
Week 26/31: Data Governance for Data Engineers
What Data Engineers need to know about data governance and where to apply it

As a data engineer, we might join a company where data governance is already in place: everything is well-documented, there’s a data catalogue, every data source has a clear owner, and metadata is easy to find. We can trace the full lineage of a dataset, from source to pipeline to dashboard/AI models, and quality checks are embedded throughout the process. Access to data is governed by clear roles and policies, with structured procedures for requesting access or making changes.
That’s the ideal scenario. But in reality, it’s rarely like this.
In most cases, especially in less mature data organisations, many of these governance practices might not exist at all. Documentation is limited, ownership is unclear, and metadata is incomplete or outdated. And while there may be formal data governance roles in theory, not every company has the resources or maturity to establish them in practice.
This is where we, as data engineers, step in.
Even if it’s not in our job title, data engineers are on the frontlines of how data is collected, transformed, and served, which means we share responsibility for ensuring it is reliable, secure, and trustworthy. Governance doesn’t just come from the top; it starts with us. Every data engineer should understand the core principles of data governance and actively apply them in their day-to-day work. That might mean flagging inconsistencies, advocating for documentation, suggesting improvements, or implementing practices that support transparency and accountability.
In Data engineering interviews, it’s valuable to show that we understand data governance, what it is, how our work aligns with it as a data engineer, and how we can help strengthen it within the organisation.
In this post, we cover
What is data governance?
4 Key Principles of Data Governance
7 Key concepts in data governance every Data Engineer should know
Interview questions
Missed the previous posts of this interview preparation series? Catch up here: [Data Engineering Interview Preparation Series]1.
What is Data Governance?
Data governance is a core data management function focused on ensuring the quality, integrity, security, and usability of an organisation’s data throughout its entire lifecycle, from the moment data is created or collected, to when it is archived or deleted. (As defined in Data Governance: The Definitive Guide: People, Processes, and Tools to Operationalise Data Trustworthiness2 by Evren Eryurek, Uri Gilad, Valliappa Lakshmanan,Anita Kibunguchy-Grant and Jessi Ashdown)
Effective data governance ensures that data is:
Accessible to the right people at the right time.
Usable in a way that supports business outcomes like analysis, insights, and decision-making.
Compliant with industry, government, and company-specific regulations.
This includes making sure that data:
Is accurate, up to date, and consistent across systems.
Can be trusted for reporting, analysis, and operational use.
can be accessed or modified by authorised users.
Changes and access are logged and traceable.
Ultimately, the goal of data governance is to build trust in data. Trustworthy data allows teams to make better decisions, assess risk, and track business performance using reliable metrics like KPIs.
Note: Data governance isn’t just for highly regulated industries like banking or healthcare; it matters for any organisation that wants to make confident, informed decisions with data. While setting it up can feel overwhelming, starting small and improving gradually is often the most sustainable path.
Keen to learn more about Data Governance, we suggest checking the resource below by
.Also, the
newsletter by is an excellent source for learning about data governance in greater detail and how to apply it in practice.4 Key Principles of Data Governance

Effective data governance is built on four core principles: Transparency and Discoverability, Accountability, Standardisation, and Security. While these principles are universal, how they're implemented can vary greatly depending on the size, maturity, and data culture of an organisation.
For data engineers, understanding these principles isn't just about compliance; it's about building trustworthy systems. We’re not only designing pipelines and storage systems; we’re shaping how data is accessed, protected, and understood. Whether we're choosing tools, defining schemas, or implementing access controls, our decisions directly impact how well data is governed.
1. Transparency and discoverability
Transparency in data governance means that everyone, inside and outside the organisation, should understand how data is governed and why. Clear, open communication about data policies builds trust, reduces confusion, and helps gain support from both technical and non-technical stakeholders.
For example, an organisation may enforce a policy that prevents sensitive data from being displayed on its website. Transparency means not only enforcing that rule, but clearly explaining its purpose (e.g., to protect user privacy) and how compliance is monitored.
Closely linked to transparency is data discoverability, the ability for users to easily find, understand, and access the data they need. This requires:
Access to technical metadata and data lineage.
A well-maintained business glossary.
Accurate, complete, and consistently structured datasets.
Together, transparency and discoverability ensure that data isn’t just well-governed, but also usable and trusted.
2. Accountability
Accountability in data governance means that everyone who interacts with data understands their responsibilities and is held to them. Clear, agreed-upon roles help ensure that data is handled correctly, consistently, and ethically.
For example, if an employee is required to report personal stock holdings by a certain date, failure to do so could have serious consequences, such as disciplinary action or even job loss. The same principle applies to data: accountability ensures that expectations are clear and that there are consequences for not meeting them.
When organisations treat data as a product, accountability becomes even more critical. Just like with any product, there must be defined owners who are responsible for the quality, reliability, usage, and lifecycle of the data.
3. Standardisation
Standardisation in data governance ensures that data is consistently labelled, described, and categorised across the organisation. This consistency is essential for improving data quality, enabling collaboration, and making data easier to use across systems and teams5.
For example, imagine an enterprise managing product inventory data across multiple systems: the ERP system records product categories as numerical codes (e.g.
1001,1002),the e-commerce platform uses descriptive labels like"Electronics"or"Apparel", and the analytics platform stores them under custom tags such as"ELEC"or"APP". Without standardisation, joining or analysing product data across these systems becomes error-prone and labour-intensive
By enforcing naming conventions, consistent data types, and aligned taxonomies, standardisation:
Improves searchability and discoverability.
Reduces duplication and confusion.
Makes data integration across tools and platforms more seamless.
Enhances communication between teams.
Ultimately, standardised data is more reliable, more usable, and more valuable because it behaves predictably and supports better decisions.
4. Security
Security in data governance means protecting data from breaches, misuse, and loss. It includes managing access controls, ensuring auditability, complying with regulations (like GDPR), and handling sensitive data such as PII responsibly.
In the Fundamentals of Data Engineering book6 by and Matt Housley, security is described as one of the key undercurrents of the data engineering lifecycle, a principle that must be considered at every stage, from ingestion to serving.
In this post7, we explored the foundational security principles every data engineer should understand, focusing on:
The Importance of Security in Data Engineering
The human factor in security
Foundational Principles and Best Practices for Securing Data
7 Key concepts in data governance every data engineer should know

Data Quality
Data quality is the health of data at any stage in its life cycle. Data quality can be impacted at any stage of the data pipeline, before ingestion, in production, or even during analysis.(Data Quality Fundamentals8 by Barr Moses, Lior Gavish, and Molly Vorwerck)
If poor data quality exists:
Best Case: A few wrong numbers lead to minor misunderstandings about the business.
Worst case: Incorrect data causes harm to people or regulatory violations.
If you want to learn more about what data quality is, including the key dimensions and real-world examples from our careers, check out this post:

If you're looking to understand the data quality framework and how to implement it in practice, we’ve covered that in detail in this post:

Metadata
Modern data systems help organisations access more types of data and share it with more people. However, without good management powered by metadata, these systems can quickly become messy and unreliable.
Think of metadata as a tracking system for packages. When we ship something internationally, we want to know where it is and if there are any delays. Shipping companies use tracking numbers and records to monitor each package’s journey and ensure it reaches the right place.
Metadata does the same for data. As information moves within and between companies, tracking changes and fixing problems becomes difficult without a clear record of what happened. Even a small change, like renaming a column in a source table, can affect hundreds of reports. Knowing this in advance helps prevent mistakes.
In short, metadata is the map of our data. It keeps things organised, prevents problems, and ensures the right people can find and use the right data when they need it.
Data Catalogue
A data catalogue is a centralised repository that stores metadata about an organisation’s data assets. It helps users discover, access, and understand datasets, tracking their structure, lineage, and usage.
Want to learn more about metadata and data catalogues?
This post covers:
The key categories of metadata: Business, Technical, Operational, and Reference
How to implement a data catalogue in your organisation

Data Lineage
Data lineage is the process of tracking the journey of data as it moves through an organisation’s systems. It shows where data originates, how it is transformed, and where it is ultimately used. This tracking enables transparency, supports regulatory compliance, and provides critical context for ensuring the accuracy and reliability of data products.
A lot of valuable insight comes not just from the final dataset, but from understanding how the data was manipulated along the way. Lineage helps teams answer questions like:
Was this dashboard built from high-quality or low-quality data?
Did any step of the transformation process introduce sensitive or restricted information?
Can we confidently trace this decision back to trusted inputs?
While some data warehouses and catalogues offer native lineage tracking, many organisations still have gaps, especially when using custom pipelines or diverse data stacks. That’s where data engineers come in.
Lineage can be tracked at multiple levels of granularity, depending on our governance goals:
Table-level lineage
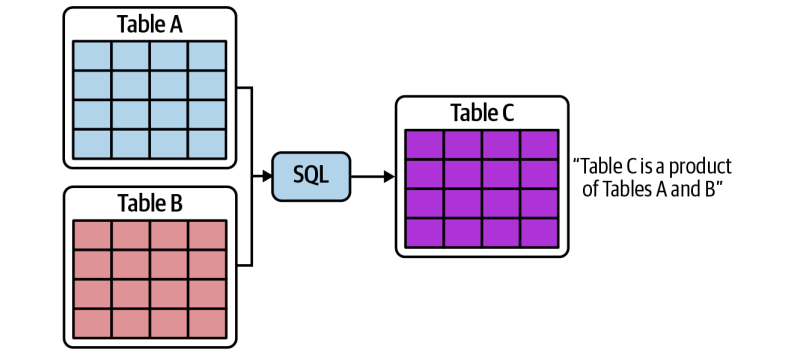
Captures which tables are inputs and outputs of a given process. This is a good starting point and works well for high-level data flow visualisation.
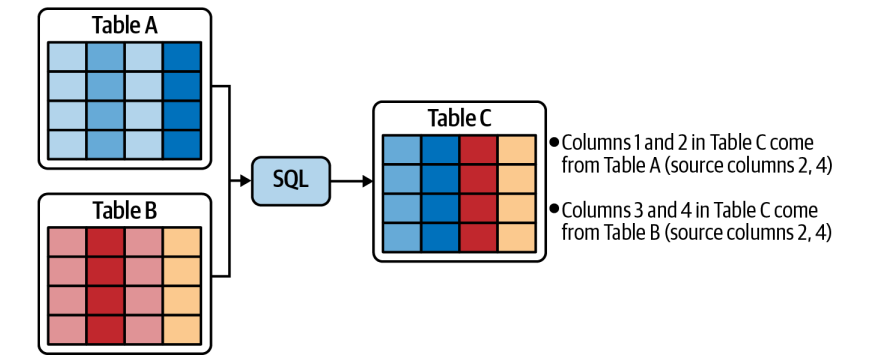
Column-level lineage
Tracks how individual columns are derived. For example, if columns from Tables A and B are joined to create Table C, and some of those columns are marked as PII, column-level lineage helps ensure PII tags propagate downstream. This level of detail supports data classification, compliance tracking, and sensitive data audits.
Row-level lineage
Provides traceability at the transaction level, useful for systems that track individual records and changes (e.g., CDC or audit logs).
Dataset-level lineage
A broader view, often used when tracing across external sources or data lakes, where fine-grained lineage isn’t practical or available.
Data engineers can automate lineage by:
Building metadata capture directly into ETL/ELT pipelines
Integrating with tools like dbt (which auto-generates lineage graphs from model dependencies)
Using orchestration frameworks (e.g., Airflow, Dagster) to map dependencies and execution order.
Interested in learning how to implement table, column, and row-level lineage using 9 and dbt10? Check out “Data Lineage Using dlt and dbt11” by Zaeem Athar on
.Data observability and monitoring
Data observability is the capability of a system that generate information on how the data influences its behaviour and, conversely, how the system affects the data. (As Andy Petrella defines in the Fundamental Data Observability book12)
In short, data observability lets teams trust their data the same way software observability lets them trust their apps.
However, you might ask: What is the difference between data quality and data observability?
Data quality is the goal: delivering data that’s clean, complete, fresh, and trustworthy.
Data observability provides the sensors, dashboards, and alerts that show when data quality slips and pinpoint where to fix it.
Keen to learn more about observability? In this post, What is Data Observability and How It Supports Data Quality13, we discussed:
Where data observability is applied.
Types of data observability.
Implementing observability in data projects.
Selecting the Right Observability Solution.
Establishing Effective Ownership.
Implementation Best Practices.
Data Modelling
Data modelling is important in data governance for several key reasons:
Bridges Business and Technical Teams
Data modellers act like translators; they take business needs and turn them into technical requirements. This ensures everyone has a shared understanding of the data, which is essential for governance.
Supports Clear and Accurate Data Definitions
Data models clearly define what data means, how it should be structured, and how it's used. This helps enforce consistency, standards, and rules, all core aspects of data governance.
Identifies Data Quality Issues Early
Through modelling, organisations can spot missing, inconsistent, or problematic data before it causes trouble. Good governance depends on high-quality, trustworthy data.
Documents, Data Relationships, and Uses
A data model (like an ER diagram) shows how data entities relate to each other. This documentation supports transparency, traceability, and accountability, which are key principles of data governance.
Ensures Compliance and Security
Models can include rules, constraints, and security requirements. This helps meet regulatory and compliance needs, which is a major goal of data governance.
Drives Standardisation
By using data models, organisations standardise how data is structured and described, reducing confusion and duplication, both essential for maintaining data integrity.
Enables Better Decision-Making
With accurate, well-modelled data, organisations can trust their data more, leading to better business decisions, which is one of the ultimate goals of data governance.
Data modelling lays the foundation for structured, secure, and meaningful data, making it a critical enabler of effective data governance. It turns business needs into clear data structures and ensures that data is understood, trusted, and well-managed across the organisation.
If you want to learn more about data modelling, we recommend checking
newsletter by which offers practical insights and best practices on the topic.Also, you can check out these data modelling interview preparation posts here:




Data Contracts
Data contracts are agreements that clearly say what data should look like and how it should be shared between teams or systems. They help make sure everyone understands the data's format, structure, and meaning, so there are no surprises when the data is used.
A well-defined data contract typically includes the following components:
Schema: Defines the structure and format of the data, such as fields, data types, and required columns.
Semantics: Captures the business meaning and context behind each field to avoid misunderstandings.
SLAs (Service Level Agreements): Set expectations for data availability, freshness, and performance.
Quality Rules: Outlines validation checks, monitoring requirements, and thresholds for acceptable data quality.
In this week’s 23/34: Data Contracts for Data Engineering Interviews, we covered:
Problems that data contracts solve
Where to apply data contracts throughout the data engineering lifecycle
How to get started with data contracts in your organisation
Tools and techniques for implementing data contracts
Interview questions
In interviews, data governance questions often begin with the basics, such as “What is data governance?” to assess our conceptual understanding. From there, they usually move into behavioural or practical territory, asking how we've applied key governance principles in real-world situations. This could involve sharing a specific experience where we implemented data quality checks, managed metadata, enforced access controls, or ensured compliance.
Q1: Can you describe a time when you detected and addressed a data quality issue?
Answer:
In my previous role as a data engineer at Company X, I was responsible for maintaining a critical data pipeline that provided key stakeholders with valuable insights. The pipeline processed data files that were regularly dropped into our S3 data lake. However, we frequently ran into issues where incoming data was incomplete or malformed. Unfortunately, our existing pipeline didn't catch these problems until the very end—after 6 hours of processing—when stakeholders reviewed the final output.
To solve this, I initiated a conversation with the stakeholders responsible for dumping the data and helped establish basic SLAs around data delivery expectations. Then, I implemented a data quality framework to introduce automated checks at multiple stages of the pipeline:
Pre-ingestion checks: As soon as the data was loaded into S3, I triggered validation scripts (using Python and SQL) to confirm completeness, schema consistency, and row counts.
In-pipeline checks: While processing, I added assertions to validate business rules and flag anomalies.
Post-load checks: After the data was loaded, I ran final integrity checks and generated alerts if thresholds were breached.
This approach allowed our team to catch issues early, notify the right teams before processing began, and dramatically reduce wasted compute and time. It also helped build trust in the data product by making quality checks a visible, repeatable part of our data pipeline governance.
Q2: Can you explain a situation when you applied data governance principles in a project?
Answer:
Sure. In a previous role, we were noticing inconsistencies in our financial reporting due to data coming from multiple sources with no standardised definitions. As part of a data governance initiative, I worked with data stewards and business analysts to define common data definitions for key metrics like “Revenue” and “Customer Status.”
I also added these definitions to our data catalogue and built a validation layer in our ETL pipeline using Python to enforce these definitions, ensuring only valid and complete records flowed into downstream dashboards. This improved trust in our reports and reduced the number of reporting errors flagged by stakeholders.
Conclusion
Data governance isn't just a policy; it's a daily practice, and data engineers are at the heart of it. While we may not always join companies with perfect governance in place, we can help build the foundations: clear ownership, better documentation, improved data quality, and secure access. Even without formal titles, our decisions in how we design pipelines, manage metadata, or flag inconsistencies shape how trustworthy and useful data becomes.
Understanding and applying the core principles of governance, like transparency, accountability, standardisation, and security, makes us stronger engineers and better collaborators. And in interviews, being able to talk about how we’ve put these principles into practice shows we’re not just technical, but thoughtful and responsible with data.
We Value Your Feedback
If you have any feedback, suggestions, or additional topics you’d like us to cover, please share them with us. We’d love to hear from you!

Enjoy Pipeline to Insights? Please share it with others! Refer
3 friends and get a 1-month free subscription.
10 friends and get 3 months free.
25 friends and enjoy a 6-month complimentary subscription.
Our way of saying thanks for helping grow the Pipeline to Insights community!
https://pipeline2insights.substack.com/t/interview-preperation
https://www.amazon.com.au/Data-Governance-Definitive-Operationalize-Trustworthiness/dp/1492063495
https://open.substack.com/pub/thedataecosystem/p/issue-47-role-of-data-governanc
https://thedataecosystem.substack.com/p/issue-47-role-of-data-governance
https://www.linkedin.com/learning/learning-data-governance-14224082/exploring-the-role-of-knowledge-graphs
https://www.amazon.com.au/Fundamentals-Data-Engineering-Robust-Systems/dp/1098108302
https://pipeline2insights.substack.com/p/review-done-final-check-undercurrent
https://www.amazon.com.au/dp/1098112040?ref_=mr_referred_us_au_au
https://dlthub.com/docs/intro
https://www.getdbt.com/product/what-is-dbt
https://dlthub.com/blog/dlt-data-lineage
https://www.oreilly.com/library/view/fundamentals-of-data/9781098133283/
https://pipeline2insights.substack.com/p/what-is-data-observability-and-how-it-supports-data-quality