
Pandas vs. Polars: Benchmarking Dataframe Libraries with Real Experiments
Comparing functionalities, performances and usabilities of Pandas and Polars

Anyone working with Python and data knows Pandas. It has been the de facto standard for handling tabular data for years, allowing everything from quick exploratory analyses to complex data pipelines. Whether you're an analyst, data scientist, or engineer, you've likely used Pandas.
Recently, you may have heard more about Polars, a rising DataFrame library in the data community. Built with Rust for high performance, Polars is designed to process data faster and more efficiently, especially as dataset sizes increase.

The purpose of this post is to compare Pandas and Polars, focusing on their functionalities, performance, and real-world applications. Instead of lengthy definitions, we will discuss their practical usage and compare them across key areas:
Performance: Speed and memory efficiency when handling large datasets.
Scalability & Parallelism: How well they handle multi-threaded and large-scale processing.
Ecosystem & Compatibility: Integration with other tools and frameworks.
Practical Recommendations: When to use Pandas, when to use Polars, and whether you should consider switching.
Quick Overview of Both Libraries
Before diving into a detailed comparison, here’s a high-level overview of both, highlighting their key features, execution models, and common use cases.
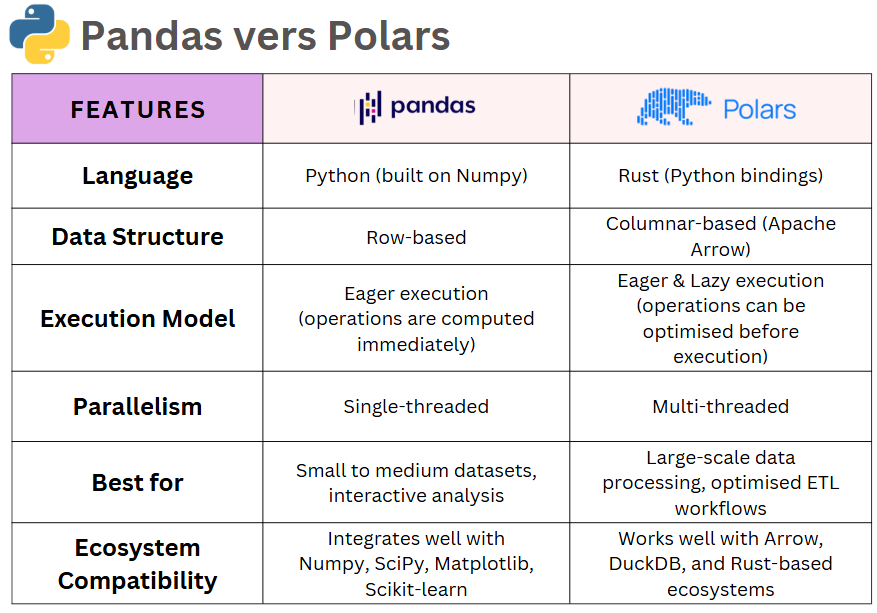
Both libraries offer powerful data manipulation capabilities, but Polars’ design prioritises performance and scalability, making it a strong alternative when working with large datasets.
Benchmarking and Performance Comparison
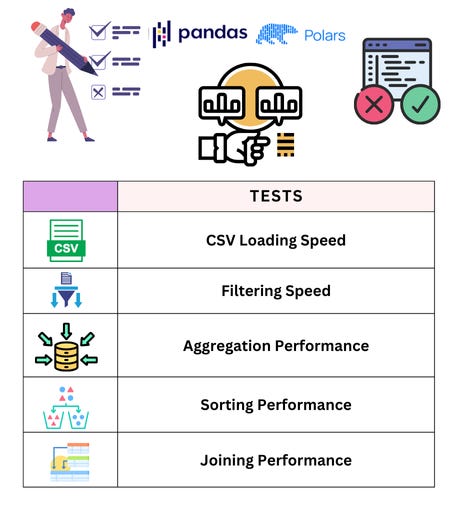
We'll run six key tests to evaluate the performance of Pandas vs. Polars:
CSV Loading Speed: Measure the time to read a CSV file(~1GB).
Filtering Speed: Select a subset of rows based on conditions.
Aggregation Performance: Compute group-wise sum and mean.
Sorting Performance: Sort a dataset by a column.
Joining Performance: Merge two datasets using a common key.
Note: All the codes ran by using Python 3.13.2 and Macbook Pro with M2 Chip and 8GB memory.
Benchmark Data
Total Rows: ~20 million
File Size: ~1GB (chosen to show performance differences even in relatively small datasets that may be common for data frame use cases since in large datasets polars’ performance superiority is well-proven)
Columns:
id: Unique identified (integer)
category: Categorical column (A/B/C/D)
value: Random float values (0-100)
timestamp: Generated datetime values
1. CSV Loading Speed
We'll measure execution time and memory usage for loading the CSV file.
Before jumping into comparison, we also write a short function to keep track of the memory usage of the operation.

Script using Pandas:
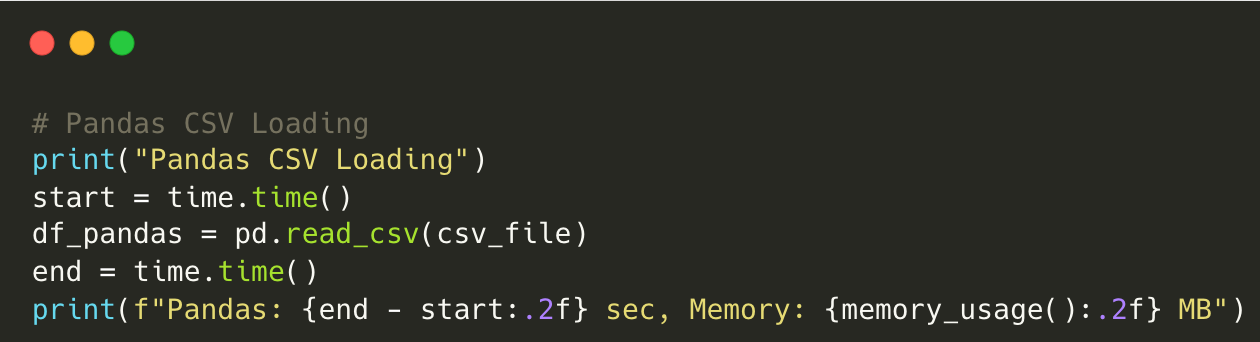
Output for Pandas:
Pandas CSV Loading
Pandas: 11.50 sec, Memory: 1404.86 MBScript using Polars:
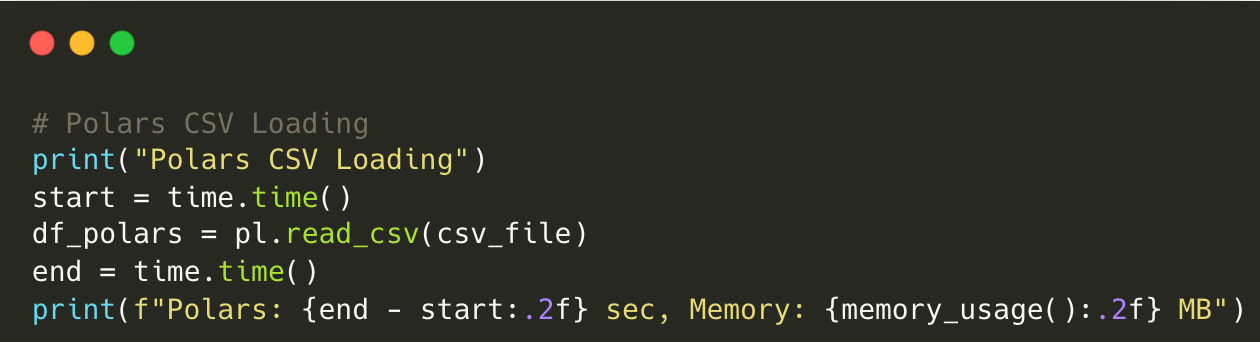
Output for Polars:
Polars CSV Loading
Polars: 2.33 sec, Memory: 179.19 MBComparison
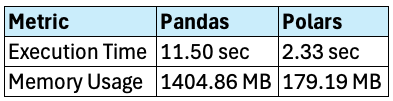
Polars is 5x faster than Pandas when loading a 1GB CSV file.
Memory consumption is way lower with Polars, using only 179MB compared to 1.4GB in Pandas.
2. Filtering Performance
We'll measure execution time for filtering rows where the value column is greater than 50. We will run the scripts 10 times and then consider the averages to make the comparison more fair.
Script using Pandas:
Output for Pandas:
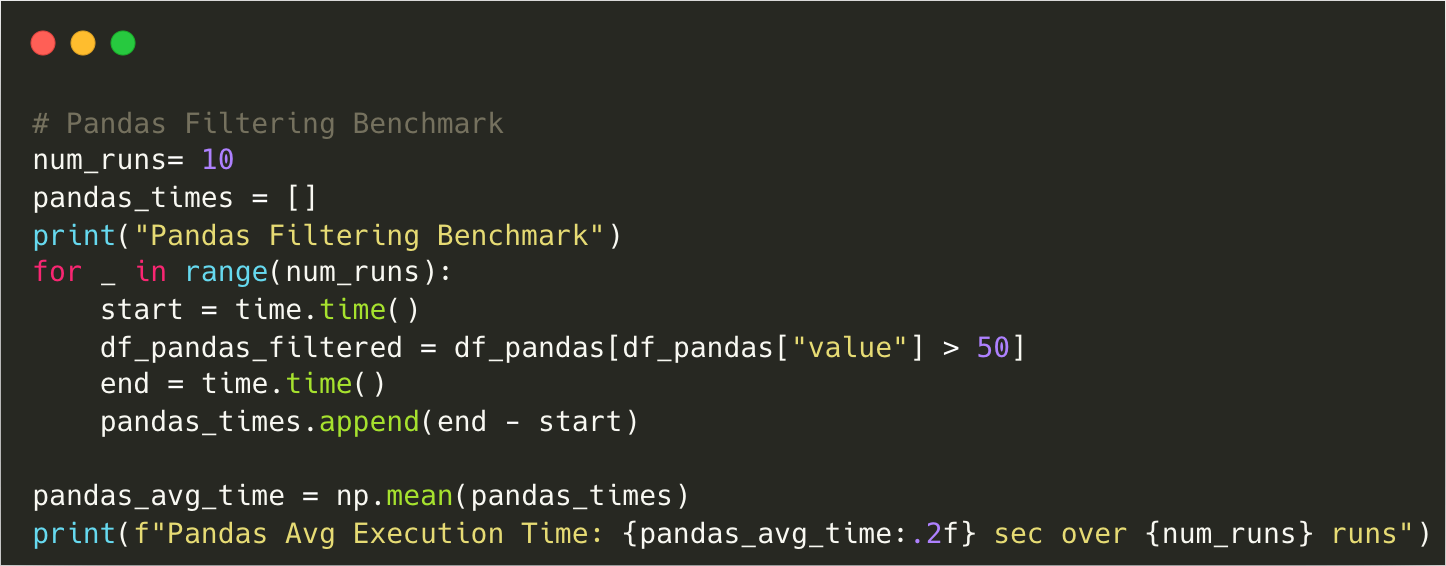
Pandas Filtering Benchmark
Pandas Avg Execution Time: 0.83 sec over 10 runsScript using Polars:
Output for Polars:
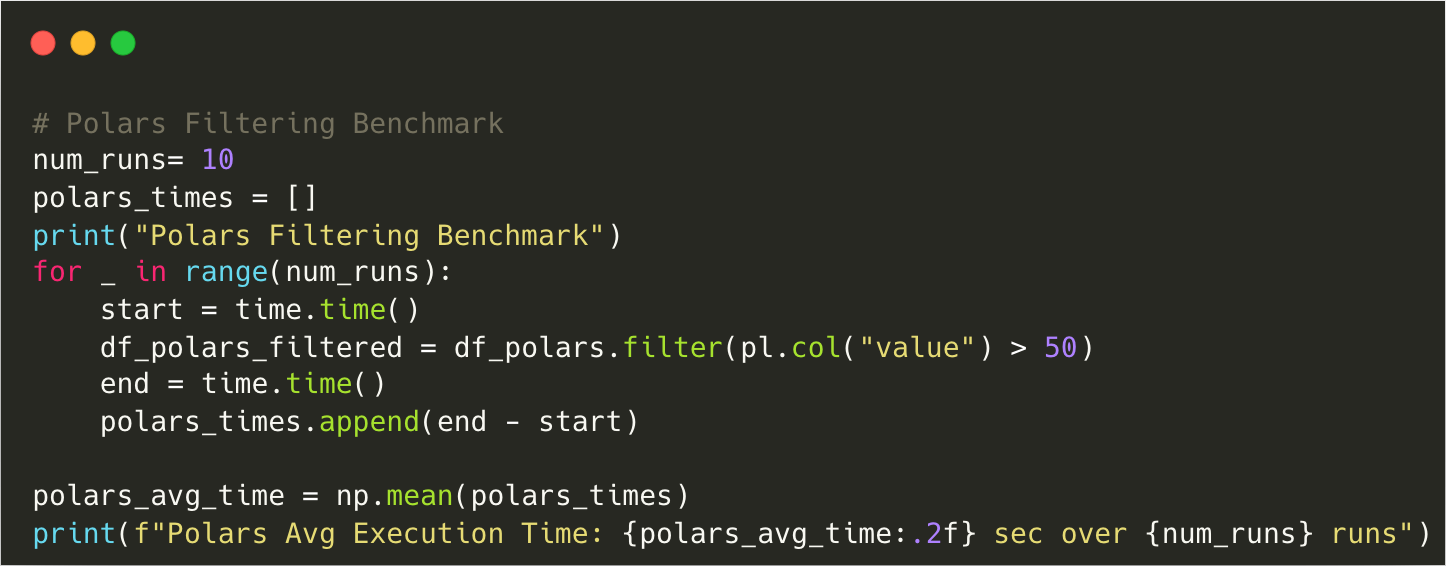
Polars Filtering Benchmark
Polars Avg Execution Time: 0.18 sec over 10 runsComparison
Polars is 4.6x faster than Pandas when filtering rows in a 1GB dataset.
The multi-threaded execution of Polars significantly speeds up row selection.
If you frequently filter large datasets, Polars provides a massive performance boost, making it an excellent choice for fast data transformations.
3. Aggregation Performance
We'll measure execution time for grouping by the category column and calculating the sum and mean of the value column.
Script using Pandas:
Output for Pandas:
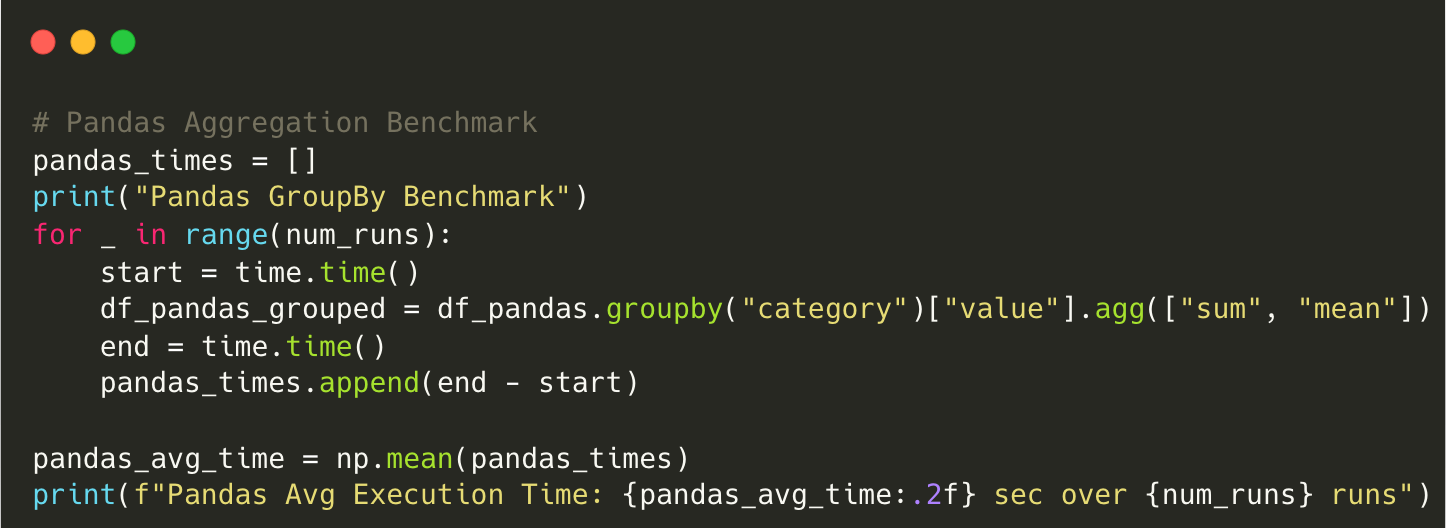
Pandas GroupBy Benchmark
Pandas Avg Execution Time: 0.54 sec over 10 runsScript using Polars:
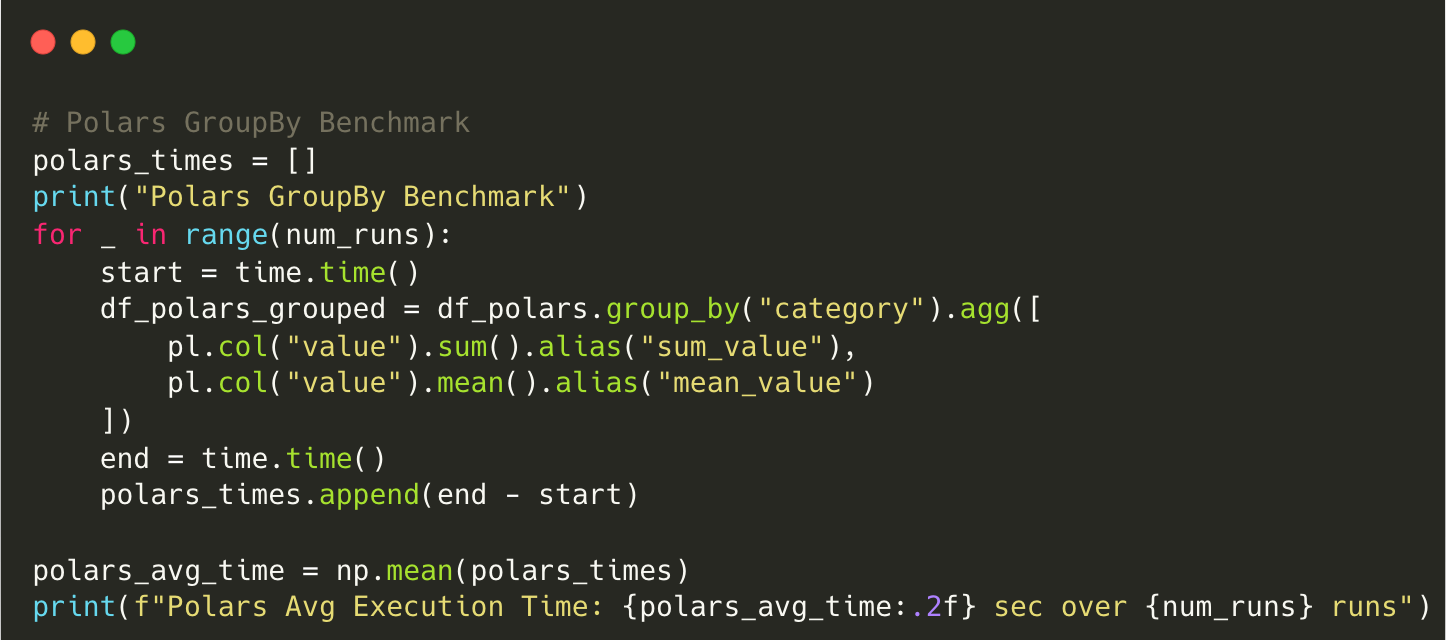
Output for Polars:
Polars GroupBy Benchmark
Polars Avg Execution Time: 0.21 sec over 10 runsComparison
Polars is 2.6x faster than Pandas for grouping and aggregating a large dataset.
Multi-threaded execution in Polars speeds up aggregations by parallelising computations.
Pandas also handles small aggregations pretty well.
4. Sorting Performance
We'll measure the execution time for sorting the dataset by the value column in descending order.
Script using Pandas:
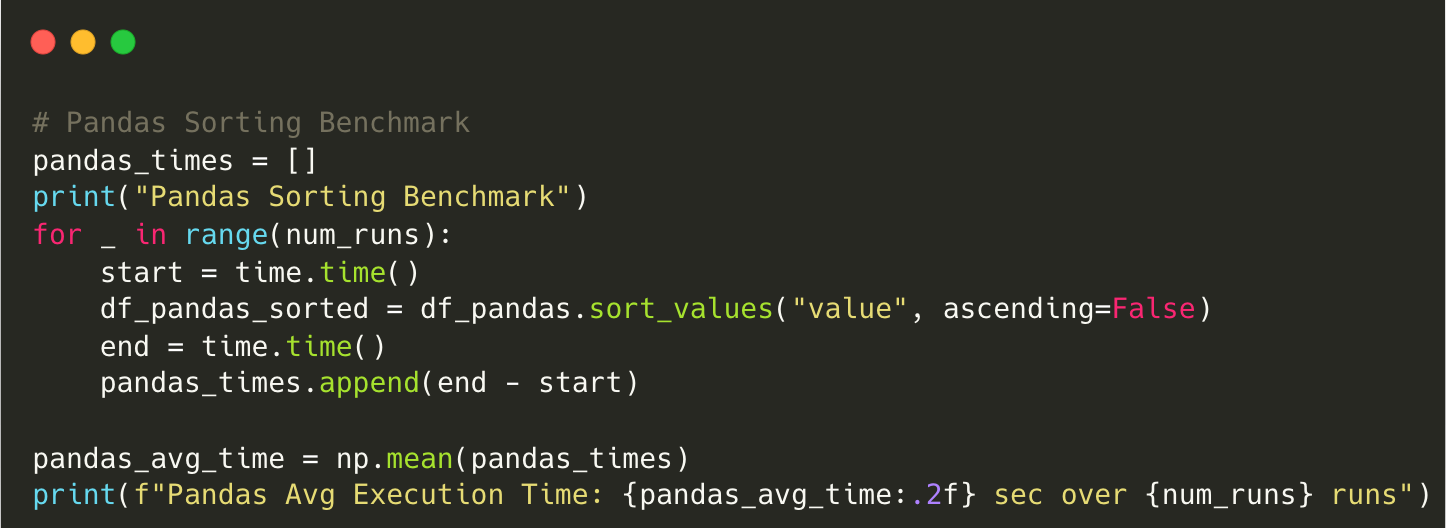
Output for Pandas:
Pandas Sorting Benchmark
Pandas Avg Execution Time: 18.93 sec over 10 runsScript using Polars:
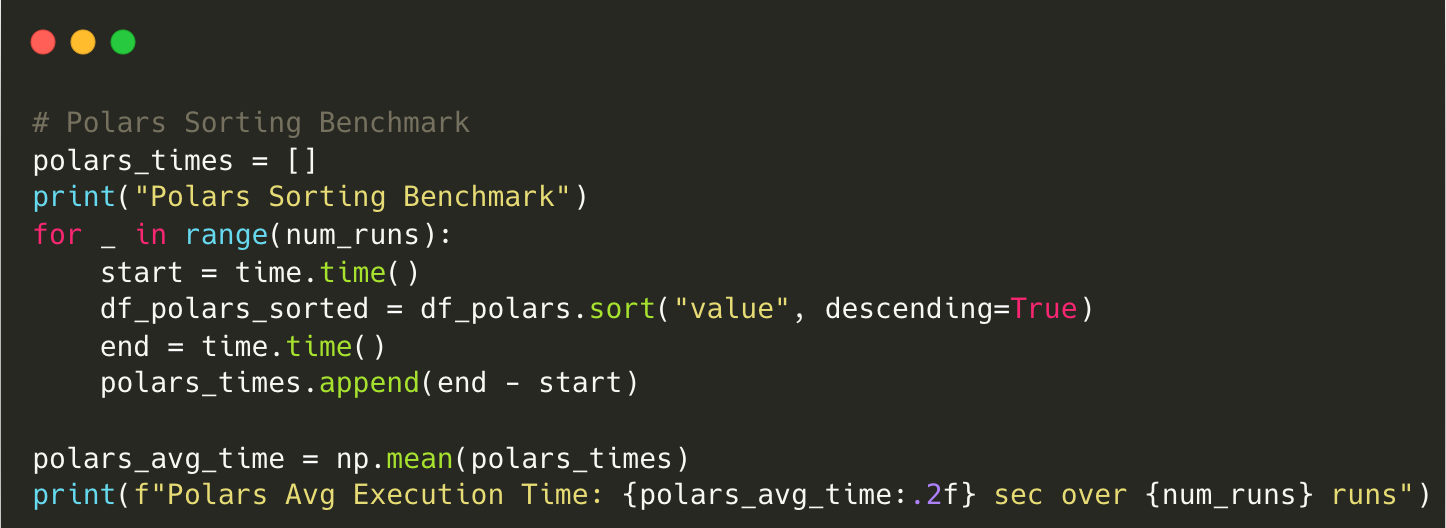
Output for Polars:
Polars Sorting Benchmark
Polars Avg Execution Time: 1.62 sec over 10 runsComparison
Polars is 11.7x faster than Pandas for sorting operations.
Sorting is one of Pandas’ biggest bottlenecks, as it uses single-threaded execution.
The combination of columnar storage and multi-threading allows Polars to outperform Pandas significantly in sorting operations.
Sorting is one of the most computationally expensive operations in Pandas. Polars dramatically reduces execution time, making it a far better choice for workloads that require frequent sorting.
5. Join Performance
We will measure the execution time for joining two datasets on the id column.
Datasets:
Main dataset:
test_dataset.csv(~1GB, 20 million rows)Join dataset: A random sample of 1 million rows from the main dataset
Script using Pandas:
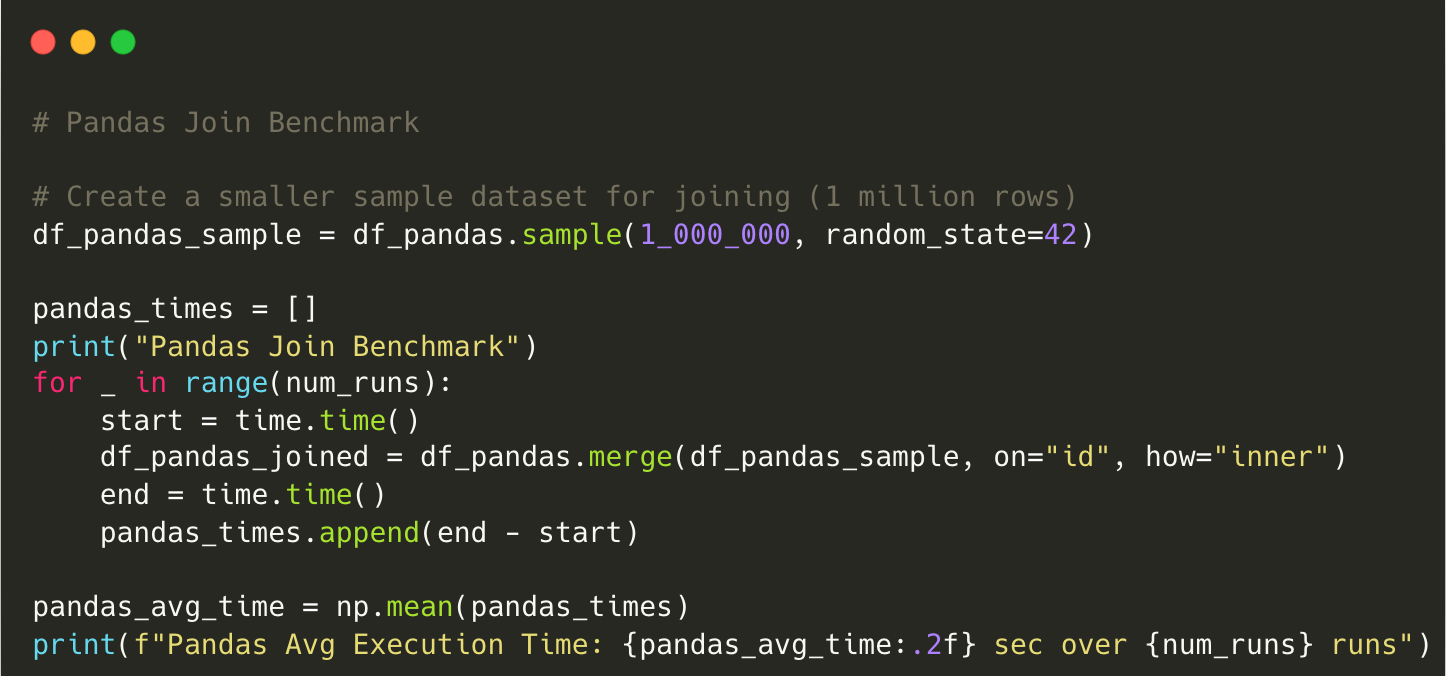
Output for Pandas:
Pandas Join Benchmark
Pandas Avg Execution Time: 1.79 sec over 10 runsScript using Polars:
Output for Polars:
Polars Join Benchmark
Polars Avg Execution Time: 0.50 sec over 10 runsComparison
Polars is 3.6x faster than Pandas when performing an inner join on a 10M-row dataset.
Polars’ parallel hash join outperforms Pandas’ row-wise merge, reducing execution time.
Benchmark Results Summary
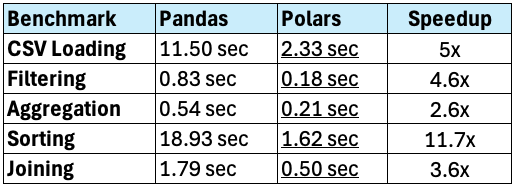
Polars is significantly faster than Pandas across all tested operations.
For small datasets, Pandas is still convenient and widely supported, but for scalability & performance, Polars is the better choice.
Also don’t forget, Polars scales better as dataset size increases. Therefore, we usually expect the speedup to grow with the dataset size.
When to Use Pandas vs. Polars
So, should we all use Polars for everything?!
Although Polars outperforms Pandas in our benchmarks, the choice between the two depends on factors like context, dataset size and use case. Polars is built for high performance and scalability, while Pandas continues to be the go-to library in data science due to its maturity and extensive ecosystem.
Despite Polar’s performance, Why hasn’t it replaced pandas yet?
While Polars outperforms Pandas in every benchmark we tested, it hasn’t yet replaced Pandas as the standard DataFrame library for a few key reasons:
Ecosystem & Adoption: Pandas has a larger user base, broader adoption, and deeper integration across Python libraries.
Lack of Full API Parity: While Polars covers most Pandas functionality, not all operations are identical, meaning some code might require rewriting to work with Polars.
Better Support for Small Interactive Workflows: Pandas is good enough for small to medium-sized datasets.
Maturity & Documentation: Pandas has years of accumulated knowledge, while Polars is still relatively new and lacks the same level of documentation and third-party support.
When to Use Pandas
Pandas is still the go-to choice for many tasks, especially in data science, interactive analysis, and smaller datasets where performance isn't a major bottleneck.
Exploratory Data Analysis (EDA): If you’re working in Jupyter Notebooks, Pandas offers a rich ecosystem, intuitive syntax, and deep integration with plotting libraries like Matplotlib and Seaborn.
Data Science & Machine Learning Workflows: Pandas integrates seamlessly with libraries like NumPy, SciPy, Scikit-learn, and TensorFlow, making it the preferred choice for feature engineering and preprocessing.
Small to Medium-Sized Datasets: If your dataset comfortably fits in memory, the performance difference may not be enough to justify switching to Polars.
Well-Established Ecosystem: Pandas has been around for over a decade, meaning extensive documentation, countless tutorials, and broader community support.
When to Use Polars
Polars is built for performance, and its advantages become much clearer as datasets grow larger.
Large Datasets: The bigger the dataset, the more you’ll benefit from Polars’ parallel execution and memory efficiency. While Pandas performance degrades as dataset size increases, Polars scales efficiently.
ETL Pipelines & Data Engineering: If you’re processing large amounts of data before storing it in a database, warehouse, or cloud storage, Polars' faster read, filter, and aggregation capabilities make it ideal.
Batch & Real-Time Processing: Since Polars leverages multi-threading, it’s a better fit for real-time analytics, streaming data pipelines, and batch jobs where Pandas' single-threaded approach would become a bottleneck.
Memory Constraints & Cloud Environments: If you’re working with limited memory resources, Polars' Apache Arrow-based format is much more memory-efficient, preventing unnecessary overhead.
Conclusion
In this post, we explored the performance differences between Pandas and Polars across key data operations. Through our benchmarks, we saw that Polars consistently outperforms Pandas, often by several times, thanks to its multi-threaded execution and columnar storage.
We also discussed when to use Pandas vs. Polars, highlighting that while Pandas remains the go-to choice for interactive analysis and small datasets, Polars excels in large-scale data processing, ETL pipelines, and performance-critical tasks.
If you found this post helpful, you might also enjoy these posts where we explore data engineering concepts!



Certainly telling us Polars believers what we already know, but this was a great breakdown. Pandas has certain functions that sometimes beats it out (date times come to mind), but I honestly can’t imagine using Pandas ever again.
Hi, thanks for the great work. Is there a plan to compare Polars to PySpark?