


What is Data Architecture and why Data Engineers should consider it
Understanding the principles of Data Architecture and their importance

Every data engineer should understand data architecture, as they often play a role in key design decisions based on their team’s size and structure.
In startups or greenfield projects, engineers may build the entire system themselves. Even in companies with dedicated data architects, adopting an architectural mindset helps engineers make better decisions and excel in their roles.
While data engineers and data architects have distinct roles, engineers must understand architecture to implement designs effectively and provide valuable feedback.
In this post, we explore data architecture as a key part of the data engineering lifecycle, based on insights from the Fundamentals of Data Engineering book by Joe Reis and Matthew, Joe Reis' Data Engineering Professional on Deep Learning AI course, along with our own experience and research.
We will cover:
What is Data Architecture?
Nine principles of effective data architecture.
How to measure architectural success?
Designing Robust Data Architectures Across the Lifecycle
The Role of Data Engineers in Data Architecture
Curious about the rest of the Data Engineering Lifecycle series? Take a look at the other posts here1.
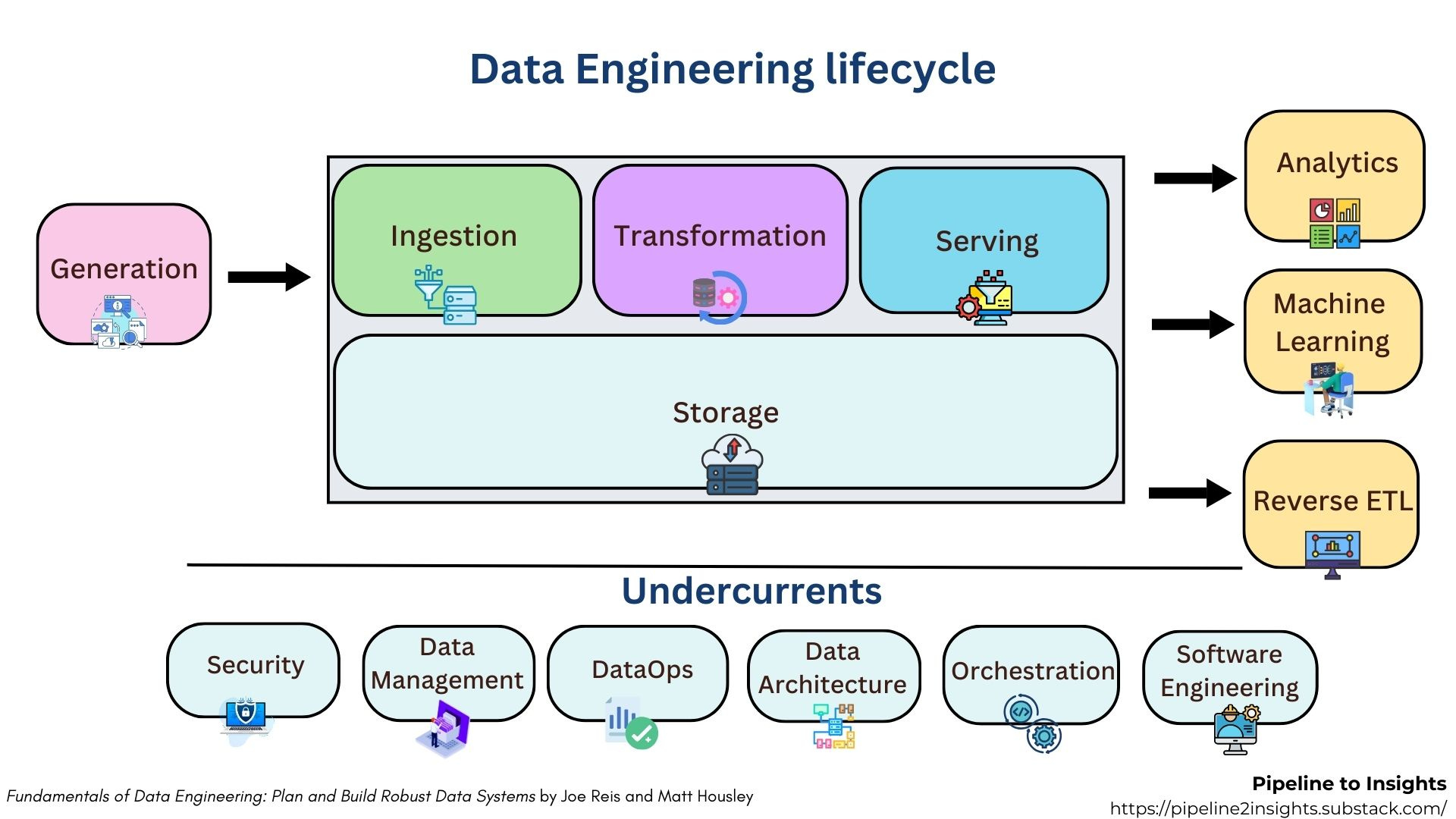
What is Data Architecture?
Data architecture serves as the essential roadmap for your data systems, guiding how information flows through your organisation.
According to Joe and Matt, data architecture is defined as:
“The design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs"
In a well-designed Data Architecture, there are some elements we should always be considering:
1. Supporting evolving needs

Effective data architecture doesn't just address today's requirements but anticipates tomorrow's challenges, making it an ongoing effort rather than a one-time project.
This element is extremely crucial in today’s fast-evolving environment. As engineers, we should always consider whether our decisions today will also be valid in the future, where the data maturity stage is different, the requirements are shifted, and the scale is larger. Of course, such considerations can change from business to business, but it is our role to consider the right scenarios without over-engineering.
2. Flexible and reversible decisions
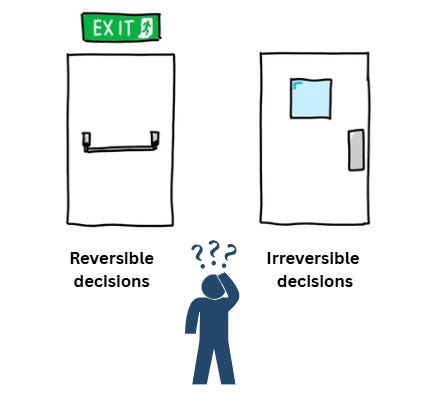
The architecture must adapt to unexpected changes in your organisation's data needs. Cloud-based architectures now make this flexibility more achievable than on-premises systems, where hardware investments often locked organisations into specific approaches for years.
However, even with cloud-based architectures, such decisions can still have huge differences. Ideally, we should always prefer more general tools that can be easily adapted to different systems instead of a tool specific to a single vendor.
For example, companies can change the cloud providers they work with, add new ones to the geographies they operate in, and integrate with other businesses through new collaborations, etc. For this reason, the flexibility of the choices made will make all these possibilities possible and easy in the future.
3. Careful evaluation of trade-offs

Every architectural decision involves trade-offs. Effective data architects must weigh key factors such as performance, cost, scalability, complexity, and maintainability to arrive at solutions that align with both current needs and future growth. This requires a deep understanding of business context and technical constraints.
Rather than seeking perfect solutions, the goal is to make informed, intentional choices that deliver the most value over time. For instance, optimising for performance might increase costs or reduce flexibility, while prioritising low-cost options may introduce technical debt. The ability to assess these trade-offs is what separates sustainable data architecture from short-term fixes.
Nine Principles of Effective Data Architecture
A strong data architecture is key to building scalable, reliable, and secure data systems. Whether you're starting from scratch or refining an existing setup, these nine principles defined in the fundamentals of data engineering book provide practical guidance for making smarter decisions.
Let’s dive into each one and see how they can help you design better data systems:
1. Choose common components wisely

A key part of data engineering is selecting tools and systems that can be used across the organisation. Good choices help teams collaborate, avoid silos, and work more efficiently.
Common components include things like storage, version control, monitoring, orchestration, and data processing tools. Instead of reinventing the wheel, teams should use existing shared tools whenever possible. These components should also have proper security and permissions to allow sharing while keeping data safe.
Cloud platforms make this easier by separating storage from computing. For example, object storage lets different teams access the same data using tools that fit their needs.
Choosing common tools requires balance. They should support collaboration without limiting teams by forcing them into rigid, one-size-fits-all solutions. The goal is flexibility, providing shared resources while allowing teams to use what works best for their specific tasks.
2. Plan for failure

Design systems that can handle unexpected breakdowns, not just ideal operating conditions.
Failure is inevitable, every system will break at some point. To build reliable data systems, you need to design with failure in mind.
Here are key factors to consider:
Availability: How often the system is up and running.
Reliability: The system’s ability to perform consistently as expected.
Recovery Time Objective (RTO): The maximum acceptable downtime before a system must be restored.
Recovery Point Objective (RPO): The amount of data loss that is acceptable after recovery.
Different systems have different needs. A minor outage in an internal tool might not be a big deal, but even a few minutes of downtime for an online store could be costly. By planning for failures in advance, engineers can design systems that minimise downtime and data loss, ensuring smooth operations even when things go wrong.
3. Architect for scalability

Create systems that efficiently scale up during high demand and scale down during quieter periods to optimise costs.
Scalability ensures that a data system can grow or shrink based on demand. A well-architected system should be able to scale up to handle large data loads, like training a machine learning model on petabytes of data or managing traffic spikes in real-time streaming. It should also scale down when demand decreases to save costs.
The most efficient systems scale dynamically, adjusting resources automatically. Some systems can even scale to zero, shutting down completely when not in use, which is common in serverless technologies like function-based computing and OLAP databases.
However, not all applications need complex scaling solutions. To design for scalability wisely, assess current usage, anticipate future growth, and balance complexity with actual needs.
4. Be mindful that architecture is leadership

Data architects play a key role in making technology decisions and guiding the architecture of data systems, ensuring that those choices are communicated effectively across the organisation. While they need to be highly technically skilled, their primary responsibility is to lead and mentor the team rather than doing all the hands-on work themselves. The best architects combine technical expertise with strong leadership, helping their teams navigate complex challenges.
Leadership, however, doesn’t mean dictating every decision. In the past, architects would sometimes impose a single technology choice on everyone, which could stifle innovation. Today’s cloud environments allow architects to make common component decisions while still leaving room for flexibility and innovation within teams.
A great data architect is someone who not only makes smart technology choices but also mentors the development team, helping them grow and take on more complex problems. By improving the team's capabilities, they create more impact than by being the sole decision-maker. As a data engineer, practicing leadership and seeking mentorship from architects will help you grow, and someday, you might step into the architect role yourself.
5. Always be architecting

Data architects don’t just maintain the current system, they’re constantly improving and adapting it to meet changing business and technology needs. They focus on understanding the existing architecture, setting goals for the future, and prioritising the necessary changes. Architecture should be flexible, collaborative, and agile, evolving with business and technology shifts.
6. Build loosely coupled systems

Design components that can be easily swapped out without needing to overhaul the entire system. A well-architected system enables teams to work independently without being reliant on one another. This approach, known as loose coupling, allows teams to test, deploy, and modify their parts of the system without affecting others, minimising the need for constant coordination and communication.
7. Make reversible decisions

Technology is always changing, so make decisions that can be easily changed later. This keeps your system flexible and adaptable. Focus on choosing the best solutions for today, but stay open to upgrading as things evolve. Reversible decisions make it easier to adjust when needed.
8. Prioritise security

Data engineers must take responsibility for securing the systems they build. This includes adopting zero-trust security and following the shared responsibility model. Zero-trust security assumes no entity is trusted, even inside the network, reducing the risk of insider attacks. The shared responsibility model divides security between the cloud provider and the user, with the provider securing the cloud and the user securing their data. Data engineers should think like security engineers, ensuring proper configurations and practices to avoid breaches.
If you would like to learn more, please check out our previous post on security:
Security Fundamentals for Data Engineers

In earlier posts, we discussed the Data Engineering Lifecycle as outlined by Joe Reis and Matt Housley in Fundamentals of Data Engineering book. If you're interested in learning more about the lifecycle, please check our previous post here:
9. Embrace FinOps

FinOps is a practice that combines finance, technology, and engineering teams to make data-driven decisions on cloud spending. Unlike on-premise systems, where costs are fixed and require careful balance, cloud systems are pay-as-you-go, making spending more dynamic. This requires a shift in mindset for data engineers, focusing not just on performance but also on cost efficiency.
With FinOps, teams monitor and manage spending continuously, adjusting resources to balance performance and cost. For example, using AWS spot instances or shifting from a pay-per-Query model to reserved capacity can optimise costs. Additionally, systems should be designed to detect and respond to spending spikes, much like how systems are built to handle high traffic.
As the cloud cost structure evolves, data engineers should embrace FinOps practices early to avoid unexpected costs and engage in the community to shape future best practices in this growing field.
Measuring Architectural Success
Key Performance Indicators

Measure the effectiveness of your architecture with these metrics:
Data freshness: The time elapsed between data creation at the source and when it becomes available for analysis; shorter freshness periods indicate more real-time decision-making capabilities.
Query performance: The response time for standard query patterns across your data architecture, measured in milliseconds or seconds; faster performance enables more interactive analysis.
System uptime and reliability: The percentage of time your data architecture is operational without failures or degradation; higher uptime ensures consistent data access for critical business functions.
Time to add new data sources: The duration required to integrate a new data source from request to availability for analysis; shorter integration times increase business agility.
Cost per query/per terabyte: The financial expenditure required to execute typical queries or store data; lower costs improve ROI on data investments.
Developer productivity metrics: Measurements of how efficiently developers can build and maintain data pipelines, including time to develop new data products and code quality indicators.
Designing Robust Data Architectures Across the Lifecycle
Building a resilient and efficient data architecture requires thoughtful planning across all stages: generation, transformation, and serving.

At the generation stage, while data engineers may not control the design of upstream source systems, it is crucial to understand their architecture, reliability, and limitations. Regular collaboration with source system teams ensures alignment and prepares your pipelines to handle issues like failures, outages, and architectural changes.

During the transformation phase, the focus shifts to selecting the right ingestion, storage, and processing tools. A mismatch between your architecture and analytical needs can cause severe performance issues. Understanding system trade-offs and aligning infrastructure with transformation patterns is key to reliability.

Finally, at the serving stage, fast feedback loops and easy access to data are essential. Encouraging data scientists and analysts to use shared, cloud-based environments ensures scalability, collaboration, and consistency in production. Each stage demands specific architectural considerations, but together, they form a cohesive system that supports robust, scalable, and high-performing data solutions.
The Role of Data Engineers
Understanding architectural principles enhances your effectiveness as a data engineer, regardless of whether you're making decisions or implementing designs. In smaller organisations, you might serve as both architect and engineer, but either way, these principles prepare you to build robust systems that meet present and future needs. As cloud-based architectures become standard, data professionals gain unprecedented flexibility to adapt systems, a significant advantage over traditional on-premises setups where hardware investments limited architectural adaptability.
Designing data architecture is collaborative, with the gap between architecture and engineering closing as the field evolves. Data engineers should understand good practices and work with stakeholders to evaluate important trade-offs like choosing between data warehouses or lakes and selecting cloud platforms or streaming frameworks. The best tool is always a moving target, so focus on avoiding unnecessary lock-in, ensuring interoperability across the data stack, and producing high ROI when selecting technologies.
Recommended Learning Resources
Books:
“Fundamentals of Data Engineering Book” by Joe Reis and Matthew Housley
“Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems” by Martin Kleppmann
“Deciphering Data Architectures: Choosing Between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh” by James Serra
Certifications:
Data Engineering Professional Certificate by AWS and DeepLearning.ai
Data Architect by Udacity
Also, this post explores 10 data pipeline design patterns, ranging from foundational concepts like Raw Data Load, ETL, and ELT to modern approaches such as Data Mesh and Data Lakehouse. It also covers patterns like Streaming Pipelines, Lambda Architecture, and Kappa Architecture, although some are less popular now. For more details, please check the post here.

Conclusion
Data architecture is not just the domain of architects. It is a shared responsibility across the data team. By understanding architectural principles, data engineers can make better choices, contribute to more resilient systems, and adapt to evolving business needs. Whether you're designing from scratch or improving existing infrastructure, thinking architecturally will strengthen your impact.
As data systems grow more complex and cloud-native, the ability to balance flexibility, performance, cost, and security becomes even more critical. Embedding architectural thinking into your daily work ensures that you’re not just building for today but also preparing for what’s next.
You might also enjoy these posts about Data Engineering:



https://pipeline2insights.substack.com/t/data-engineering-life-cycle