
dbt in Action #1: Fundamentals
Building a Modular Data Transformation Pipeline using dbt

One important step in data engineering is transformation. This means changing raw data into a useful format for reports, analysis, or AI. Without this step, data remains unusable. Transformation is where data starts to become valuable. For more details, check out this post:

Among various transformation tools, we chose dbt because it is widely used by companies of all sizes, from startups to large enterprises. It has become a standard for data transformations and a key skill in today’s data ecosystem. dbt lets us write, test, and document SQL-based transformations, making it a popular tool in Analytics and Data Engineering.

This post is the first step of our dbt series, where we’ll explore practical dbt implementations step by step. Over the next few posts, we’ll progressively dive deeper into key dbt concepts to help you build scalable and maintainable data pipelines.
Here’s our plan for this dbt series:
Post 1: Introduction to dbt, project setup, and transforming data through staging, intermediate, and marts layers.
Post 2: Deep dive into dbt seeds, tests, and macros for better flexibility and data validation.
Post 3: Exploring dbt analyses, snapshots, and incremental models for managing historical and large-scale data transformations.
Post 4: Understanding the dbt semantic layer and MetricFlow.
If you're interested in dbt and its practical applications, don't forget to subscribe so you won't miss any posts!
In this post, we’ll explore:
What is dbt?
Standard dbt project structure
A hands-on dbt project following a layered approach:
Staging Layer: Ingesting the raw data.
Intermediate Layer: Cleaning and aggregating data.
Marts Layer: Preparing final models for stakeholders.
The code for this project is available here: [GitHub]1
By the end of this post, you’ll have a clear understanding of how dbt structures projects and how to use it for building modular, reusable, and scalable data transformations.
What is dbt?

dbt (data build tool) is an open-source transformation tool that exclusively focuses on the Transformation step of data pipelines in a modular way. It is particularly popular in Analytics Engineering and Data Engineering because it bridges the gap between raw data storage and analytical insights.
dbt allows data teams to:
Write modular SQL transformations that are easy to maintain.
Test data quality with built-in assertions.
Generate documentation automatically.
Leverage version control for collaborations.
Schedule workflows.
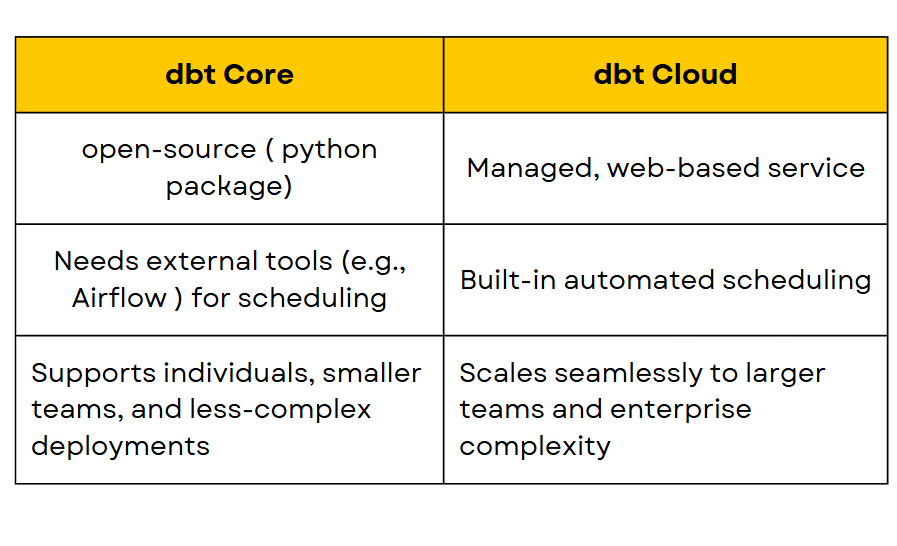
dbt comes in two versions: dbt Core and dbt Cloud.
dbt Core is the open-source command-line version that allows users to define, test, and document transformations using SQL and Jinja. It provides flexibility but requires manual setup for scheduling, orchestration, and infrastructure management.
dbt Cloud is a managed service that offers a web-based UI, automated scheduling, logging, and integrations with various data platforms. It simplifies collaboration and deployment, making it easier for teams to manage transformations without worrying about infrastructure.
While dbt Core is ideal for those who prefer full control over their environment, dbt Cloud is beneficial for teams looking for a streamlined and scalable solution with built-in automation and governance features.
Why dbt is so Popular?
The rise of cloud data warehouses like Snowflake, BigQuery, and Redshift has shifted data transformation from ETL tools to in-database processing. dbt takes full advantage of this by allowing SQL-based transformations directly within the warehouse, making it very practical, efficient and cost-effective.
dbt is particularly loved for its:
Simplicity
Modularity
Collaboration
Scalability
Standard dbt Project Structure
A dbt project follows a structured approach to organising SQL transformations, making it easy to maintain and scale. At its core, a dbt project consists of models, schemas, tests, and documentation.
Let’s break down the standard project structure (the below structure is the one that we will implement in the hands-on example):
dbt_project/
│-- models/
│ ├── staging/
│ │ ├── stg_orders.sql
│ │ ├── stg_customers.sql
| | ├── stg_payments.sql
| | ├── sources.yml
│ │ └── schema.yml
│ ├── intermediate/
│ │ ├── int_order_summary.sql
│ │ ├── int_payment_summary.sql
│ │ └── schema.yml
│ ├── marts/
│ │ ├── mart_customer_lifetime_value.sql
│ │ ├── mart_order_payments.sql
│ │ └── schema.yml
│-- seeds/
│-- snapshots/
│-- tests/
│-- analyses/
│-- macros/
│-- profiles.yml
│-- dbt_project.yml1. Models (SQL Transformations)
The models/ directory contains SQL files that define transformation logic. These models are categorised into three layers:

Staging Layer (
models/staging/)Ingests raw data into clean, structured tables.
Uses source tables directly.
Typically follows a one-to-one mapping with source tables.
Example:
stg_orders.sqlextracts and renames raw columns for consistency.
Intermediate Layer (
models/intermediate/)Aggregates and processes data for further analysis.
Often involves joins, calculations, and deduplication.
Example:
int_order_summary.sqlaggregates order-level metrics.
Marts Layer (
models/marts/)Contains final tables for stakeholder use
Divided into fact tables (e.g.,
fact_sales.sql) and dimension tables (e.g.,dim_customers.sql)Example:
fact_sales.sqlprovides a ready-to-use table for reporting
Each model is defined using SQL files, and dbt compiles them into a dependency graph.
2. Schemas (schema.yml in Models)
In a dbt project, schema.yml files define metadata, testing rules, and documentation for models. These files are crucial for maintainability, data quality assurance, and documentation.
Each dbt model folder (staging, intermediate, marts) contains a schema.yml file where we define:
Sources (for raw tables in staging models)
Model metadata (for defining relationships, column descriptions, and tests)
Tests (to ensure data integrity and quality)
Documentation (for self-explanatory, well-documented transformations)
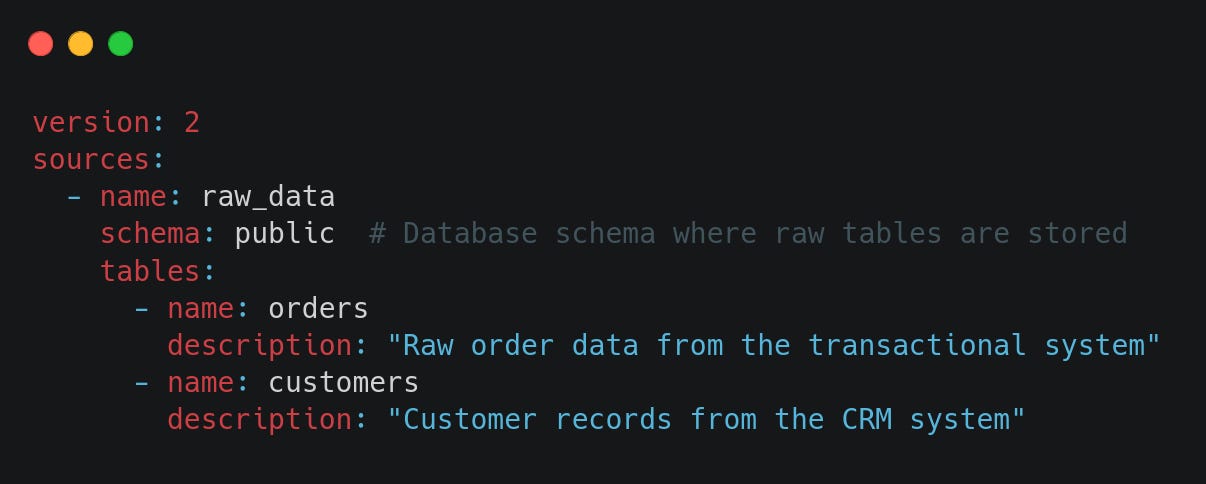
2.1. Defining Sources in Staging
When working with raw data, we define and document source tables in schema.yml inside the staging/ folder. This ensures that dbt knows where the raw data comes from:
2.2. Defining Models & Metadata
For each transformation layer (staging, intermediate, marts), we document models and their column definitions inside schema.yml. This improves maintainability and helps teams understand what each table represents.
Example for schema.yml in models/marts/:
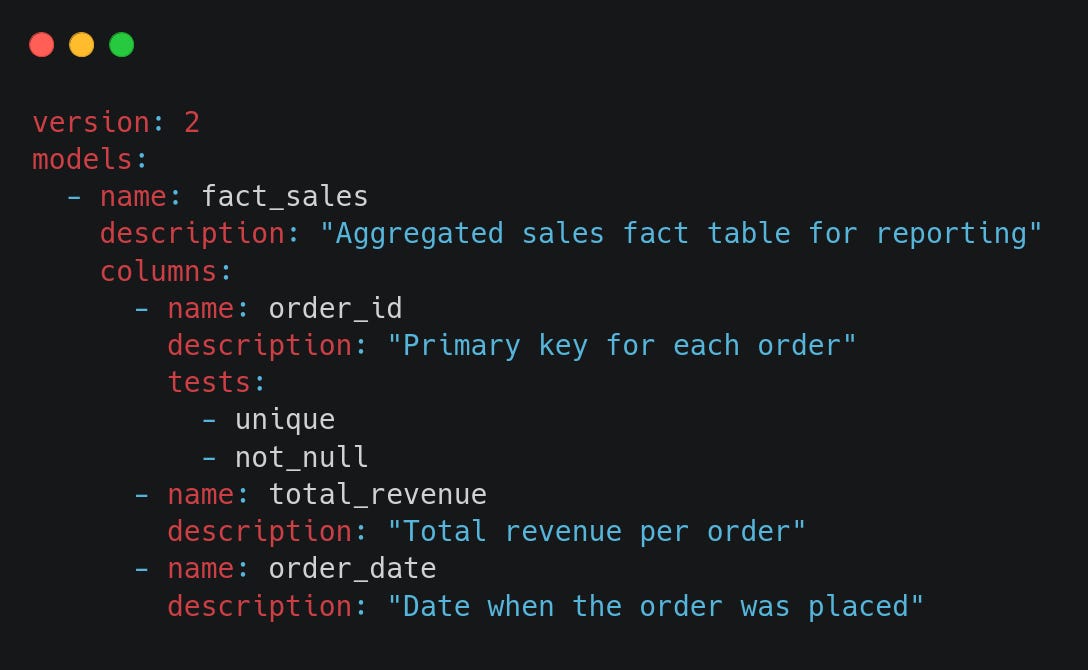
This ensures:
Clear documentation for future developers.
Well-defined table structures.
Data validation through tests.
3. Tests (tests/)
The tests folder in dbt stores custom SQL-based tests to ensure data quality. While dbt provides four built-in tests:
unique→ Ensures values in a column are unique (e.g., no duplicate primary keys).not_null→ Ensures that a column does not contain NULL values.accepted_values→ Checks that a column contains only specified values.relationships→ Validates referential integrity (i.e., foreign keys exist in the referenced table).
Custom tests help validate more complex business rules and detect anomalies. These tests, written in SQL, go beyond built-in options and can be applied to specific columns or entire tables. In the next post, we’ll explore different types of dbt tests, including data tests and unit tests.
Example: Create a new test file inside tests/duplicate_orders.sql

If this query returns results, the test fails because duplicate orders exist.
4. Macros (macros/)
Macros allow code reusability using Jinja templates. They work like functions in SQL, helping simplify complex transformations. (We will explore macros in more detail in the next post)
5. Seeds (seeds/)
Seed files allow loading CSV data into the warehouse for easy reference. This is useful for lookup tables or static datasets. (We will explore seeds in more detail in the next post)
6. Snapshots (snapshots/)
Snapshots allow tracking changes over time in source tables by capturing historical states.
7. Analyses (analyses/)
Stores ad-hoc queries for exploratory analysis that are not used in production transformations.
8. dbt_project.yml
This is the configuration file where you define database connections, model paths, materialisation settings, and other project-wide configurations.
For more details about the components of dbt, check out: [dbt Docs]
Hands-on Example: Using dbt for Data Transformation
In this section, we’ll walk through a hands-on dbt example, where we connect to database tables, clean, and aggregate data following a structured approach.

Dataset Overview
For this hands-on example, we are working with a sample e-commerce dataset that contains the following raw tables:
orders: Contains customer orders, statuses, and amounts.customers: Stores customer details like name, email, and country.payments: Tracks payment transactions, including amounts and statuses.
Goal of this dbt Project
The objective of this project is to transform raw e-commerce data into structured, analytics-ready tables by:
Ingesting data in the staging layer
Aggregating and processing data in the intermediate layer
Preparing business-ready tables in the marts layer
At the end of this process, we will create two key marts models:
mart_customer_lifetime_value: Summarises customer spending behaviour.mart_orders_payments: Tracks order-level payment statuses.
Configuring dbt (dbt_project.yml and profiles.yml)
dbt_project.yml configures how dbt runs models in the project.
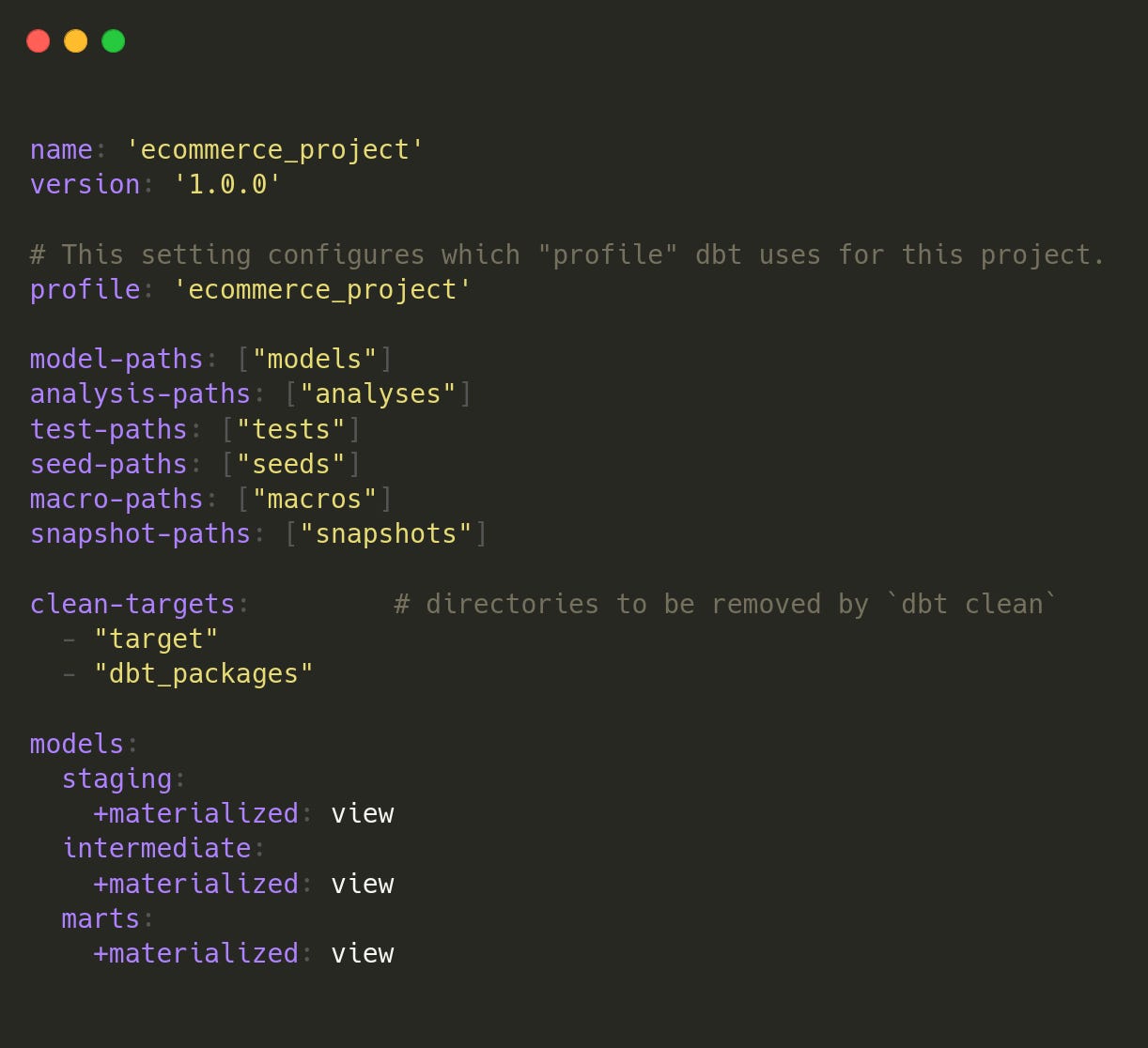
All layers use views for example purposes. However, the intermediate & marts layers may be materialized as tables in the real world.
profiles.yml connects dbt to the database. We use a local PostgreSQL host for this example as below.
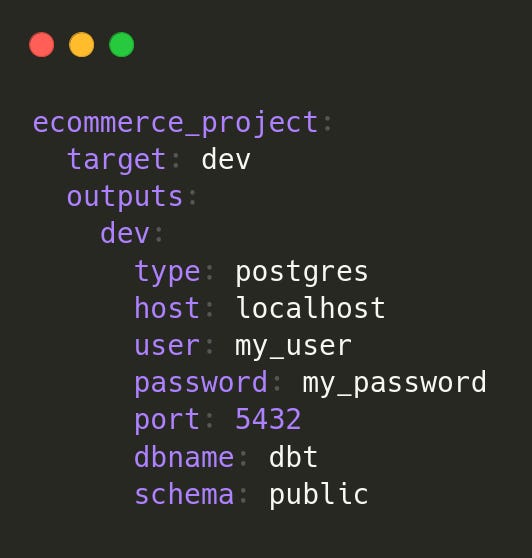
To verify the connection:
dbt debugStaging Layer
Goal: The staging layer ingests raw data, renames columns, standardises formats, and ensures data consistency before further processing.
In this layer, we process three raw tables:
1.stg_orders
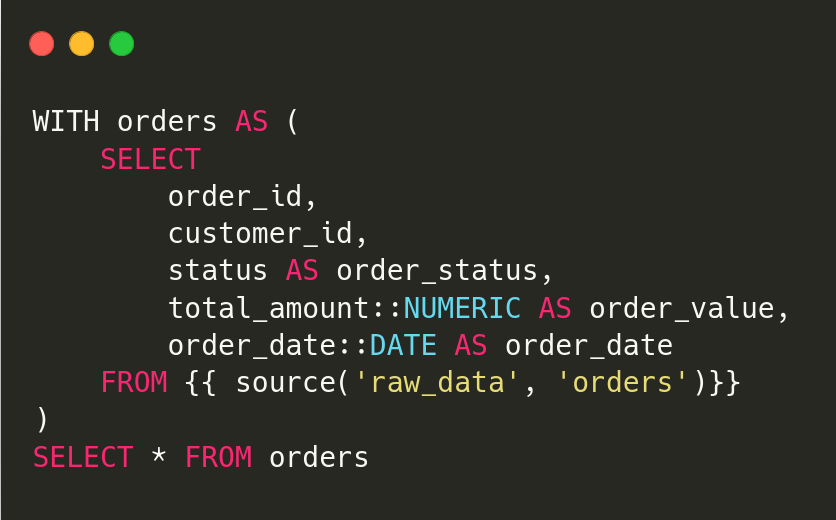
2.stg_customers

3.stg_payments

Additionally, we write a sources.yml and schema.yml inside /models/staging/.The example schema.yml representing the orders table is as below. For the full schema.yml, see [GitHub]

sources.yml:

After the definitions, we can run:
dbt run --select stagingThis will connect to our db, then materialize the staging models.
Intermediate Layer
The intermediate layer aggregates and processes data before final marts. In this layer, we create two models:
1.int_order_summary
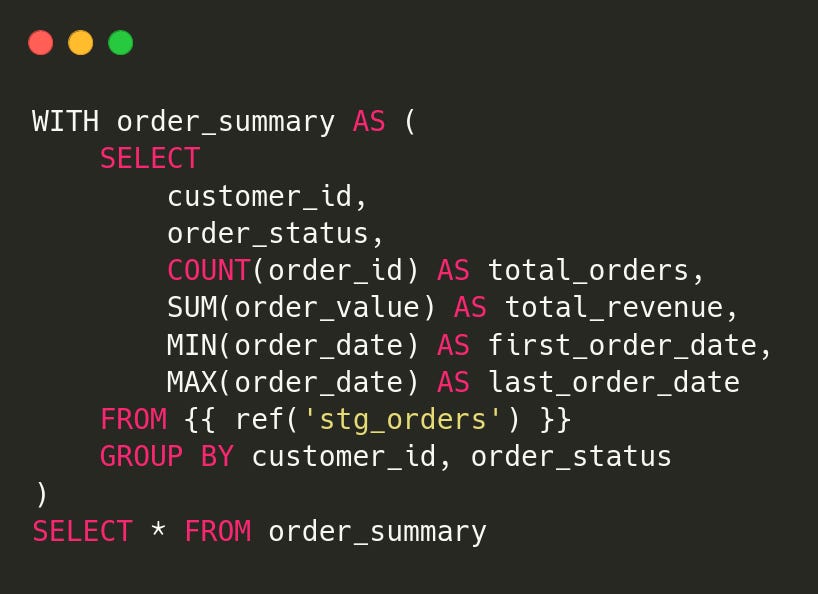
2.int_payment_summary
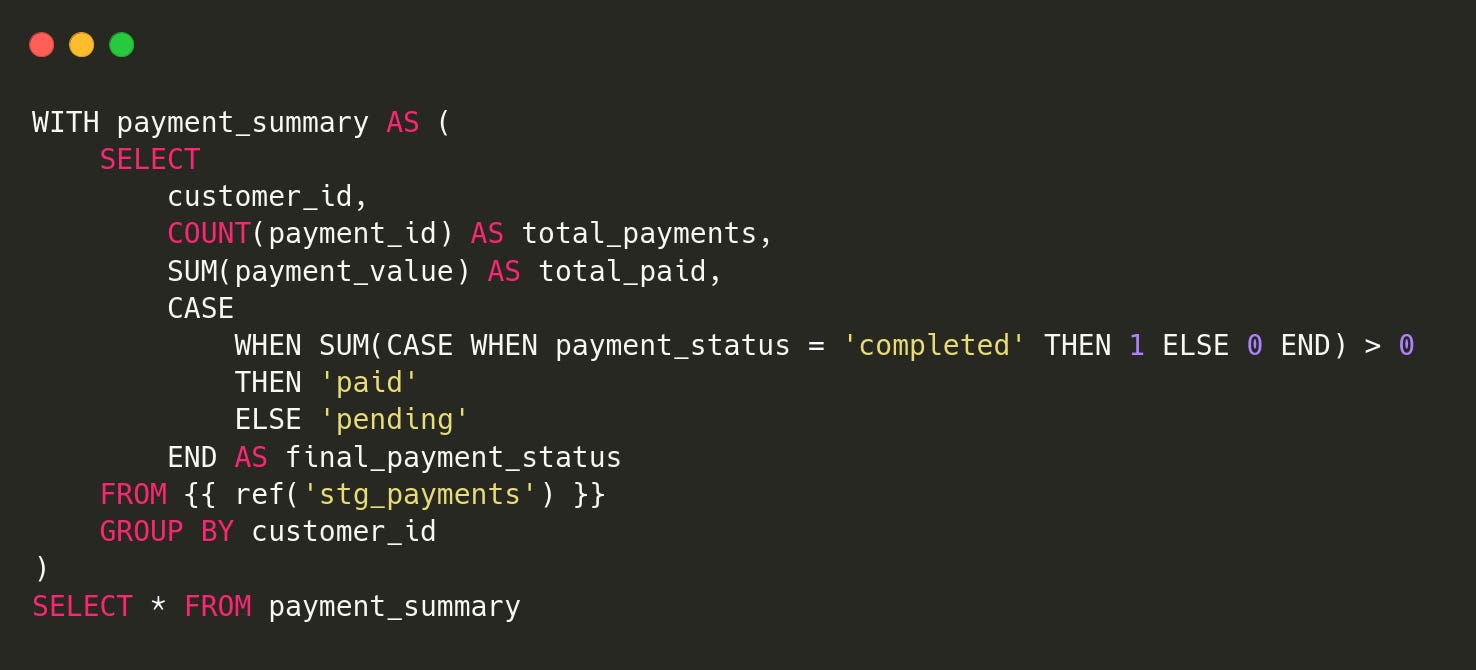
schema.yml:

Run:
dbt run --select intermediateMarts Layer
The marts layer provides business-ready tables.
1.mart_customer_lifetime_value
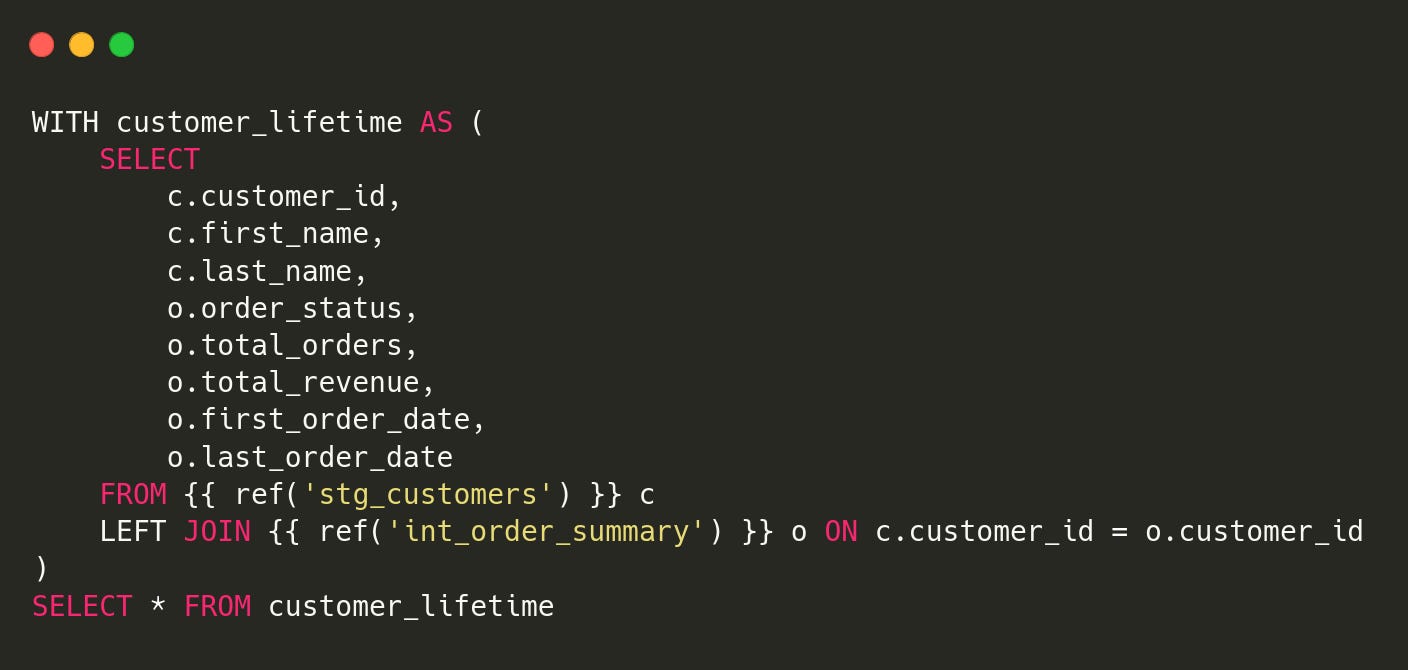
2.mart_order_payments
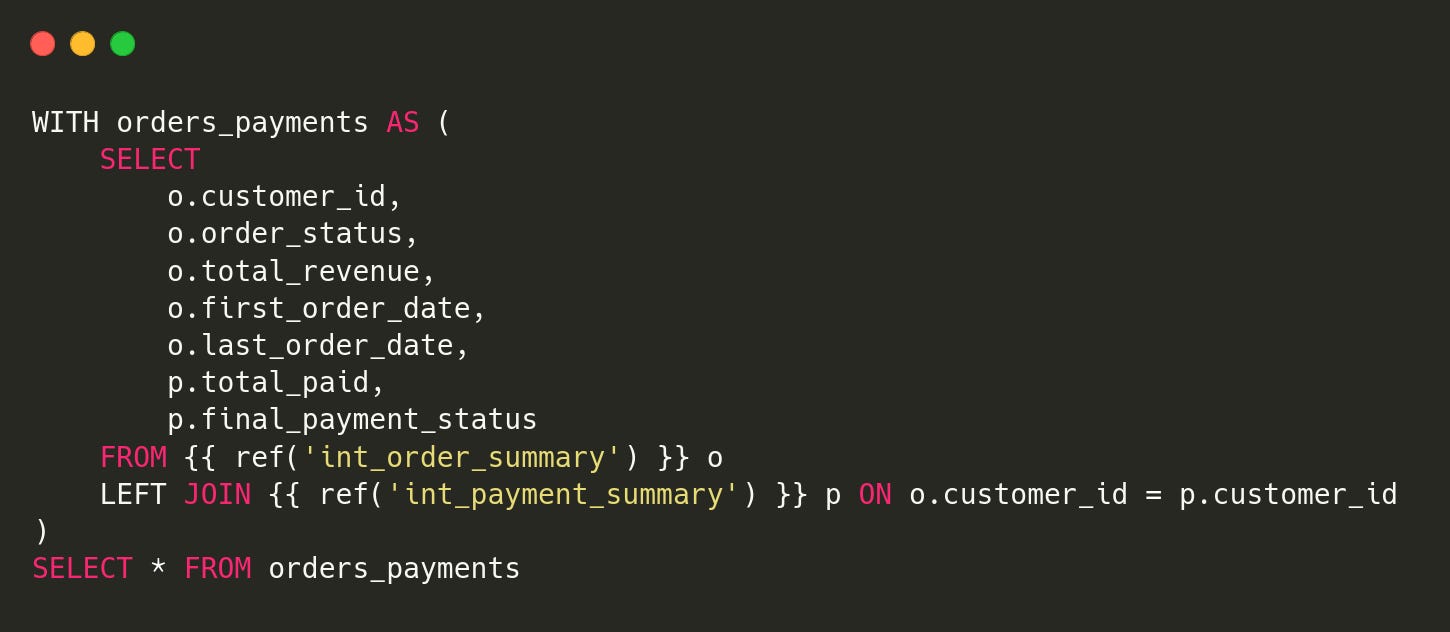
schema.yml:

Run:
dbt run --select martsor we can run below to run all layers together:
dbt runAlso, we can run the below command to run tests that we defined:
dbt testThen we can generate and serve documentation for our project by running the below commands:
dbt docs generate
dbt docs serve
# by default it serves on localhost:8080At the end we have the below transformation model:

Conclusion
In this post, we walked through a step-by-step dbt implementation, covering:
Project setup with
dbt_project.ymlandprofiles.ymlStaging layer for ingesting and viewing raw data
Intermediate layer for aggregating and transforming data
Marts layer for creating business-ready tables
By following a layered approach, we built a modular, scalable, and testable data transformation pipeline.
In the next post, we’ll dive into:
dbt Seeds → Using static CSV files as sources
dbt Macros → Writing reusable SQL logic
Custom Tests → Enhancing data validation beyond built-in dbt tests
If you found this guide useful, subscribe to stay updated with our latest dbt tutorials!
If you found this post helpful, you might also enjoy these practical tutorials exploring Data Engineering tools in action!



https://github.com/pipelinetoinsights/dbt-example
Thanks! Really great post. One question that came to mind though, how do the dbt modeling layers (staging → intermediate → marts) compare to the medallion architecture layers (bronze → silver → gold)? Are they just different naming conventions for similar concepts, or do they serve distinct purposes in practice?
That's a great article. I've tried to learn about DBT for a s while now.
I find the official docs too low level and other articles expect you to know the basics already.