
dbt in Action #2: Seeds, Tests and Macros
Practicing dbt seeds, tests and macros with hands-on examples

A transformation pipeline is only as good as the data it processes. If data quality is poor, insights are unreliable. If transformations are rigid, maintaining them becomes a nightmare.
In this post, we’ll focus on dbt Tests and Macros to build testable and scalable transformations while also covering dbt Seeds to load static data. Therefore, we will be covering;
dbt Seeds: Using CSV files to load static data (e.g., reference tables, business logic rules).
dbt Tests: Ensuring data quality with various built-in and custom test types.
dbt Macros: Writing reusable SQL logic for modular transformations.
Hands-on Example: Implementing all three concepts in a dbt project.
Note: You can find all the dbt implementation of the Hands-on Example here: [Github Repository]1
If you missed the previous post where we covered dbt Fundamentals with a hands-on example, you can check out:

This is the second post of our dbt in Action series and the overall plan is as below.
Post 1: Introduction to dbt, project setup, and transforming data through staging, intermediate, and marts layers.
Post 2: Deep dive into dbt seeds, tests, and macros for better flexibility and data validation.
Post 3: Exploring dbt analyses, snapshots, and incremental models for managing historical and large-scale data transformations.
Post 4: Understanding the dbt semantic layer and MetricFlow.
If you're interested in dbt and its practical applications, don't forget to subscribe so you won't miss any posts!
dbt Seeds

Data pipelines often need reference tables, such as business rules, country mappings, or segment classifications. Instead of hardcoding these values inside SQL transformations, dbt Seeds allow us to store them in CSV files, load them into the database, and use them just like regular tables.
Benefits:
Easily maintain reference data in CSV files.
Stored inside the dbt project, tracked via Git.
No need for additional ETL processes to load static data.
Ensures consistency by keeping mappings in a central place.
Later in our hands-on example we will use below two csv files to practice dbt seeds as below:
customer_segments.csv
customer_id,segment
1001,Gold
1002,Silver
1003,Bronze
1004,Gold
1005,Silverregion_mapping.csv
country,region
USA,North America
Canada,North America
Germany,Europe
France,Europe
India,Asia
Australia,OceaniaTherefore, we can define our seeds in dbt_project.yml as below.
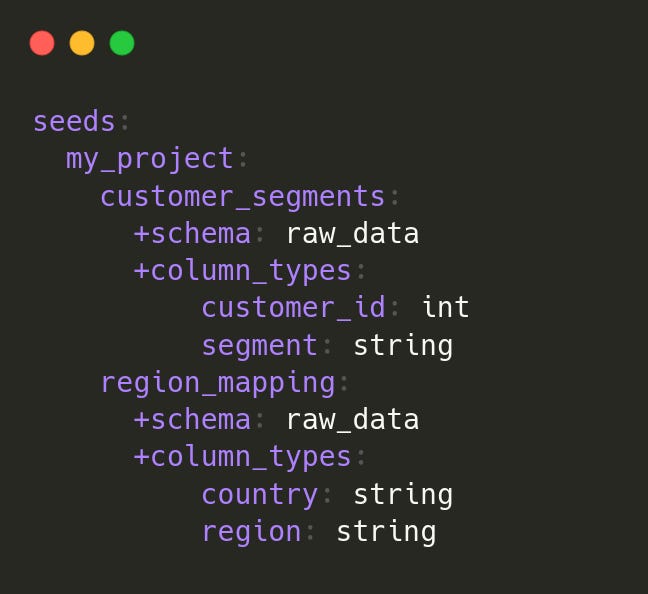
Then, we run the below command to load these tables.
dbt seedThis creates two tables (raw_data.customer_segments and raw_data.region_mapping) inside our data warehouse.
Good use cases for seeds:
A list of mappings of country codes to country names
A list of test emails to exclude from analysis
A list of employee account IDs
Poor use cases for seeds:
Loading raw data that has been exported to CSVs
Any kind of production data containing sensitive information. For example personal identifiable information (PII) and passwords.
For more details, please see: [dbt docs seeds]
dbt Tests

dbt Tests are statements that validate data integrity across models, sources, seeds, and snapshots. They help identify data inconsistencies before they impact analytics or business decisions.
When running dbt test, dbt executes SQL queries designed to find failing records, if no rows are returned, the test passes.
Types of Tests in dbt
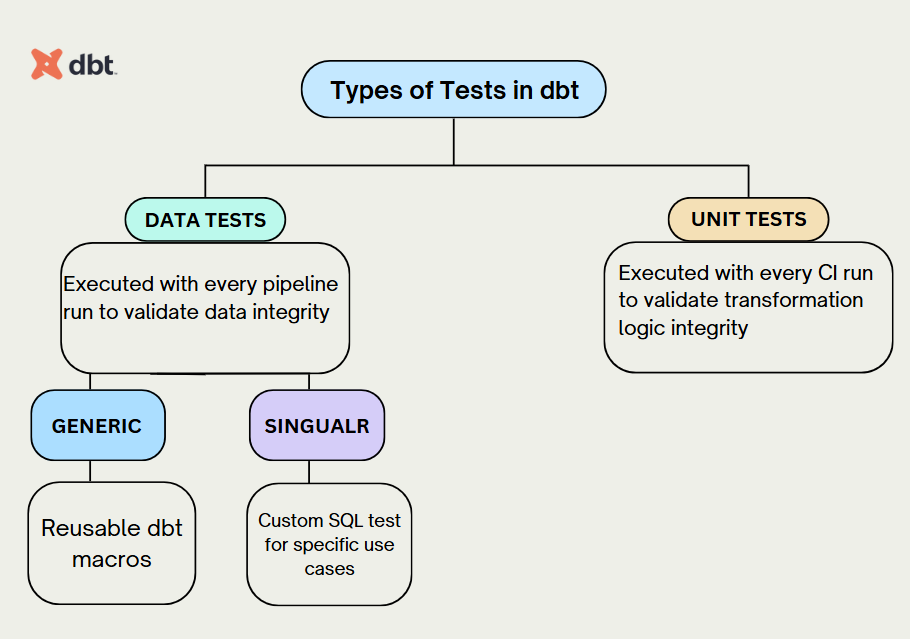
1. Data Tests
These tests are executed with every pipeline run to ensure the quality and integrity of your data. They can be further divided into:
There are two ways of defining data tests in dbt:
a) Singular Tests (One-off SQL Assertions)
A singular test is the simplest form of data testing in dbt. If you can write a SQL query that identifies failing records, you can save it as a .sql file in the tests/ directory and dbt will execute it with the dbt test command.
Key features:
Custom SQL queries that return failing rows.
Stored in the
tests/directory.Ideal for enforcing business-specific rules and validations.
Example: Ensuring Total Payment Amount Is Positive
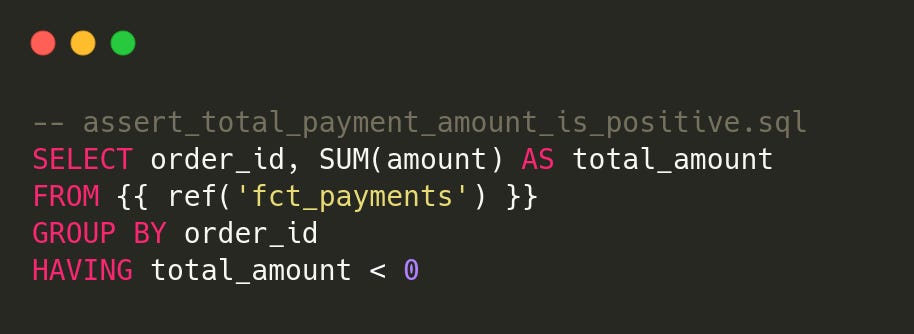
If any rows are returned, the test fails.
The test file name becomes its identifier (
assert_total_payment_amount_is_positive).
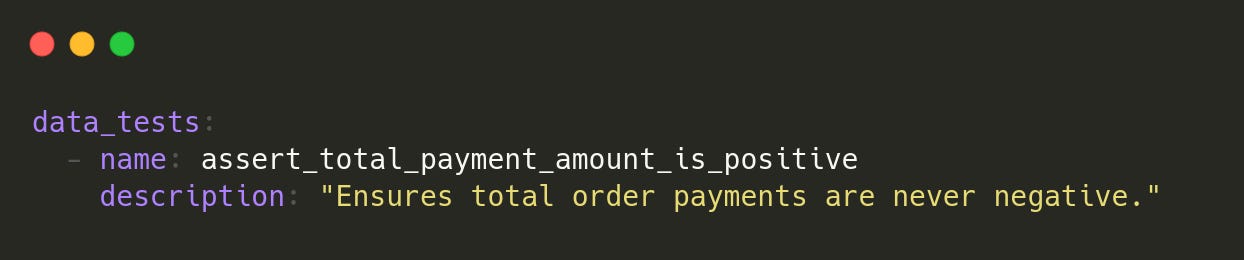
We define our custom tests in our schema.yml as below.
b) Generic Tests
A generic test is a parameterised query that accepts arguments, allowing for flexible data validation. Defined within a special test block (similar to a macro which we explain in the next part), it can be referenced by name in .yml files and applied to models, columns, sources, snapshots, and seeds.
Key features:
Parameterised for reusable validation.
Defined in a test block, like a macro.
Applied across multiple dbt assets via
.ymlfiles.
dbt comes with four built-in generic tests:
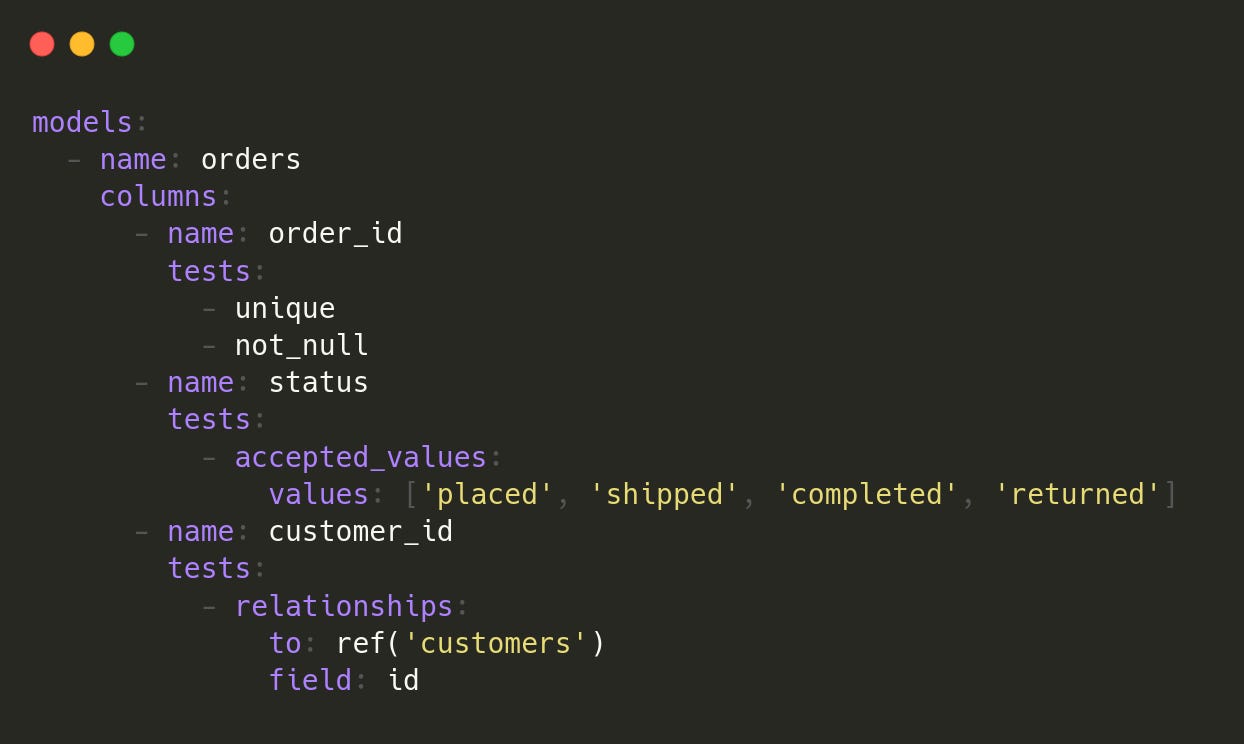
unique: Values in a column are unique.
not_null: Column contains no
NULLvalues.accepted_values: Column only contains specific values (for example,
statuscolumn inordersshould be placed, shipped or completed).relationships: Foreign key values exist in a referenced table.
We use built-in tests in our schema.yml without needing to define them explicitly.
Running dbt Tests
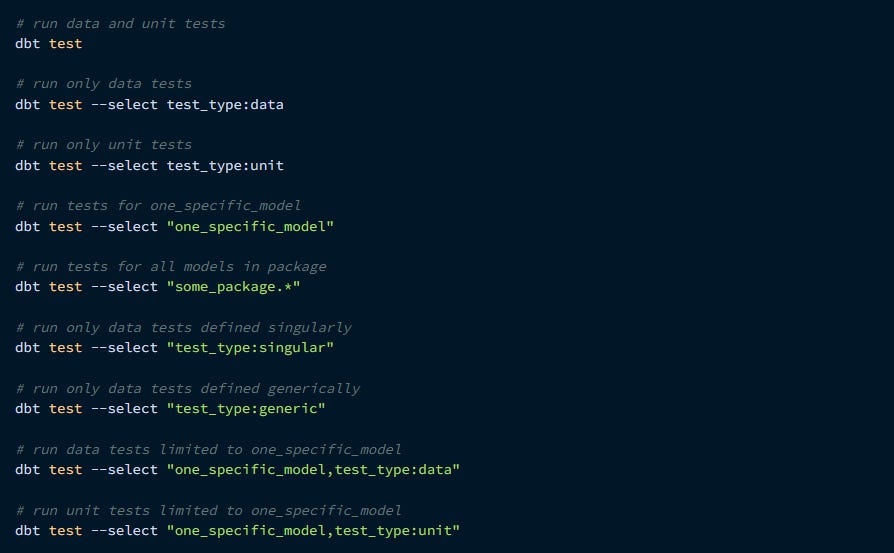
To run dbt tests, the below command can be used as given in dbt docs.
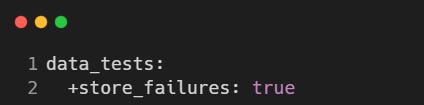
By default, dbt tests execute in memory. To store failing records in the database for faster debugging, enable store_failures in the dbt_project.yml:
2. Unit Tests
Unit tests focus on validating your transformation logic. These tests compare predefined data with the expected results to ensure that your transformation logic is accurate. Unlike data tests, which are executed on every pipeline run, unit tests are usually run during the Continuous Integration (CI) process when new code is introduced. Unit tests were added to dbt Core starting from version 1.8.
By leveraging both data and unit tests, dbt allows you to create a robust testing framework that ensures the quality of both your data and your transformation logic.
Note: If you're looking for more advanced testing in dbt, check out the dbt Great Expectations package. It offers a wide range of powerful tests to validate your data quality, going beyond standard dbt tests like unique, not null, and referential integrity checks. With this package, you can define expectations for your data, such as checking for anomalies, enforcing statistical properties, and validating complex business rules.
We'll cover this in more detail in a future post, but in the meantime, you can explore the official documentation here.

dbt Macros
In dbt, macros allow us to write reusable SQL logic, making transformations more modular and maintainable. They function similarly to functions in programming languages, letting us abstract repetitive SQL patterns and improve code readability.
dbt Macros are based on Jinja which:

is a Python-based templating language
brings functional aspects to SQL so we can work like software engineers
enables better collaboration
sets the foundation for macros
The best place to learn about leveraging Jinja is the [Jinja Template Designer documentation]
In your dbt project, you might notice that you're writing the same kind of logic in multiple models or SQL files. This could be things like pivoting data, creating date tables, or handling duplicates. Instead of repeating yourself, you can use macros.
Macros help you write cleaner, more efficient code by turning repeated logic into reusable functions. This means a model that was 200 lines long can be cut down to just 50 lines, making your project easier to manage.
However, it's important to keep a balance. While macros make your code shorter, using too many can make it harder to understand. Always think about readability and teamwork when deciding where to use them.
Additionally, if you are interested in training that covers jinja, macros, and packages you can check this course from dbt: [dbt course jinja, macros, and packages]
Creating a dbt Macro
Macros in dbt are written in Jinja, a templating language that allows us to generate dynamic SQL. They are stored in the macros/ directory inside a dbt project.
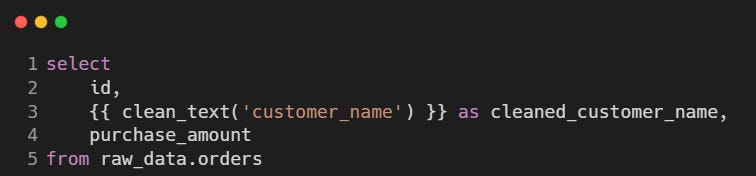
A simple example of a macro is a function to remove special characters from a string:

This macro takes a column name as an argument and returns an SQL statement that removes special characters from its values.
Using a Macro in a Model
Once defined, a macro can be used in dbt models or tests by calling it with {{ macro_name(arguments) }}.
Example usage in a transformation model:
Parameterised Macros
Macros can accept multiple parameters, making them even more flexible. For example, we can create a macro that dynamically generates a case statement for mapping categories:
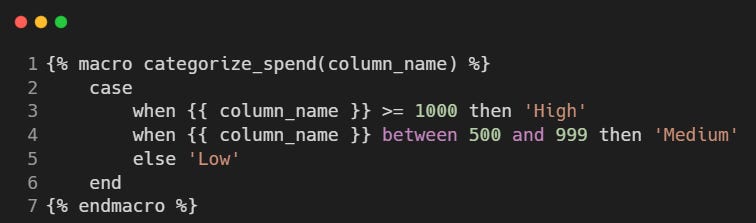
This can be used as follows in a model:
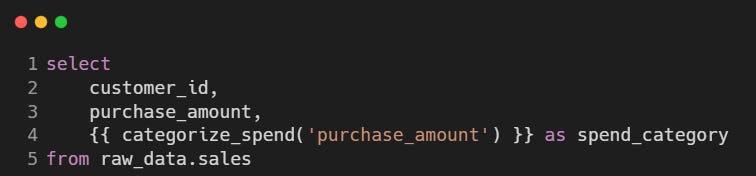
Built-in dbt Macros
Apart from user-defined macros, dbt comes with built-in macros that simplify various tasks. Some useful ones include:
dbt_utils.safe_cast(column, type): Ensures type conversion without errors.dbt.date_trunc(interval, date_column): Truncates dates to a specified interval.dbt.current_timestamp(): Returns the current timestamp based on the database dialect.
For more details, please see: [dbt docs Jinja and macros section]
Hands-On Example
For this hands-on example, we will create a customer analytics pipeline in dbt using fact and dimension tables. The pipeline will leverage dbt Seeds, dbt Tests to ensure data integrity, and dbt Macros to make transformations more modular.
Scenario
We work for an e-commerce company that wants to analyse customer purchases and spending behaviour. The company aims to:
Understand customer spending patterns (low, medium, and high spenders).
Identify regional sales distribution to optimise marketing.
Ensure data quality using automated tests.
The raw data comes from three sources:
Customers Table (
raw_data.customers): Contains customer details.Sales Table (
raw_data.sales): Stores purchase transactions.Region Mapping (
raw_data.region_mapping): Maps countries to regions.
Data Transformation Layers
To transform raw data into structured and meaningful analytics, we follow a layered approach using dbt:
Staging Layer (stg_*)
The staging models clean and standardise raw data.
They apply necessary formatting, casting, and deduplication.
They also join reference data (e.g., region mapping) to enrich records.
Intermediate Layer (int_*)
The intermediate models bridge the gap between raw and final analytics tables.
They apply business logic, such as aggregations and calculations.
They structure data in a way that is optimised for analytics.
Marts Layer (dim_* and fact_*)
The marts models provide fact and dimension tables for analytics.
Fact tables store transactions, while dimension tables store contextual data.
Data Model Breakdown
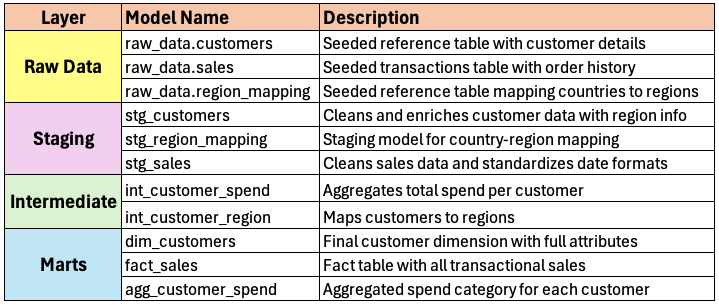
You can find all dbt implementation here: [GitHub Repository]
Transformation Steps
Step 1: Staging Layer (stg_* models)
We clean data, standardise formats, and enrich records using reference data.
Model:
stg_customers.sql
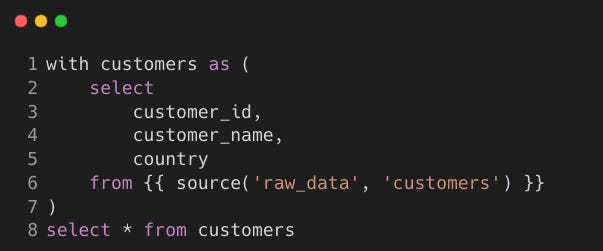
Model:
stg_sales.sql
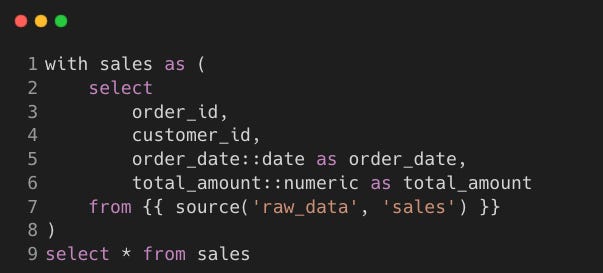
Model: stg_region_mapping.sql
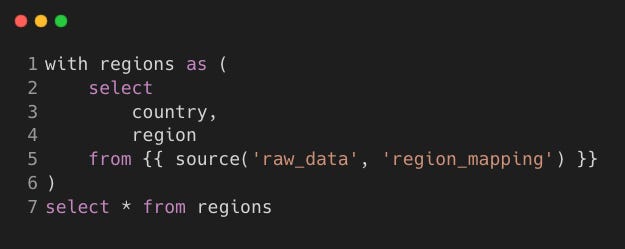
Step 2: Intermediate Layer (int_* models)
We apply business rules, aggregations, and pre-processing before analytics.
Model:
int_customer_spend.sql
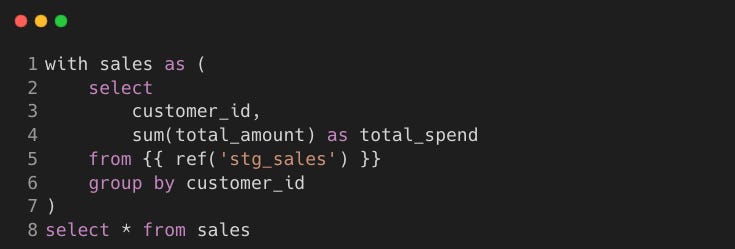
Model:
int_customer_region.sql
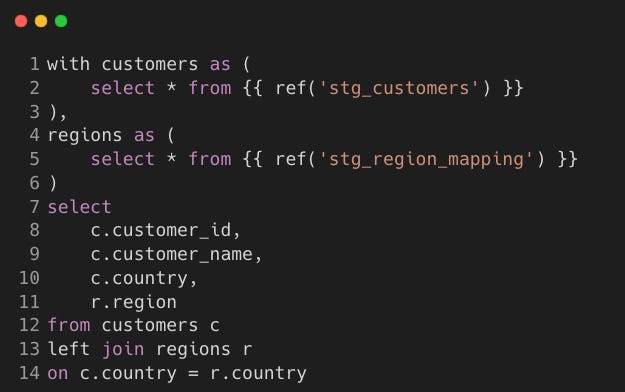
Step 3: Marts Layer (dim_* and fact_* models)
We create dimension and fact tables optimised for reporting.
Model:
dim_customers.sql
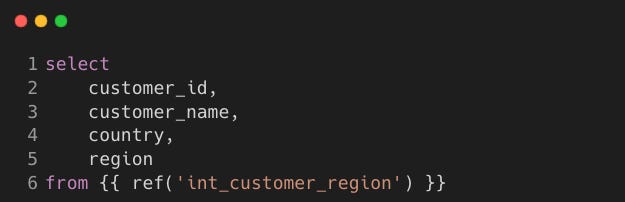
Model:
fact_sales.sql
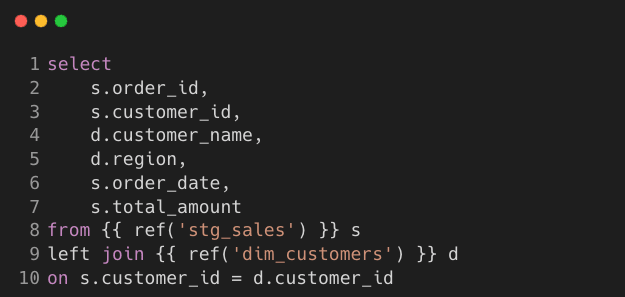
Model:
agg_customer_spend.sql
Uses a macro to categorise customers based on spend.
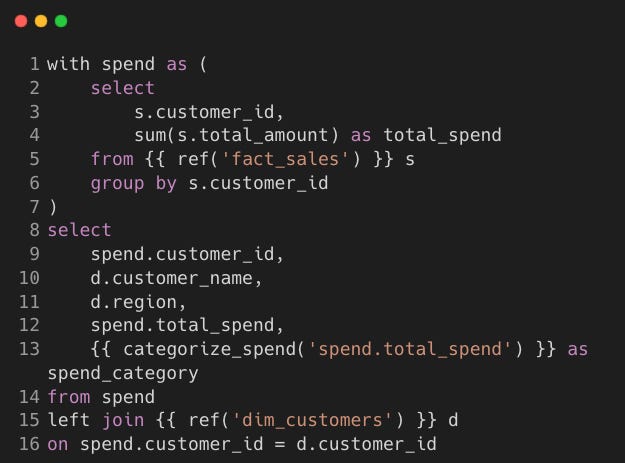
Step 4: dbt Macros (macros/)
We define a macro to categorise customers based on spending.
Macro:
categorize_spend.sql
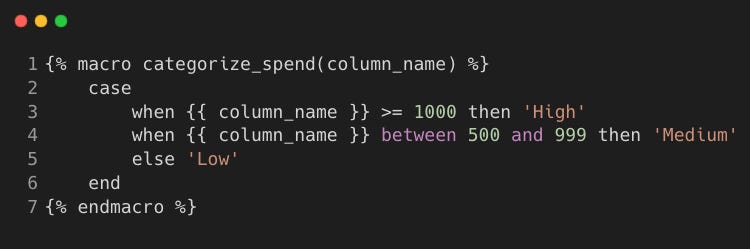
Step 5: dbt Tests (tests/generic/)
To ensure data quality, we define tests in schema.yml.

Step 6: Running the Full dbt Pipeline
Load Seeds
dbt seedRun Transformations
dbt runValidate Data with Tests
dbt testConclusion
By leveraging dbt Seeds, Tests, and Macros, we have built a transformation pipeline that is both scalable and testable.
dbt Seeds simplifies the process of loading static reference data.
dbt Tests ensure data integrity by catching inconsistencies early.
dbt Macros promote reusability, making SQL transformations more modular.
Through our hands-on example, we demonstrated how to structure transformations across staging, intermediate, and marts layers, ultimately delivering analytics-ready data. With these concepts in place, you can build reliable data pipelines that are easier to maintain and scale.
In the next post, we’ll explore dbt Analyses, Snapshots, and Incremental Models to efficiently handle historical and large-scale transformations.
If you enjoyed this post, you can also like this hands-on tutorial posts.


https://github.com/pipelinetoinsights/dbt-example-2-seeds-tests-macros