometimes outsourced, and this cycle continues until we finally figure out what we need.
While we can make educated guesses about column meanings and form hypotheses to understand their logic, at the end of the day, how do we prove what we’ve done with the data? Often, we don’t know whether these tables are derived, aggregated, or subsets of other datasets, who the owners are, or how they’re being used elsewhere in the organisation.
Welcome to the world of data without metadata, data catalogues, or governance.
Definitions and metadata are crucial, yet often missing. In some of our roles, we experienced this exact problem repeatedly. The more projects or requests we worked on, the more we realised how much this part of data management was lagging.
Our first initiative was simple: document everything we learned in a spreadsheet. We also made it a point to remind executives that metadata and catalogues were missing and that having them would make discovery faster, easier, and more reliable.
However, it’s not just about speed; governance matters too. We need to ensure we are using a single source of truth, that our tables are accurate, and that we have sufficient information about the data.
After building a catalogue manually, we began exploring ways to automate the process, identify the right tools, and make it scalable. We reached out to our network to learn from their experiences and researched the tools available in the market. We also explored Reddit to see what the wider community recommended and came across OpenMetadata.
We decided to try it out, looking for something lightweight, easy to set up, open-source, and user-friendly. OpenMetadata seemed like a promising candidate.
In this post, we want to share:
What is Metadata?
What is OpenMetadata?
History of OpenMetadata
Why OpenMetadata?
How to deploy OpenMetadata?
OpenMetadata Case Studies
Resources to learn more
Note: During our research, we came across Awesome Data & AI Governance repository1 , a curated list of platforms and tools to help organisations discover, manage, and monitor data and AI solutions. It’s definitely worth a look.
Before we start, if you’re preparing for data engineering interviews, don’t miss our popular Data Engineering Interview Preparation Guide. Check it out here2.
What is Metadata
Metadata describes key details about data, such as its size, format, structure, last update, and who can access it. Storing metadata in one place helps teams quickly find and understand their data, making it easier to manage and use effectively.
In short, metadata is the map of our data. It keeps things organised, prevents problems, and ensures the right people can find and use the right data when they need it.
We covered metadata, what it is, its key categories, the concept of a data catalogue, and much more in this post:

What is OpenMetadata

OpenMetadata3 is an open-source platform that provides a unified solution for managing metadata across an organisation. Its lightweight architecture, extensive connector ecosystem, and collaboration-driven design make it an ideal fit for modern data environments.
By centralising metadata, enhancing discoverability, and automating governance, OpenMetadata helps teams build greater trust, transparency, and efficiency around their data assets.
Under the hood, OpenMetadata combines a Java-based backend API, a Python ingestion framework, and a JavaScript/TypeScript user interface, a stack designed for flexibility, scalability, and ease of integration.
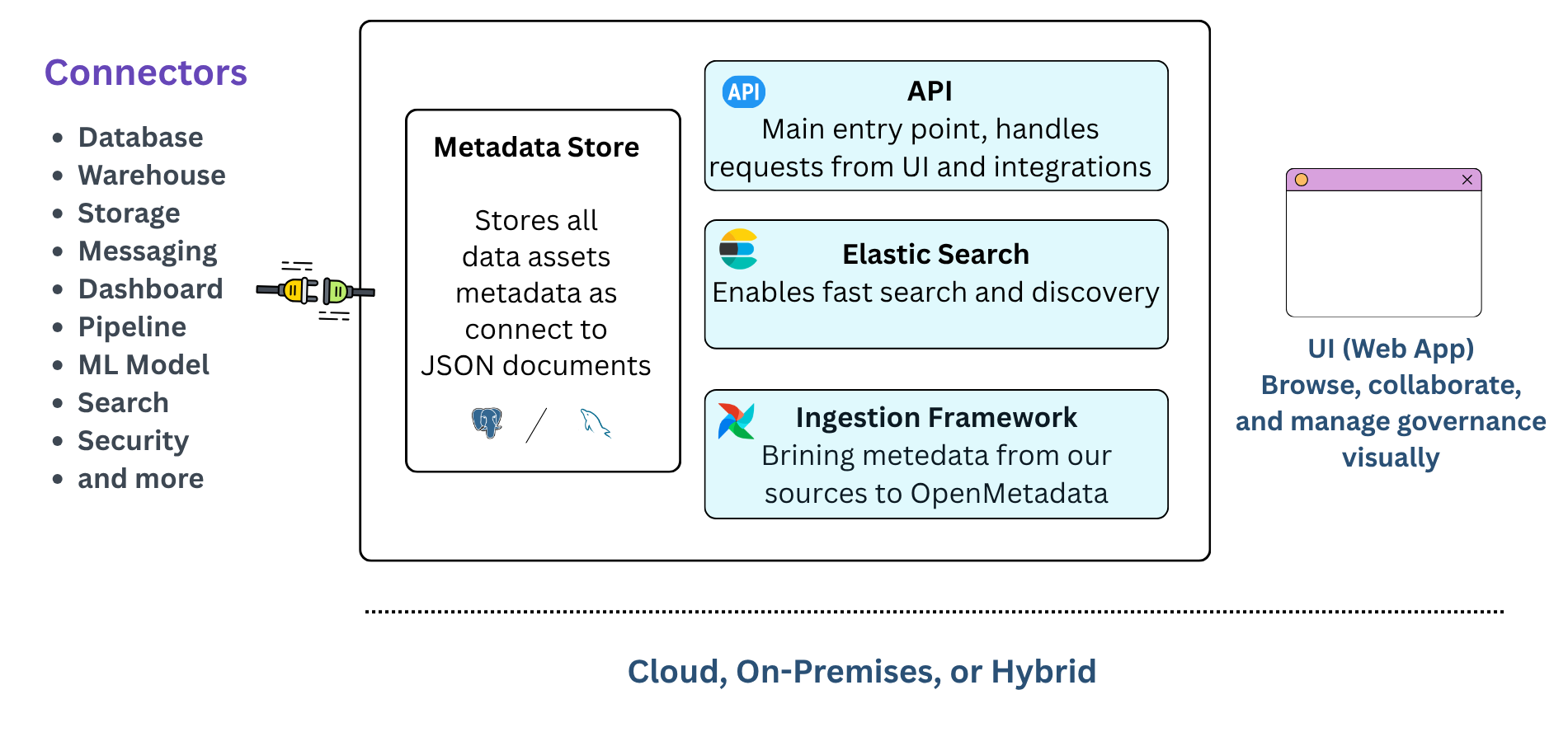
The platform offers 90+ pre-built connectors to ingest metadata from databases, warehouses, lakes, streaming platforms, dashboards, and machine learning models. For custom or internal systems, well-documented APIs enable smooth metadata integration. All ingested metadata is organised into a Unified Metadata Graph, providing a single source of truth for the entire data landscape.
Through its intuitive, unified interface, OpenMetadata eliminates the need to switch between multiple catalogues or governance tools. Its built-in collaboration features bring together data engineers, analysts, data scientists, governance teams, and business users within a shared environment to discover, manage, and understand data more effectively.

To learn more, check out the OpenMetadata documentation4.
History of OpenMetadata
OpenMetadata, based in San Mateo, California, United States, was officially announced and open-sourced in 2021. It evolved from Uber’s internal metadata projects, uMetadata and Databook5, which the founders, Suresh Srinivas6 and Sriharsha Chintalapani7, developed to help teams discover and manage data at scale. Rather than simply open-sourcing these internal tools, the team built a new system from scratch, applying lessons learned to create a solution that wasn’t tied to a single company, avoided the complexity of entangled internal tools, and could serve a broader community without being constrained by shifting business priorities.

Collate8 is a fully managed service built on OpenMetadata, purpose-built for data teams operating at scale. With its cloud-native architecture, Collate takes care of deployment, upgrades, backups, and high availability, enabling teams to focus on insights rather than infrastructure.
Curious about how the open-source version compares to the managed one? Take a look at this documentation9.
Why OpenMetadata
Managing data effectively requires more than just access to tables; it requires context, quality, governance, and collaboration. OpenMetadata provides a comprehensive solution to help organisations discover, understand, and manage their data assets at scale. Below, we explore its key capabilities and features.
Central Repository for Metadata
It serves as a unified metadata store, integrating information from across the data ecosystem using standardised schemas and APIs. It consolidates capabilities for data discovery, quality, observability, profiling, collaboration, and lineage, fetching DDLs, stored procedures, views, tables, and column details for configured schemas.
Metadata Versioning
OpenMetadata tracks schema changes and data volume variations over time, maintaining a complete history of all modifications, such as new columns, tables, or updates.
Data Profiling
It includes a built-in data profiler that computes metrics for tables, including unique records, null proportions, row counts, and data trends, helping teams quickly assess data quality.
OpenMetadata can be easily hosted on-premises, in the cloud, or in a hybrid setup using its Docker Compose setup, giving organisations flexibility in deployment according to their infrastructure and compliance needs.
Key Features

Discovery
Unified data catalogue with integrated data quality and business glossary.
Natural language search with advanced filtering and faceting.
90+ pre-built connectors for warehouses, lakes, dashboards, and ML models.
Governance
Centralised business glossary and classification tags.
Automated PII detection and metadata description generation.
Customisable governance policies to maintain compliance.
Data Quality
Table and column-level test cases with no-code or SQL-based options
Test suites with detailed reporting and dashboards
Visual quality lineage maps and actionable insights.
This table shows a comparison of tests from Great Expectations10, Soda11, and OpenMetadata.
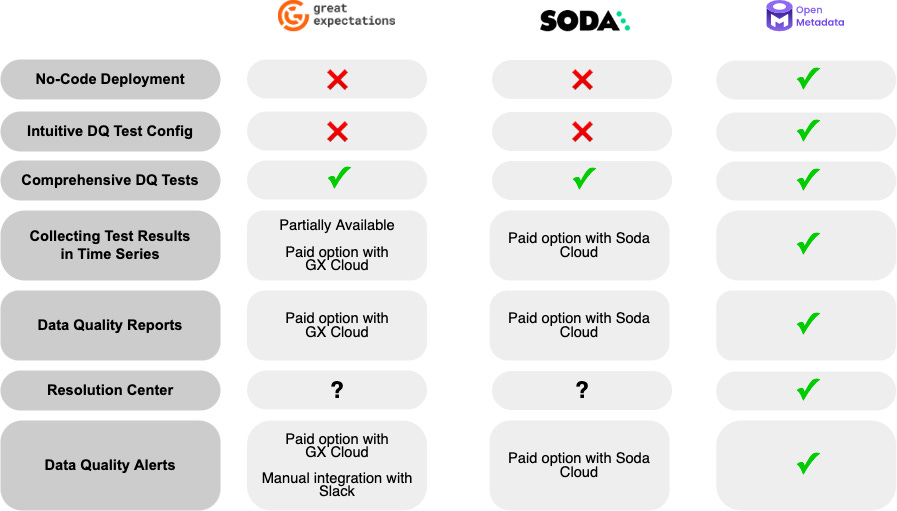
Note: Creating tests in OpenMetadata is quick and easy, just a few clicks to set up assertions and validate tables in minutes rather than hours.
Data Contracts
Define expected schema structures and semantic standards.
Integrate data quality tests into contracts.
Maintain validation history and SLA tracking for continuous monitoring.
Reinforces data mesh principles across domains.
Collaboration
It enables teams to break silos, share knowledge, and enhance understanding through:
Conversation Threads: Discuss data assets and tags directly in the platform.
Tasks: Assign updates for descriptions, tags, or glossary approvals.
Announcements: Notify teams about schema changes, deprecations, or deletions.
Integrations with Slack and Microsoft Teams for smooth communication.
Activity feeds and dashboards to track progress.
Data Insights
Analytics on data asset usage, coverage, and ownership.
Dashboards for data health and governance KPIs.
Reports to track metadata adoption and quality trends.
MCP Server
OpenMetadata provides a Model Context Protocol (MCP) server12 that allows AI assistants and other clients to interact with our metadata catalogue. The MCP server exposes tools for searching metadata, managing glossaries, and working with lineage data.
Note: If you want a quick hands-on experience with the tool, whether exploring or running a PoC, you can use the sandbox.
How to deploy OpenMetadata?

OpenMetadata offers flexible deployment options to suit different organisational needs:
Docker Compose13 or Kubernetes14 on our preferred cloud provider.
Bare-metal deployment15 on your own servers.
Note: If you’re not familiar with Docker, we highly recommend checking out our beginner-friendly “Docker for Data Engineers” post here:

If you prefer not to maintain it ourselves, we can choose the managed version, which provides a fully managed OpenMetadata experience.
The OpenMetadata Docker deployment is built around several core components that work together to manage metadata efficiently:
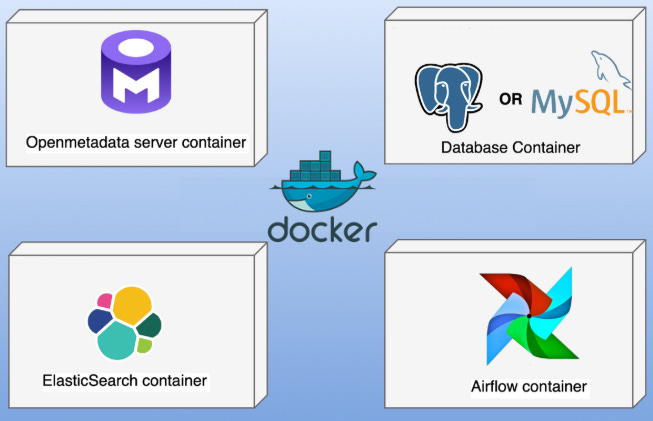
1. OpenMetadata Server (openmetadata-server)
The main application server.
Handles API requests, authentication, and business logic.
Connects to a PostgreSQL database and Elasticsearch.
Serves the UI for user interaction.
2. Elasticsearch (elasticsearch)
Search engine for metadata discovery.
Stores indexed metadata for fast and efficient searching.
3. Ingestion Service (ingestion)
Orchestrates metadata pipelines, typically Airflow-based.
Handles metadata extraction from various sources.
4. Database Migration (execute-migrate-all)
One-time service to set up the database schema.
Executes migrations before the main server starts.
Our Experience
We’ve explored the tool and are currently running it on an on-premises server, with the database hosted on Azure PostgreSQL. While we already have an existing solution for data quality tests and decided to keep it in place, we tested OpenMetadata’s built-in capabilities and found them quite easy to use. We can either run the default tests or define our own using SQL.
If you have any questions, feel free to reach out or leave a comment; we’ll be happy to help.
OpenMetadata Case Studies
Carrefour Brazil16, the country’s largest grocery retailer, was dealing with fragmented data, unclear ownership, and limited visibility across its systems. Different teams managed their data in isolation, which made governance and collaboration difficult. To address this, the data platform team introduced OpenMetadata (internally called C4Data). It focused on practical steps, running workshops, hosting a “Datathon” to encourage cataloguing, and automating data quality tests and Jira ticket creation.
In the first year, the team onboarded around 500 users, catalogued thousands of tables and dashboards, and created a shared glossary of more than 300 terms across 20+ domains. They also introduced simple quality indicators like bronze, silver, and gold seals to make data standards more visible. These efforts helped bring more clarity and accountability to how data is managed across the company.

Thndr17, a fast-growing investment platform with over three million users, faced the challenge of maintaining data quality, security, and visibility as its user base expanded rapidly. With a small data team, manual checks for data freshness, schema changes, and PII detection became time-consuming and hard to scale. To address this, they adopted OpenMetadata as a unified platform for managing metadata, automating PII classification, improving data lineage, and setting up consistent data quality tests.
With just six data team members, Thndr managed governance at enterprise scale, protecting data across more than 3 million user accounts. Automated PII detection and metadata management significantly reduced manual work and improved trust in the data powering investment decisions. These changes helped the team scale governance efficiently while keeping data accuracy and compliance at the centre of their growth.
For more case studies, please refer to the documentation18.
Resources to learn

Source code19: git repository for exploring and contributing to OpenMetadata.
Documentation20: Comprehensive guides and references covering installation, configuration, and usage.
Medium21: Articles on OpenMetadata updates, features, case studies, and news.
Slack22: A highly responsive community for support, discussions, and Q&A.
LinkedIn23: Updates, news, meetup announcements, and community highlights.
YouTube24: Learning resources, workshop recordings, and meetup videos.
Meetups25: in-person and virtual events for networking, learning, and sharing knowledge.
X26: Quick updates, announcements, and community engagement.
Conclusion
Metadata isn’t just documentation; it’s the foundation of trust, collaboration, and scalability in any data-driven organisation. OpenMetadata brings that foundation to life by combining discovery, governance, quality, and collaboration in one unified platform.
Whether we’re a data engineer, analyst, or leader, investing in metadata management means fewer silos, fewer surprises, and faster insights.
We’ve enjoyed exploring OpenMetadata and hope our experience helps you on your own journey toward better data governance. If you’re considering trying it out, you can start with the sandbox for a quick hands-on experience or run it locally using Docker for more control and flexibility.
If you have any questions or want to share your experience, feel free to leave a comment or reach out, we’d love to hear how your team is managing metadata.
We value your feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Enjoy Pipeline to Insights? Please share it with others! Refer

3 friends and get a 1-month free subscription.
10 friends and get a 3-month free subscription.
25 friends and enjoy a 6-month free subscription.
Our way of saying thanks for helping grow the Pipeline to Insights community!
https://github.com/opendatadiscovery/awesome-data-catalogs/pulls
https://pipeline2insights.substack.com/t/interview-preperation
https://docs.open-metadata.org/latest
https://docs.open-metadata.org/latest/main-concepts/high-level-design
https://www.uber.com/en-AU/blog/metadata-insights-databook/
https://www.linkedin.com/in/sureshsri/
https://www.linkedin.com/in/sriharsha/
https://www.getcollate.io/comparison
https://www.getcollate.io/comparison
https://greatexpectations.io/
https://www.soda.io/
https://www.anthropic.com/news/model-context-protocol
https://docs.open-metadata.org/latest/quick-start/local-docker-deployment
https://docs.open-metadata.org/latest/deployment/kubernetes
https://docs.open-metadata.org/latest/deployment/bare-metal
https://open-metadata.org/case-study/carrefour-brazil
https://open-metadata.org/case-study/thndr
https://open-metadata.org/case-studies
https://github.com/open-metadata/OpenMetadata
https://docs.open-metadata.org/latest
https://blog.open-metadata.org/
https://openmetadata.slack.com/ssb/redirect
https://www.linkedin.com/company/openmetadata/posts/?feedView=all
https://www.youtube.com/@OpenMetadataChannel/about
https://www.meetup.com/openmetadata-meetup-group/
https://x.com/open_metadata
Spot on. Data governace is key, otherwise it's garbage in.