

How to Learn Data Engineering in 2026
The essential fundamentals of data engineering and how to use AI tools to stay ahead of the curve

We’ll start this post with a question Mathew asked Joe, his co-author on Fundamentals of Data Engineering1, during a recent discussion in this video.
“What is the number one skill someone should develop today if they want to enter data engineering?”
Joe Reis replied:
“Get really good with AI tools. That’s the new skill I’d go all-in on.”
The message is simple: if we’re not using AI in our daily work, we’re already falling behind.
Once we’ve mastered the fundamentals, SQL, data modelling, and cloud basics, our biggest advantage will be how effectively we can leverage AI:
Generating pipeline scaffolding
Understanding model behaviour
Knowing when AI helps, and when it fails
Building systems that use AI, rather than fearing it
Whether you’re new to data engineering, transitioning from another role, or already a data engineer, this guide will help you create a practical learning plan for 2026 that blends the fundamentals with AI-powered productivity:
We cover:
Understanding the Role
Fundamentals
Working with Unstructured Data
Certifications and Career Growth
Staying Updated and Continuing to Learn
1. Understand the Role First
Before learning tools, workflows, or cloud platforms, we need to understand what a Data Engineer actually does. Most people skip this step, and then wonder why everything feels confusing.
In one sentence:
Data Engineers make data accessible so stakeholders can drive real business value
Let’s break this down.
A. Business Value: What problem are we solving?

Every data engineering effort should start with the business question.
We’re not building pipelines for fun; we’re solving real problems. Ask ourselves, are we:
Helping marketing understand user behaviour?
Enabling finance to forecast revenue more accurately?
Understanding which contracts are unprofitable?
Optimising workflows to reduce costs?
The best data engineers connect their work to business priorities, not to hype or the latest tool. Always ask:
“Does this meaningfully impact the business?”
If the answer is no, rethink the work.
B. Stakeholders: Who Needs the Data (and Why)?
Stakeholders are teams or individuals who rely on data to make decisions. Across our careers, we’ll work with:
Data analysts/scientists, AI/ML engineers
Software engineers
Business leaders, executives, Product managers, operations teams and so on.
Knowing how to communicate with each type of stakeholder is just as important as building reliable, high-quality data products.
Effective requirement gathering saves us months of rework.
In this post, “How to Gather Requirements Effectively as a Data Engineer2”, we explain in detail how to gather requirements and communicate with different types of stakeholders.
C. Make Data Accessible (define and deliver the solution)
What are we building?
Once we understand the problem, define the simplest solution:
A curated dataset (the primary deliverable)
A dashboard
A recurring email with key metrics
A fully automated data pipeline
The output should be obvious, usable, and aligned with the original problem.
How do we build it?
Only after the why and what comes the technical how:
Moving data from A to B
Transforming raw data into usable models
Automating data quality checks
Orchestrating pipelines
Ensuring reliability and scalability
This is where tools come in, but tools should support the solution, not drive it.
“Yes, we might know Databricks, Snowflake, dbt… But do we actually need these tools?”
Sometimes Python is enough. Sometimes the existing system supports the change we want, and sometimes it doesn’t, and we need architecture changes.
We should remember not to use tools just for the sake of it.
D. Thinking Like a Data Engineer

Becoming a great data engineer isn’t about mastering every tool; it’s about learning how to think. It’s the shift from seeing the world as “pipelines and code” to seeing it as:
Systems: How does this pipeline integrate with upstream applications and downstream reports?
Relationships: How do entities (users, products, transactions) connect in the data model?
Data Flows: Tracing the lineage and potential bottlenecks of data movement.
Constraints: Understanding the limits of budget, time, and computational resources.
Trade-offs: Balancing speed/latency, cost, data quality
Check out this great post3 by Ananth Packkildurai to learn more about how to think like a data engineer.
Master the Fundamentals
Even though tools keep changing and AI is speeding things up, the basics of data engineering stay the same. We suggest focusing on building a strong foundation in these areas:
1. SQL (The language of data)
Yes, AI can generate queries, but we still need to understand them.
AI won’t save us when:
A join blows up the dataset.
A query silently gives the wrong results.
Someone wrote a 300-line CTE monster.
Business logic is hidden inside messy filters.
Performance drops because the query wasn’t designed correctly.
Almost every data engineering job expects strong SQL skills.
We’ll be surprised to find that many companies have SQL everywhere, but it is often unoptimised, inconsistent, and sometimes completely wrong.
That’s why real SQL knowledge matters.
Zach Wilson’s “5 levels of SQL4” is a great way to see where we stand and what to learn next. It helps us assess our real skill level, from basic querying to true engineering-level SQL.

We suggest going beyond basic querying and learn what happens behind the scenes: how queries run, how execution plans work, and why databases behave the way they do.

2. Python
Python remains the core programming skill for data engineers due to its flexibility and vast ecosystem. With Python, you can:
Build data ingestion/transformation pipelines.
Create robust data quality and validation checks.
Orchestrate workflows using tools like Airflow5 or Dagster6.
Write the necessary unit and integration tests.
Work with powerful tools and libraries (dlt, duckdb, PySpark, Polars, etc.).
A common question we hear is: “Do I need to be a software engineer to succeed in data engineering?”
In our view, not fully. We don’t need to master every software engineering skill, but we do need to write clean, reliable, production-ready code. A solid understanding of fundamentals, clean code principles, Git, testing, and CI/CD will serve us well almost anywhere.
If we join a company that lacks those practices, our skills can make a meaningful impact.
Note: While low-code and no-code data engineering platforms (often SaaS) can be useful, they come with trade-offs. They don’t replace the value of knowing Python, which remains the most flexible and widely applicable skill for building robust, scalable products.
3. Data Storage
Storage sits at the centre of the entire data engineering lifecycle.
Every step, ingestion, transformation, and serving depends on how and where data is stored. Data often moves through multiple storage layers so it stays accessible, organised, and ready for processing.
Understanding storage fundamentals helps us design better systems.
In some companies, everything lives inside one database, which slows down applications and reporting. Knowing the difference between transactional analytical databases, data lakes, and hybrid setups helps us decide:
When to separate analytics from transactional data?
When should we use a data lake?
When is a data warehouse the better fit?
This knowledge prevents performance issues and helps us build scalable, reliable data platforms.
If you want to learn about storage, check out this post:

4. Data Modelling
Many companies still struggle with poorly designed databases. Knowing how to model data effectively (e.g., using Kimball, One Big Table and more) is a superpower for a data engineer.
AI can make data modelling faster and easier, especially in the early stages:
Gathering requirements
Drafting initial models.
Extracting entities from text.
Summarising meetings with related stakeholders.
Spotting patterns.
Generating diagrams and even conceptual, logical, or physical models
However, AI isn’t perfect; it can make mistakes. If we use it as a helper, not a replacement, it can save huge amounts of time.
Excited to learn more about how AI can support data modelling, check out the AI for Data Modelling video by Joe Reis .
5. Data quality
High-quality data is the foundation of analytics, AI, and business insights. Every data engineer must know how to:
Identify data quality issues
Communicate problems to stakeholders
Build a data quality framework
As SeattleDataGuy puts it in this post “5 Things in Data Engineering That Still Hold True After 10 Years7”
despite all the hype around new tools and AI, most of the real challenges in data engineering still come down to two things: how we model data and how we ensure its quality.
AI doesn’t remove these challenges; it magnifies them. That’s why mastering the fundamentals, metadata, and a quality-first mindset is more important in 2026 than ever.
Even technically correct data can fail if it’s missing important context, such as region, timestamp, or product category. The more sources a company ingests, the more fragile the data becomes. Modern data engineers must obsess over:
Accuracy
Completeness
Context
Lineage
Tools can automate steps, but judgment is required to structure data that aligns with real business needs.
As Zach Wilson says:
“Data engineers are the people who turn raw information into actionable truth. Focus on quality and metadata today, and your skills will only grow in value as AI adoption increases.”
We found the following resources by Mark Freeman really helpful, particularly for their hands-on examples. Mark provides clear guidance on what data quality is, how to build a practical framework, how to communicate data quality with stakeholders, and much more.
6. Cloud Basics
Before jumping into the cloud, understand why it exists.
Companies used to host everything on-premises, servers, databases, and applications, which worked for small setups but didn’t scale easily. Even today, some companies remain on-premise due to cost, policy, or because they simply don’t need cloud-scale yet.
Choose one cloud provider (AWS, GCP, or Azure) and focus on learning it well.
Key Cloud Concepts for Data Engineers
Compute: Virtual machines, serverless compute, and how workloads run in the cloud.
Managed Databases/Warehouses: Cloud-native storage and analytics services that reduce operational overhead.
IAM (Identity and Access Management): Controlling who can access what in your cloud environment.
Networking Basics: VPCs, subnets, firewalls, and data flow between services.
Understanding these core pieces will help you design scalable, reliable, and secure data pipelines in the cloud.
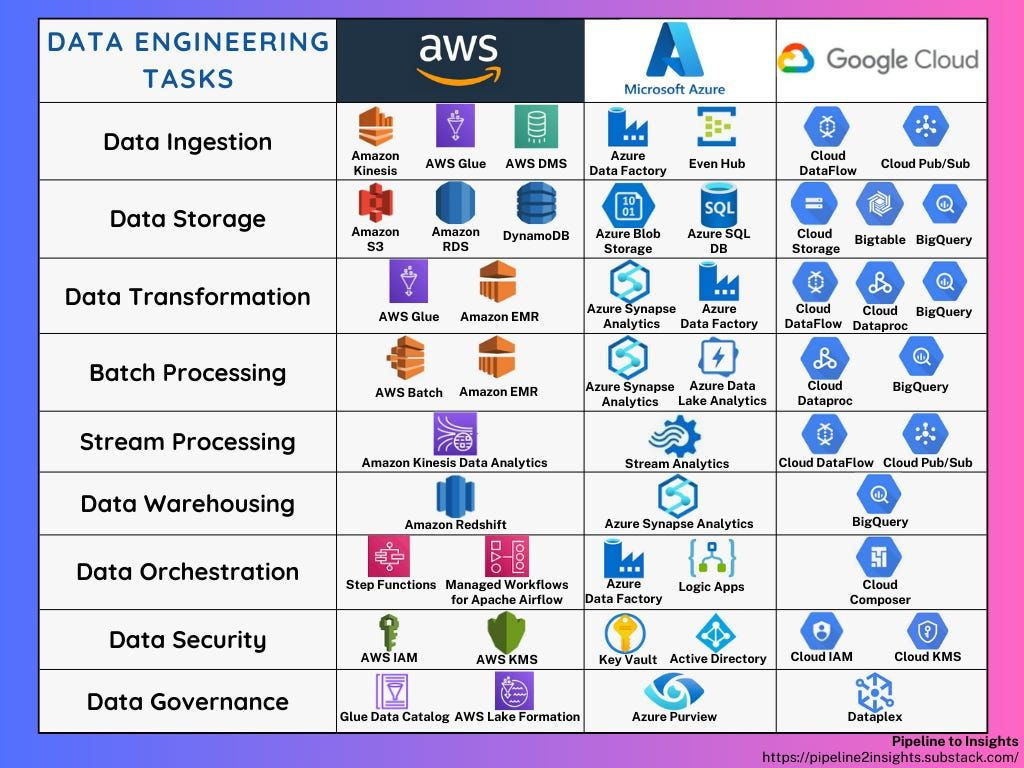
Here is a list of the Data Engineering tasks/services from the three biggest cloud providers offered for them.
3. Work with unstructured data
We separate this skill from the timeless fundamentals because it represents a rapidly growing capability driven by the rise of AI and Large Language Models (LLMs).
As companies increasingly leverage AI to derive value, whether for customer experience, employee productivity, or process optimisation, the Data Engineer’s role is evolving to support this.
Why?
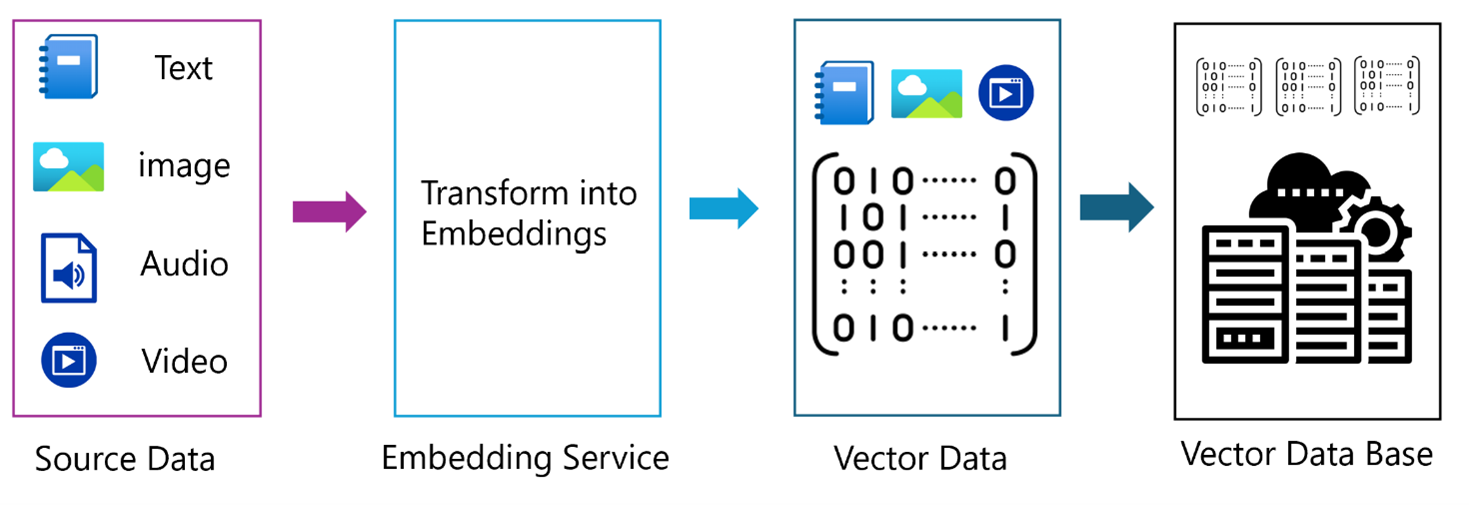
The core task remains the same: making data accessible. However, the data type shifts from neat tables to messy documents, audio, and images. This means the Data Engineer should know how to:
Ingest and Process: Handle large volumes of diverse unstructured data sources (text documents, call transcripts, images).
Chunk and Clean: Break down documents into meaningful segments and prepare them for use by LLMs.
Vectorise and Store: Work with Vector Databases to store data embedding, the mathematical representations of the unstructured data, which are essential for modern retrieval-augmented generation (RAG) applications.
Resources to Get You Started:
A Data Engineer’s Guide to Vector Databases
You can also check out this notebook13, where you’ll learn how to create a dlt pipeline, cleaning and preprocessing text, generating and storing embeddings in a vector database, tuning vector and hybrid search, and finally using that data to power a simple chat agent.
3. Certifications and Career Growth

Many beginners assume that collecting certificates is the fastest path to a data engineering career. As Yordan Ivanov wisely mentioned in How to succeed in data engineering interviews14:
“Certs are a bonus, not a ticket. I care about what you can do. A fresh cert can reduce my testing because someone else already vetted you. But if your stories feel thin, the badge won’t save you.”
We believe certifications can help in two ways:
Platform Familiarity: Databricks, Snowflake, or AWS certifications can help you learn specific tools and show baseline competence.
Specialisation: They can make you more attractive if you’re targeting a company that heavily uses that platform.
But Yordan’s key point is crucial: don’t rely on badges alone.
4. Stay Updated and Keep Learning

Data Engineering and AI change fast, so we need to keep learning and stay aware of where things are going.
How?
Follow Pioneers: Identify and follow industry leaders on different platforms and learns from them.
Engage in Communities: Join meetups, conferences, and online forums to learn what others are actually building.
Experiment: Don’t just read about new tools; try them out and build something meaningful.
Conclusion
Data engineering fundamentals remain the foundation of success, but AI is now a key skill to stay ahead. Focus on mastering SQL, Python, data modelling, quality, and cloud basics, while learning how to leverage AI effectively. Keep experimenting, stay curious, and continue learning. This combination will prepare you for 2026 and beyond.
We value your feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!

Refer
3 friends: a 1-month free.
10 friends: a 3-month free.
25 friends: a 6-month free subscription.
Our way of saying thanks for helping grow the P2I community!
https://www.amazon.com.au/Fundamentals-Data-Engineering-Robust-Systems/dp/1098108302
https://pipeline2insights.substack.com/p/how-to-gather-requirements-effectively-as-data-engineers
https://www.dataengineeringweekly.com/p/thinking-like-a-data-engineers
https://www.linkedin.com/posts/eczachly_sql-has-levels-to-it-level-1-select-activity-7339370246585110529-GAD4/
https://airflow.apache.org/
https://dagster.io/
https://seattledataguy.substack.com/p/5-things-in-data-engineering
https://www.linkedin.com/learning/data-quality-core-concepts
https://www.linkedin.com/learning/data-quality-analytics-and-serving
https://www.linkedin.com/learning/data-quality-transactions-ingestions-and-storage
https://pipeline2insights.substack.com/p/a-data-engineers-guide-to-vector-database
https://pipeline2insights.substack.com/p/a-data-engineers-guide-to-vector-database-part2
https://colab.research.google.com/drive/1JGwdyQl7oKG1nsEF9Ol32qnTt0hFURzd#scrollTo=eC87VYRnaPBf&forceEdit=true&sandboxMode=true
https://pipeline2insights.substack.com/p/how-to-succeed-in-data-engineering-interviews-with-yordan-ivanov
Great read thank you!
Great read. Totally agree that 2026 isn’t about choosing between fundamentals and AI, it’s about combining them. SQL, modelling, and quality still decide whether your pipelines are trustworthy, but AI is now the force multiplier.
The engineers who win are the ones who understand the business, think in systems, and use AI to accelerate, not replace, the craft.
Master the basics, then let AI extend your capabilities. That’s the real edge going forward.