
Storage Fundamentals for Data Engineers
From the storage hierarchy to cloud storage types, what every data engineer needs to know to choose the right solution and interact with it.

When I first joined a company as their very first data engineer, I was excited. I had been working with cloud data warehouses like Snowflake and had just completed a Databricks course. Naturally, I was eager to apply the newest tools I’d learned.
My manager gave me full freedom to decide on the data architecture. At first, I almost convinced myself to jump straight into Databricks, after all, it seemed to have everything all in one. But then I paused and asked myself: Am I choosing the right tool for the problems we actually have?
In my company, there was only a single database handling both transactions and analytics. Did we really need a full lakehouse architecture right away? Or would a simpler setup, like using a replica of the production database and ingesting data into a single warehouse for analytics, be enough for now?
That reflection pushed me back to the fundamentals of data storage and reminded me that the “right” solution depends on the actual problems we’re solving.
Storage is at the heart of the Data Engineering lifecycle. It is fundamental to every stage of Data Engineering: ingestion, transformation, and serving. Data is stored multiple times throughout its lifecycle, ensuring it’s accessible for later processing whenever needed. The storage solutions we choose will impact everything from the cost to the performance to the end user experience of our data systems.
As data engineers, we usually think in terms of architectures rather than the details of data movement. But without a solid understanding of storage fundamentals, we risk creating bottlenecks, driving up costs, and wasting both time and resources.
In this post, we’ll build from the ground up and cover:
The storage Hierarchy
The three main types of cloud storage
How to choose the right storage solution?
The roles and responsibilities in data storage
This post is inspired by the Fundamentals of Data Engineering1 book by
and Matt Housley, as well as the DeepLearning.AI Data Engineering Professional Certificate2 by Joe Reis.The Storage Hierarchy
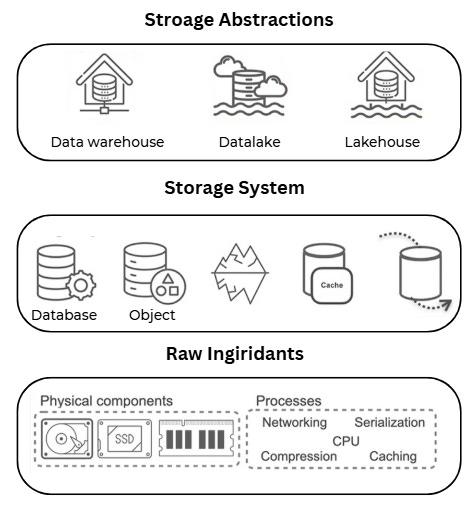
1. Raw Hardware Ingredients
As data engineers, we need to understand the performance, durability, and cost of these raw ingredients to choose the right one for each use case. Data moves through persistent storage (like HDDs or SSDs) and volatile memory (like RAM and CPU cache) as it flows through the pipeline.
Persistent Storage Medium:
Solid-State Storage (SSD): stores data in flash memory cells as electrical charges, where a charged cell represents a 1 and an uncharged cell represents a 0. Unlike hard disk drives, SSDs have no moving parts and instead use purely electronic processes to read and write data, making them much faster, quieter, and more reliable.
We can think of them like a giant USB stick that stores information on tiny electronic chips, though they are usually more expensive for the same amount of storage.
Magnetic disks: also known as hard disk drives (HDDs), store data on spinning platters coated with magnetic film and work much like old record players. A small read/write head moves to the correct track as the platter spins, with each platter divided into tracks and sectors that create unique addresses for storing and retrieving data. Writing occurs when the head changes the magnetic field to record 1s and 0s, while reading happens when it detects those fields and converts them into bits. Since they rely on moving parts, HDDs are slower and wear out more easily, but they are usually cheaper and well-suited for storing large amounts of data.

Volatile Memory
RAM: High-speed, temporary memory used to run applications. Data is lost when the power is off, and it’s more expensive than solid-state storage. For the CPU to process data efficiently, the data must first be transferred from persistent storage, such as SSDs or magnetic disks, into RAM. RAM is located close to the CPU and operates at significantly higher speeds than disk storage, enabling the CPU to access and process data quickly without being hindered by the slower read/write speeds of the disks.
CPU Cache: is a type of memory even faster than RAM, located directly on the CPU chip. It stores frequently used data so the CPU can access it almost instantly, with speeds up to a terabyte per second and delays of just a few nanoseconds.
Note: Understanding these performance and cost trade-offs enables data engineers to select the optimal storage technologies that meet the speed and efficiency requirements of their workloads.

Besides the physical hardware, some processes are required for storing and transmitting data in modern data systems:
Networking:
In modern and cloud storage systems, data is often distributed across multiple connected servers to improve speed, durability, and availability. Networking allows these servers to communicate, sending read and write requests back and forth, gathering pieces of a query from different servers, or splitting new data across them. Along with the CPU handling the details of servicing these requests, such as aggregating reads and distributing writes, networking is a key part of making distributed storage efficient and reliable.
Serialisation:
is the process of converting data in memory, optimised for the CPU, into a format that can be stored on disk or sent over a network, usually as a sequence of bytes. When the data is needed again, deserialisation reconstructs it back into usable structures. This process ensures data can move between memory, storage, and networks in a consistent and usable way.
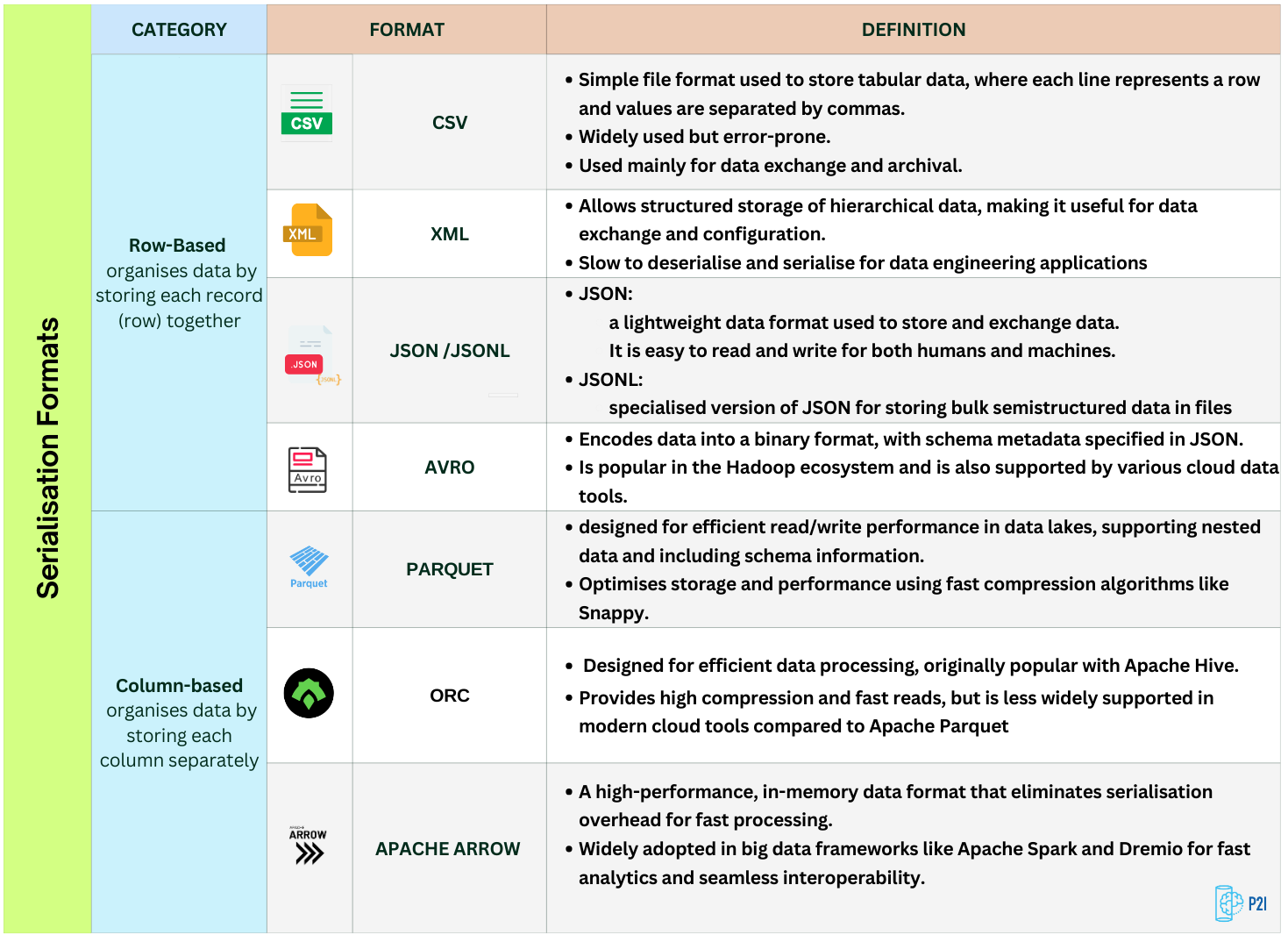
Depending on the use case, Data can be serialised in different ways:
Row-based: stores data record by record, with each consecutive sequence of bytes representing one row or object. This is ideal for transactional operations where entire rows need to be accessed at once.
Column-based: stores data column by column, with each consecutive sequence of bytes representing a column or a specific key across all objects. This format is better for analytical queries that operate on specific fields or columns.
Serialisation formats vary from human-readable text formats like CSV, XML, and JSON, to efficient binary formats like Avro and Parquet, which are optimised for storage and querying.
Note: Understanding serialisation is key to efficiently moving and storing data across memory, disks, and networks.
Want to learn more about serialisation? Check Data Serialisation: Choosing the Best Format for Performance and Efficiency.3
Compression:
Once our data is serialised and ready to store or transmit, data compression can reduce the number of bits needed to represent it, saving storage space and speeding up data transfer. Compression algorithms find patterns and redundancy in the data and encode it more efficiently, for example, by giving common characters shorter bit sequences than rare ones in text files like CSV, JSON, or XML. Beyond saving disk space, compression also improves performance by reducing the amount of data the system must read from storage during queries.
In this post, we cover comparison and its techniques in more detail:

2. Storage Systems (Databases and Object Storage)
We typically don’t interact directly with the physical storage components or processes. Instead, we interact with the storage systems that are built from those raw ingredients.
Databases are systematically organised collections of data, stored electronically, that allow for efficient storage, access, management, and analysis of information. They provide a structured way to store large volumes of data while supporting fast queries, updates, and reporting. Databases can be relational, organising data into tables with predefined schemas, or non-relational (NoSQL), storing data in flexible formats like documents, key-value pairs, or graphs.
A Database Management System (DBMS) is the software layer that manages our interactions with the database, handling tasks like query execution, data consistency, and access control.
If you’re keen to understand how a query runs behind the scenes, check out our “SQL Behind the Curtain” post for more details.

Object Storage is designed to store large amounts of unstructured data, such as files, images, videos, or backups, typically in the cloud (for example, AWS S3). We will explain more about object storage later in this post.
Note: As a Data Engineer, we will likely work with various storage systems and combine them into abstractions like data warehouses, data lakes, or data lakehouses.
3. Storage Abstractions (Data Warehouses, Data Lakes, Lakehouses):
As Data Engineers, we often work with various storage systems, combining them into higher-level abstractions like:
Data Warehouses are central database stores that store data from many different sources in a consistent, structured way so it can be used for reporting and analysis. Unlike production databases (OLTP) that are designed for fast transactions, a data warehouse is designed for analytical queries, combining current and historical data to help businesses make decisions.
Data Lakes are a central repository that stores all kinds of data, structured, semi-structured, and unstructured, at any scale. Unlike a data warehouse, it doesn’t require a fixed schema up front. Instead, we store the raw data as-is and decide on the schema later when reading it (schema-on-read).
Data lakes are usually built on top of low-cost object storage, making them ideal for handling massive volumes of diverse data such as logs, images, videos, and text.
Lakehouses combine the best of data lakes and data warehouses in a single system. It lets us store large volumes of raw, diverse data like a data lake, while also supporting fast analytics like a data warehouse. This eliminates the need to constantly move data between separate systems, reducing cost, complexity, and data quality issues.
With the storage abstraction tools, we’ll focus on configuring parameters to meet our needs for latency, scalability, and cost, rather than managing underlying storage details.
Now that we’ve covered Storage Hierarchy, including raw ingredients, storage systems and abstractions, we can look at how these come together in the cloud.
Three types of cloud storage
In the cloud, data is stored using three main types: file storage, block storage, and object storage, each designed for different purposes and use cases.
Each of these has its own strengths, weaknesses, and ideal use cases. Let’s break them down.
File Storage
It is the most traditional and widely used storage paradigm. If we’ve ever navigated folders on a laptop, you already understand it: files are organised in a hierarchical tree structure, with folders containing files, subfolders, and metadata such as names, owners, permissions, and timestamps.
To access a file, the system follows a path, for example: /user/ehesami/output.txt, starting at the root, locating the user folder, and finally retrieving the file.
In cloud environments, file storage is commonly used when multiple users or applications need shared access, simplicity and manageability matter, or centralisation is more important than raw performance.
Each file comes with metadata like size, permissions, and optional tags. Access is typically through network protocols such as NFS4 or SMB5.
Block Storage

It is a high-performance, low-latency storage system that splits data into fixed-size chunks called blocks, each with a unique identifier. These blocks, stored on SSDs or magnetic disks, can be retrieved and updated independently, making reads and writes fast.
Unlike file storage, block storage doesn’t manage files, folders, or metadata; it focuses solely on storing and retrieving raw data. We can think of it as a blank hard disk in the cloud: before use, it must be attached to a server, formatted with a file system (like ext46, NTFS7, or XFS8), and then managed at the OS level.
This type is ideal for workloads that require high performance, such as transactional databases, virtual machine disks, or low-latency applications. For example, Amazon EBS provides SSD-backed volumes for fast transactional workloads and magnetic-disk volumes for cost-efficient storage of infrequently accessed data.
Object Storage
This type is designed to store large amounts of unstructured data, such as files, images, videos, or backups
Unlike file or block storage, it stores data as immutable objects in a flat structure, with each object placed in a container (like an S3 bucket) and identified by a unique key. Once written, objects cannot be updated in place; changes require rewriting the entire object, removing synchronisation overhead and enabling high scalability and fault tolerance.
Object storage supports horizontal scaling to petabytes, replicates data across nodes for durability, and enables parallel reads and writes, which is critical for analytics. Examples include AWS S3, Google Cloud Storage, and Azure Blob Storage, which form the backbone of data lakes and cloud data warehouses.
If you want to learn more about these three types, check out File Storage vs Object Storage vs Block Storage9 by
.How to choose the right storage solution?
Selecting the right storage solution starts with understanding the characteristics of our data, its type, format, size, and how it will be accessed or updated by different stakeholders over time.
There is no one-size-fits-all solution; each storage option has unique strengths and weaknesses. With numerous technologies available, identifying the best fit for our data setup can be complex.
Key Engineering Considerations for Storage Systems

Performance: Ensure the solution meets required read and write speeds and avoids creating bottlenecks for downstream processes.
Scalability: Verify the system can scale to handle future capacity needs.
Accessibility: Ensure downstream users can access data within the required SLAs.
Metadata management: Capture metadata to enhance data management, tracking, and flexibility for future requirements.
Query support: Determine whether the system supports complex queries or is intended solely for storage.
Flexible Schema: Evaluate if the system offers flexible schemas or enforces strict schema designs.
Data quality and governance: Monitor master data quality, maintain data lineage, and sustain governance standards.
compliance: Consider regulatory requirements, including data residency and storage location rules.
When choosing a storage solution, we can use the guide below as a reference.
Roles and Responsibilities in Data Storage
As a data engineer working with storage, we will collaborate with people who own our IT infrastructure, including DevOps, security, and cloud architects.
Determining whether Data Engineers can independently deploy infrastructure or require other teams to manage these changes is critical. This ensures streamlined, efficient collaboration and minimises delays.
Our responsibilities will depend on the organisation’s level of data maturity:
Early-Stage Organisations: We’ll likely own the entire data storage setup and workflows, handling everything end-to-end. For example, we might:
Request a replica of the production database for analytics.
Spin up a server to host a database.
Choose a cloud storage solution that fits the company’s current needs.
From my own experience, the key is to start small and practical. When we join a company at an early stage of maturity, we should resist the temptation to jump straight to advanced platforms like Databricks or a full lakehouse architecture. Instead, ask:
Do we really need this right now?
What problems would a lakehouse solve that we’re actually facing today?
Often, simpler solutions are more effective early on.
Mature Organisations: Here, our role will be more specialised, focusing on parts of the data lifecycle and working with dedicated teams for ingestion, transformation, and governance.
For example:
We may join a company where the entire data platform is already in place, and our job is primarily to use it effectively.
We might not have the freedom to replace existing systems, but we can suggest improvements, optimise workflows, and bring best practices to enhance reliability and performance.

Conclusion
Understanding the storage hierarchy is crucial for data engineers who aim to optimise performance and manage costs effectively. From foundational hardware like SSDs and RAM to advanced concepts like data warehouses and lakehouses, mastering these elements can significantly impact our projects. This knowledge empowers us to make informed decisions, avoid performance bottlenecks, and design scalable, efficient systems that align with our organisation’s needs and future growth.
If you found this post valuable and want to stay updated on the latest insights in data engineering, consider subscribing to our newsletter.
You might also enjoy other posts about the Data Engineering Lifecycle here10.
If you’re preparing for data engineering interviews, check out this series11, covering everything from SQL, Coding, and Data Modelling to Data Architecture and behavioural questions.
Join the Conversation!
What are your experiences with the storage hierarchy in your data engineering projects? We’d love to hear your thoughts and insights. Share your experiences in the comments below and join the discussion!

Enjoy Pipeline to Insights? Please share it with others! Refer
3 friends and get a 1-month free subscription.
10 friends and get a 3-month free subscription.
25 friends and enjoy a 6-month free subscription.
Our way of saying thanks for helping grow the Pipeline to Insights community!
https://www.amazon.com.au/Fundamentals-Data-Engineering-Robust-Systems/dp/1098108302
https://www.deeplearning.ai/courses/data-engineering/
https://pipeline2insights.substack.com/p/row-based-column-based-serialisation-storage
https://aws.amazon.com/compare/the-difference-between-nfs-smb/
https://aws.amazon.com/compare/the-difference-between-nfs-smb/
https://docs.kernel.org/admin-guide/ext4.html
https://www.geeksforgeeks.org/operating-systems/ntfs-full-form/
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/7/html/storage_administration_guide/ch-xfs
https://blog.algomaster.io/p/file-vs-object-vs-block-storage
https://pipeline2insights.substack.com/t/data-engineering-life-cycle
https://pipeline2insights.substack.com/t/interview-preperation
Thank you!
Great breakdown of storage fundamentals! The comparison between HDDs and SSDs really hits home for anyone following companies like Western Digital. They've been navigating this transition for years, with SSDs becoming more affordable while HDDs still dominate for high-capacity, cost-effective storage in data centers. Your point about performance vs cost trade-offs is exactly what drives product decisions at WDC - they have to balance both markets while innovating in areas like NAND flash and enterprise storage. The section on serialization and compression is also key, since data center customers are increasingly focused on storage efficiency. Nice work making these concepts accesible!