
Data Serialisation: Choosing the Best Format for Performance and Efficiency
Understanding Row-Based vs. Columnar Formats and Their Impact on Performance

Data engineers working in the cloud may not always manage object storage directly, but understanding serialisation and deserialisation formats is crucial for optimising data storage, query performance, and system interoperability. Choosing the right format:
Reduces storage costs
Improves query execution
Ensures smooth data exchange across systems
This knowledge is essential for building scalable and efficient data pipelines.
In this post, we will:
Define the two main categories of file formats: row-based and column-based.
Explore their use cases, advantages, and limitations.
Provide examples of common file formats for each category.
Additionally, hybrid serialisation technologies, combining multiple serialisation methods or incorporating schema management are becoming increasingly important in modern data systems. In future posts, we'll dive into examples like Apache Hudi, Apache Iceberg, and other hybrid solutions.
Row-Based vs. Columnar Serialisation
Row-Based

Definition
It stores data by keeping each row as a separate unit, with all its columns grouped together.
Use Case
It works best for tables with a small number of columns and access patterns that require retrieving most or all columns per row.
Databases like MySQL, SQLite, SQL Server, and PostgreSQL use row-based storage by default, making them well-suited for transactional systems (OLTP) that involve real-time data processing and complex queries on individual records.
Advantages
Efficient for transactional operations: Row-based storage is optimised for transaction-oriented operations where you often need to access and modify entire records, such as inserting new customer details or updating an order.
Simple data access: Accessing a complete record is straightforward, making it easy to handle operations like adding or updating rows.
Limitations
Inefficient for Analytical queries: When performing analytical queries that only require specific columns, row-based storage can be inefficient since it reads entire rows, including unnecessary data.
Storage space: Row-based storage might use more space if not optimised properly, as entire rows are stored together, including any unused or redundant data fields.
Slow Schema Changes: Adding a new column updates all rows in the table, which can be time-consuming, especially with large datasets.
Common types
CSV(Comma-Separated Values)
Store tabular data in a simple text format, with a header row defining column names. They are widely used for data exchange because they are human-readable, easy to process, and supported by most applications.
While CSV files can represent relationships using foreign keys across multiple files, the format itself does not enforce these connections. They also lack built-in data types, have limited support for special characters and binary data, and can use different separators like tabs or spaces instead of commas.
XML (Extensible Markup Language)
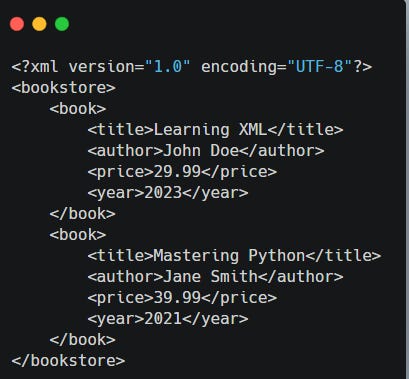
It was widely used in the early days of the internet alongside HTML but is now considered a legacy format. It is generally slow to serialise and deserialise, making it less efficient for modern data engineering tasks. However, data engineers still encounter XML when working with legacy systems and integrations.
Today, JSON has largely replaced XML as the preferred format for plain-text object serialisation due to its simplicity and efficiency1.
JSON (JavaScript Object Notation)
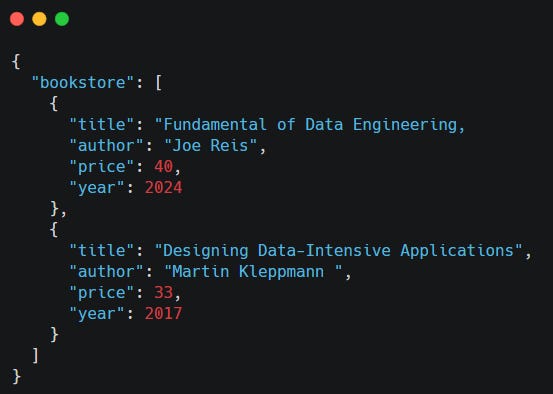
stores data as key-value pairs in a hierarchical format, making it ideal for representing complex relationships. It is widely used in network communication, especially in REST-based web services, and is more lightweight than XML.
JSON allows for storing related data in a single document and is supported by most programming languages with built-in serialisation tools. However, it consumes more memory due to repeated column names, has poor support for special characters, lacks indexing, and is less compact than binary formats. JSON is commonly used in NoSQL databases like MongoDB, Couchbase, and Azure Cosmos DB.
JSONL (JSON Lines)
Stores data as separate JSON objects on each line, making it easy to process large datasets efficiently. It’s ideal for streaming, logging, and machine learning but lacks schema enforcement and can be inefficient for deeply nested data.
Apache Avro
stores data in a compact binary format while keeping the schema in JSON. It supports schema evolution, making it easy to handle data changes over time. Avro files are splittable, compressible, and well-suited for big data storage in the Hadoop ecosystem. However, Avro data is not human-readable, requires careful schema design, and is not supported in all programming languages.
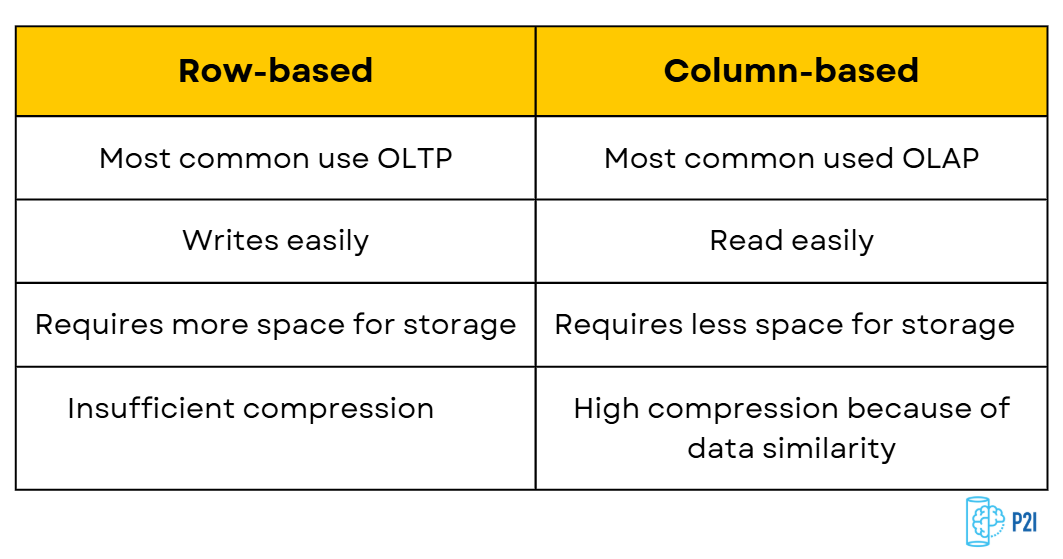
Summary

Columnar-Based

Definition
It stores the values of each column together, rather than storing the values of each row together.
Use Case
They are ideal for data warehousing and analytics where queries often focus on specific columns rather than entire records. For example, calculating the average sales per employee requires reading only the sales column, significantly improving performance compared to row-based storage.
Redshift, BigQuery, and DuckDB all use columnar storage for faster read operations.
Advantages
Great for Big Data: Columnar databases are ideal for big data applications, as they handle large datasets efficiently.
Highly Compressible: Data can be compressed effectively, enabling faster operations like AVG, MIN, and MAX.
Faster Analytical Queries: Queries run much faster compared to traditional row-based databases.
Self-Indexing: They automatically index data, reducing disk space usage compared to relational databases.
Limitations
Retrieving all columns takes a significant amount of time.
Restoring data after a failure can be more difficult compared to row-based storage.
Common Types
PARQUET
It is designed for efficient data storage and retrieval. It provides high-performance compression and encoding schemes to handle complex data in bulk and is supported in many programming languages and analytics tools. Parquet files support highly efficient compression and encoding schemes, resulting in a file optimised for query performance and minimising I/O operations.
If you're interested in learning more about Parquet, we recommend checking out "I Spent 8 Hours Learning Parquet – Here’s What I Discovered" by Vu Trinh.
ORC (Optimised Row Columnar)
Is a highly compressed, columnar storage format optimised for Big Data, reducing data size by up to 75%. It significantly boosts performance in Hive but is best suited for batch processing. However, ORC has limitations, it does not support schema evolution, and adding new data often requires recreating files.
APACHE ARROW
Is a fast in-memory data format for analytics. Unlike traditional methods, it avoids the extra steps of converting data before processing, making it much quicker. It stores data in columns, which speeds up analysis and reduces memory use. Arrow also works smoothly across different programming languages like Python, Java, and C++, making it a key tool in big data systems like Apache Spark and Dremio.
Summary

Conclusion
Understanding serialisation formats is essential for data engineers to enhance performance, cut storage costs, and ensure smooth data exchange across systems. The right format choice can significantly boost data processing efficiency, especially in cloud environments.
When deciding between row-based and column-based storage, it's important to consider your use case. Row-based storage is best for transactional systems with frequent updates and inserts, while column-based storage shines in analytical tasks that involve large-scale data scans and aggregations.
If you found this post helpful, you might also enjoy these posts where we explore common data engineering concepts!



We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!
Fundamentals of Data Engineering: Plan and Build Robust Data Systems by Joe Reis and Matt Housley