
Metadata: What it is and why do we need it?
Why Metadata is Essential for Efficient Data Engineering

A Data Engineer’s Nightmare: Lack of Metadata
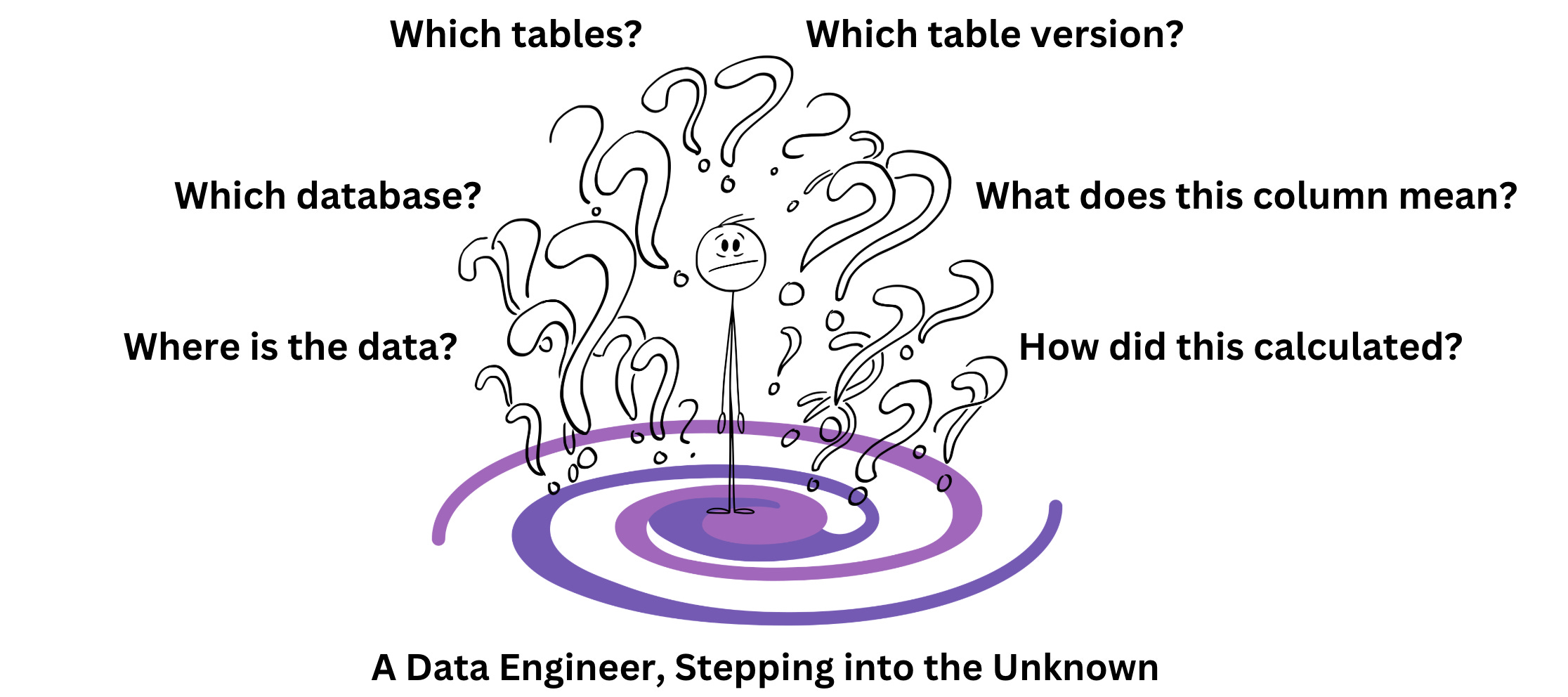
Imagine you've just joined a company as a Data Engineer (or a similar role). Your first task sounds exciting, build a Customer 360 view. This means bringing together details about customers, their quotes, the materials purchased for those quotes, the labour involved, and when everything was created. Simple enough, right?
You ask, "Where’s this data stored?"
They point you to the SQL server.
You log in and find around 40 databases, none of which have meaningful names. Unless you want to open every single one, you’ll need to ask someone where to look.
So you ask, "Which database has this data?"
They point you to AAU!
You open it and see… 3,276 tables. And countless views. None of them have descriptive names.
Alright, let’s narrow it down. "Which tables are related to quotes and customers?"
They tell you, "Look for tables starting with cq."
Great, except now you find multiple versions. Which ones are in use? Which ones are outdated? No one knows for sure.
And the story doesn’t end here.
You finally track down the tables, but now you’re staring at column names that make no sense. What does cust_flag_01 mean? How is qt_amt_adj calculated? You need business context.
So, you start hunting down the people who know. If you’re lucky, they’re still at the company. If not, their knowledge is locked away in undocumented spreadsheets, emails, or worse, inside their heads!
The more you learn about the data, the more questions you have and the more time you need to dig, ask, and piece things together.
But why does it have to be this hard?
Welcome to the world of metadata, or rather, the lack of it.
At this point, you might think we’re exaggerating. But we’re not. This is a real experience we’ve had multiple times in our roles. So,
Welcome to the world of metadata or the lack of it!
In today’s world, we generate and work with more data than ever before. To make sense of all this information and use it effectively, we need metadata. Think of metadata as a label or description that helps us understand what the data is, where it came from, and how it’s used. Just like libraries use metadata to organise books or art galleries use it to track paintings, metadata in data engineering helps us organise, search, and manage data.
In this post, We’ll cover:
What is metadata?
Key categories of metadata
Why metadata is crucial in today’s data-driven world
What is a data catalogue?
How to implement a data catalogue
Benefits of using a data catalogue
What Is Metadata

Modern data systems help organisations access more types of data and share them with more people. However, without good management powered by metadata, these systems can quickly become messy and unreliable.
Think of metadata as a tracking system for packages. When you ship something internationally, you want to know where it is and if there are any delays. Shipping companies use tracking numbers and records to monitor each package’s journey and ensure it reaches the right place.
Metadata does the same for data. As information moves within and between companies, tracking changes and fixing problems becomes difficult without a clear record of what happened. Even a small change, like renaming a column in a source table can affect hundreds of reports. Knowing this in advance helps prevent mistakes.
Metadata describes key details about data, such as its size, format, structure, last update, and who can access it. Storing metadata in one place helps teams quickly find and understand their data, making it easier to manage and use effectively.
In short, metadata is the map of your data. It keeps things organised, prevents problems, and ensures the right people can find and use the right data when they need it.
Key Categories of Metadata
Metadata can be classified into four categories:
Business Metadata
Technical Metadata
Operational Metadata
Reference Metadata
Let’s briefly delve into each of these categories:
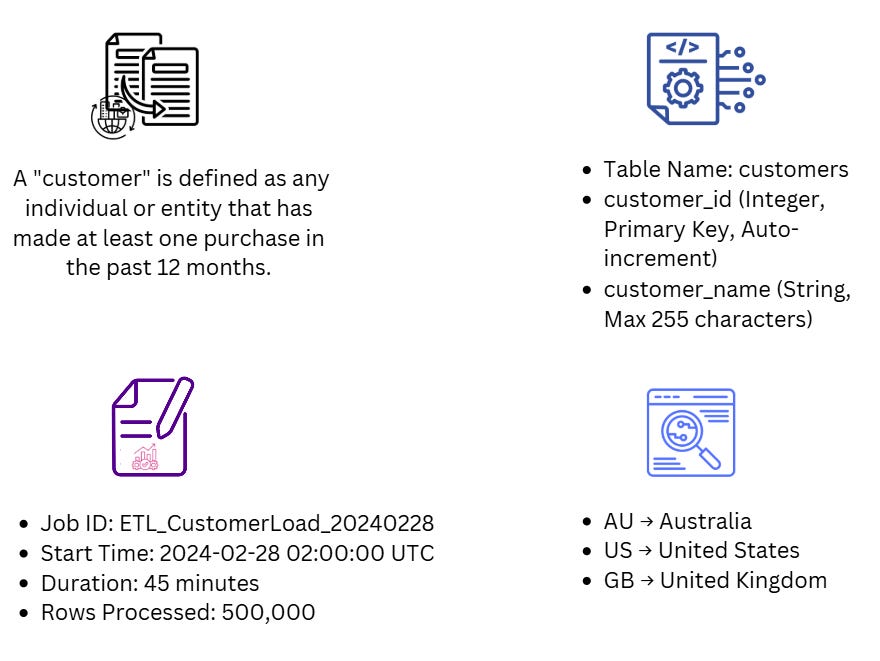
Business Metadata
Business metadata captures what data means to the end user. It helps make data fields easier to find and understand by reflecting their role within a business context. This includes definitions, rules, usage, and ownership.
For example, data engineers use business metadata to answer essential questions like "What is a customer?" This clarity ensures that data is used correctly and consistently across the organisation, aligning with business rules.
Technical Metadata
Technical metadata describes the form and structure of each dataset, covering details like schema design, data types, storage format (e.g. JSON, Avro), and constraints (e.g. field length, nullability).
It plays a crucial role throughout the data engineering lifecycle, helping teams understand how data is structured, processed, and stored. Common types of technical metadata include:
Pipeline Metadata: Generated by orchestration systems, this metadata details workflows, dependencies, configurations, and system connections.
Data Lineage: Tracks the flow and evolution of data as it moves through systems, providing an audit trail of transformations.
Schema Metadata: Defines the structure of data in storage systems like databases, data lakes, and cloud warehouses.
Operational Metadata
Operational metadata tracks how data moves and is processed. It includes details such as:
Job execution logs: Capturing timestamps, job IDs, and status updates.
Data lineage and provenance: Providing visibility into where data comes from and how it’s transformed.
Application and error logs: Helping diagnose issues and track system performance.
Data refresh schedules and rejected records: Ensuring transparency in data processing.
Data engineers rely on operational metadata for monitoring performance, troubleshooting issues, and ensuring the successful execution of processes. However, this metadata often resides in multiple systems, making it difficult to aggregate and analyse.
Reference Metadata
Reference metadata classifies and standardises data, acting as lookup information. Examples include:
Internal codes (e.g. product categories, customer segments)
Geographic codes (e.g. country or region identifiers)
Units of measurement (e.g. currency codes, weight units)
Calendar standards (e.g. fiscal years, time zones)
Reference data typically changes gradually over time and provides a stable framework for interpreting other datasets. While many organisations maintain their own reference metadata, some rely on external standards, such as international geographic codes.
Why metadata is crucial in today’s data-driven world?
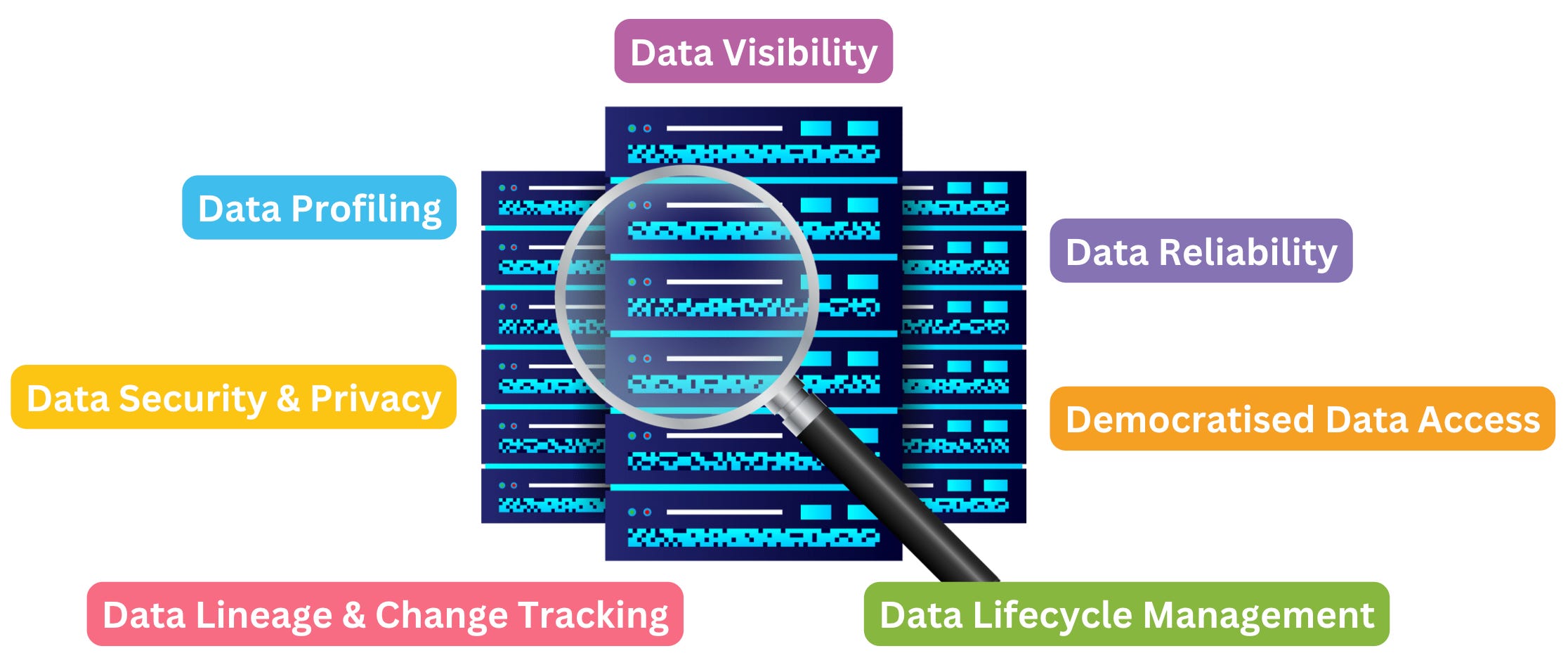
Metadata can be captured in different ways; it may be embedded within datasets, inferred from their content, or logged by processes that interact with the data. Regardless of its source, metadata is a key pillar of effective data lake management, enabling several crucial capabilities:
1. Data Visibility
Metadata helps track and organise data within a data lake or lakehouse, providing details about its source, format, and lineage. This visibility is essential for:
Impact analysis: Understanding how changes to a dataset affect downstream processes.
Change management: Keeping track of schema updates and data transformations.
Agile data platforms: Enabling quick discovery and integration of relevant datasets.
2. Data Reliability
Ensuring trustworthy data requires a balance of top-down governance (business-defined rules) and bottom-up feedback (user ratings on quality and freshness). Metadata enables organisations to:
Assess data reliability through automated checks and user-driven evaluations.
Improve collaboration by allowing teams to rate and annotate datasets based on their usability.
3. Data Profiling
Metadata allows data consumers (such as data scientists and analysts) to quickly assess datasets, understand their content, and detect anomalies.
Automated profiling at ingestion helps classify and tag data instantly.
On-demand profiling enables ad hoc analysis, improving data usability.
4. Data Lifecycle Management
Not all data needs to be stored forever. Metadata helps define rules for retention, archiving, and access, ensuring:
Efficient storage by prioritising high-value datasets.
Regulatory compliance by enforcing proper data retention policies.
5. Data Security & Privacy
Metadata supports access control, masking of sensitive data, and compliance with privacy regulations.
Security metadata annotations make audits easier and help highlight vulnerabilities.
Integration with governance frameworks ensures seamless enforcement of policies.
6. Democratised Data Access
Metadata powers searchable data catalogues, allowing users to find datasets based on business-relevant attributes rather than complex technical structures. This improves:
Self-service data discovery for business users.
Efficiency and usability across different teams.
7. Data Lineage & Change Tracking
Many organisations track only input and output metadata, but capturing metadata for intermediate processes provides:
Better transparency into how data is transformed.
Optimised data pipelines by identifying redundant or inefficient steps.
What is a Data Catalogue?
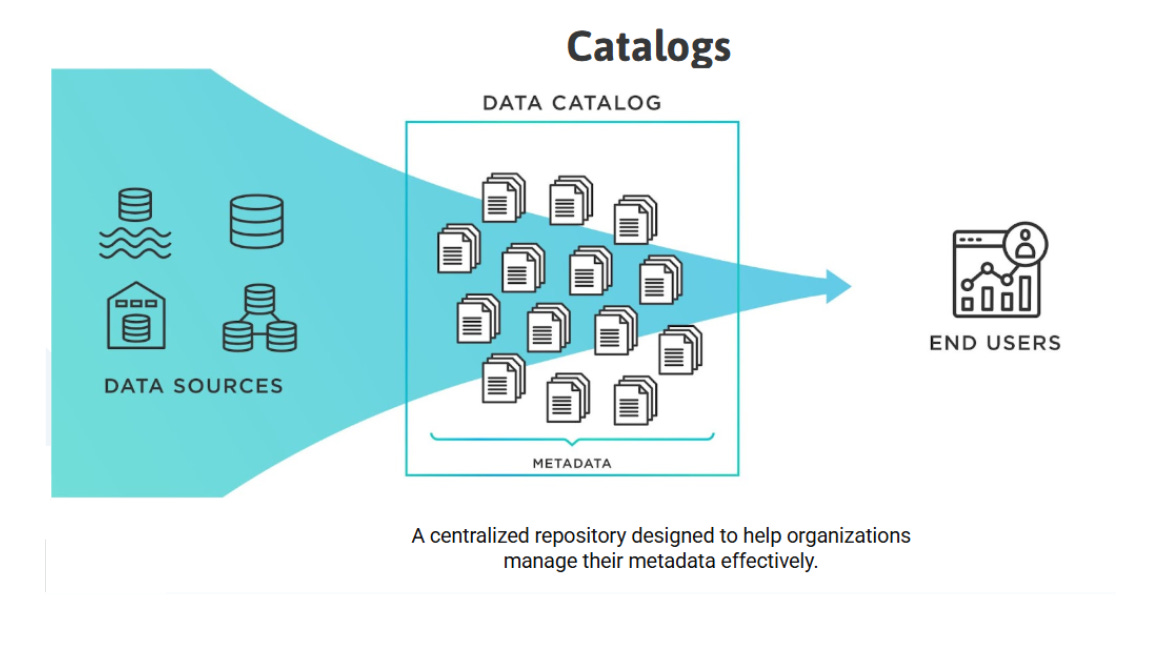
A data catalogue is a centralised repository that stores metadata about an organisation’s data assets. It helps users discover, access, and understand datasets, tracking their structure, lineage, and usage.
How Data Catalogues Have Evolved
Early data catalogues focused on basic metadata collection, such as tables, columns, and schemas, providing a static inventory of available data. However, modern data catalogues go beyond simple storage, they integrate metadata across the entire data ecosystem, making it actionable and enabling better data discovery, governance, and collaboration.
The focus is no longer just on collecting and storing metadata but on activating it, and embedding metadata into various parts of the data infrastructure to enhance usability, compliance, and decision-making.
Key Features of Modern Data Catalogues
A data catalogue organises and inventories data assets, including:
Tables and columns: Structured metadata from databases.
Pipelines: Data movement and transformation workflows.
Dashboards and reports: Analytical outputs tied to datasets.
Data lineage: A visual map showing how data flows and transforms.
Business glossaries: Definitions and context for key terms.
For data engineers, a data catalogue plays a crucial role in:
Managing metadata efficiently.
Maintaining data integrity across systems.
Ensuring smooth integration between operational and analytical workflows.
By consolidating metadata in one place, data catalogues enhance transparency, improve governance, and help teams make informed decisions.
Implementing a Data Catalogue
1. Selecting the Right Tool
Choosing a data catalogue tool depends on your organisation’s needs and available options, including open-source and enterprise solutions such as:
Apache Atlas
Collibra
Alation
Key factors to consider:
Compatibility with existing systems.
Scalability to handle growing data needs.
Ease of use for both technical and business users.
Support for governance features like access control and compliance tracking.
Want to explore different data catalogue tools? Check out this curated repository of solutions.
2. Integrating with Existing Systems
A successful data catalogue implementation starts with:
Assessing current data sources and workflows to identify integration points.
Establishing secure connections to ensure smooth data access.
Configuring metadata collection settings for automation and compliance.
Ensuring alignment with governance policies for consistency across teams.
By embedding the catalogue into daily workflows, teams can maximise its value while maintaining data accessibility and consistency.
3. Driving Adoption and Engagement
A data catalogue is only useful if people actively use it. To encourage adoption:
Train stakeholders on how to use it effectively.
Demonstrate its value through real-world use cases.
Embed it into workflows so teams naturally rely on it.
Provide ongoing support and address feedback to ensure long-term engagement.
Benefits of Using Data Catalogs
Easy Data Discovery: Data catalogues help teams quickly find and understand data assets.
Root Cause Analysis: They assist in identifying the cause of issues by tracking data usage and metadata.
Metadata Management: Catalogs organise metadata, helping teams understand who used data and when, and what metadata is associated with it.
Centralised Control: Teams can manage processes, policies, and access from one centralised source. Data catalogues can also track data quality issues and missed SLAs.
Data Lineage: Most catalogues use data lineage to map relationships between data assets, showing how they connect at both the table and column levels.
Conclusion
Metadata is the foundation of efficient data management, enabling visibility, governance, security, and accessibility across modern data ecosystems. Without it, organisations risk data chaos, making discovery, compliance, and decision-making far more difficult.
Investing in metadata is not just about organisation, it’s about maximising the value of data and ensuring that teams can find the right data, at the right time, with confidence.
If you found this post helpful, you might also enjoy these posts where we explore data engineering concepts!



If you are interested in learning how Google manages terabytes of metadata for BigQuery check out:
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Resources
Understanding Metadata, Creates the Foundation for Scalable Data Architecture by Federico Castanedo and Scott Gidley
Fundamentals of Data Engineering: Plan and Build Robust Data Systems by Joe Reis and Matt Housley
DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition: Data Management Body of Knowledge
What is a Data Catalog? Everything You Need to Know in 90 Seconds
Master AI-Ready Data Infrastructure by Chad Sanderson