

How to Choose Between Batch and Stream Processing?
When to Use Batch vs Stream Processing: Key Differences, Use Cases, and Tools for Data Engineers

When designing a data pipeline, we often face a series of architectural decisions that shape how data moves through the system. We ask ourselves:
How will we ingest the data? Is it via API, streaming events, or batch files?
Where will we store the data? Will it live in a data lake, a warehouse, or an operational database?
What are the downstream use cases? Are we building dashboards, feeding machine learning models, triggering alerts, or powering business reports?
Each of these decisions plays a role in defining the overall system. But in this post, we will focus on:
How should the data be processed?
Should we process data in large batches at scheduled intervals, in micro-batches that run every few minutes, or as soon as it arrives in near real time?
There are circumstances where both approaches succeed or fall short depending on how well they match the use case, the team’s maturity, and the operational environment.
In this post, we’ll explore:
What are batch processing and stream processing?
How do they differ?
How often does each approach appear in typical workflows?
Popular tools used in modern data teams.
Best practices for choosing the right method.
What Is Batch vs Stream Processing?
Understanding how and when data is processed is fundamental when designing a data pipeline. Processing strategies typically fall into two categories: batch processing and stream processing. Each has its strengths and use cases.
Batch Processing
Batch processing refers to the method of collecting data over a period of time, storing it, and then processing it all at once. This is typically done on a fixed schedule such as hourly, daily, or weekly.
For example, a daily ETL pipeline that reads from a data lake, performs joins and aggregations, and loads results into a warehouse for business reporting is a classic batch use case.

Key characteristics:
Processes large volumes of data at once
Operates on a schedule or trigger (not continuously)
Prioritises data completeness and consistency over speed
Easier to test and debug
Typical use cases:
Daily reporting dashboards
Historical data backfills
Data lake to warehouse transfers
If you want to learn more about Batch processing, check out this post as part of our Comprehensive Data Engineering Interview Preparation Guide1.

Stream Processing
Stream processing refers to handling data as it arrives, often within milliseconds to seconds. Instead of waiting for all data to be collected, the system continuously ingests and processes events in real time or near-real time.
For example, a fraud detection system that flags suspicious transactions the moment they happen is a clear case for stream processing. Another example is real-time user activity tracking for recommendation engines.
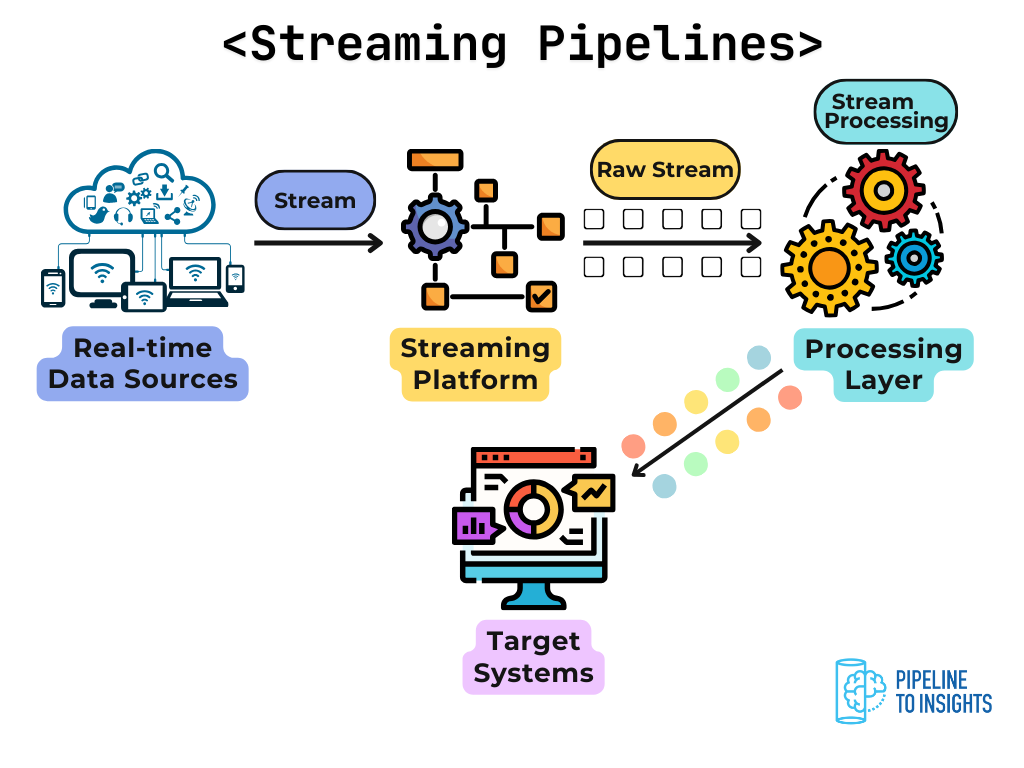
Key characteristics:
Processes data one record (or small windows) at a time.
Operates continuously with minimal delay.
Enables real-time insights and reactions.
Requires handling of out-of-order or late-arriving data.
Typical use cases:
Monitoring systems and real-time alerts
Event-driven microservices
Personalisation and user journey tracking
IoT sensor data analysis
Key Differences and Boundaries

If the use case can tolerate delay and favours complete, consistent results, batch processing is often the better starting point. If insights need to be timely or the system needs to respond immediately to events, stream processing may be a better fit.
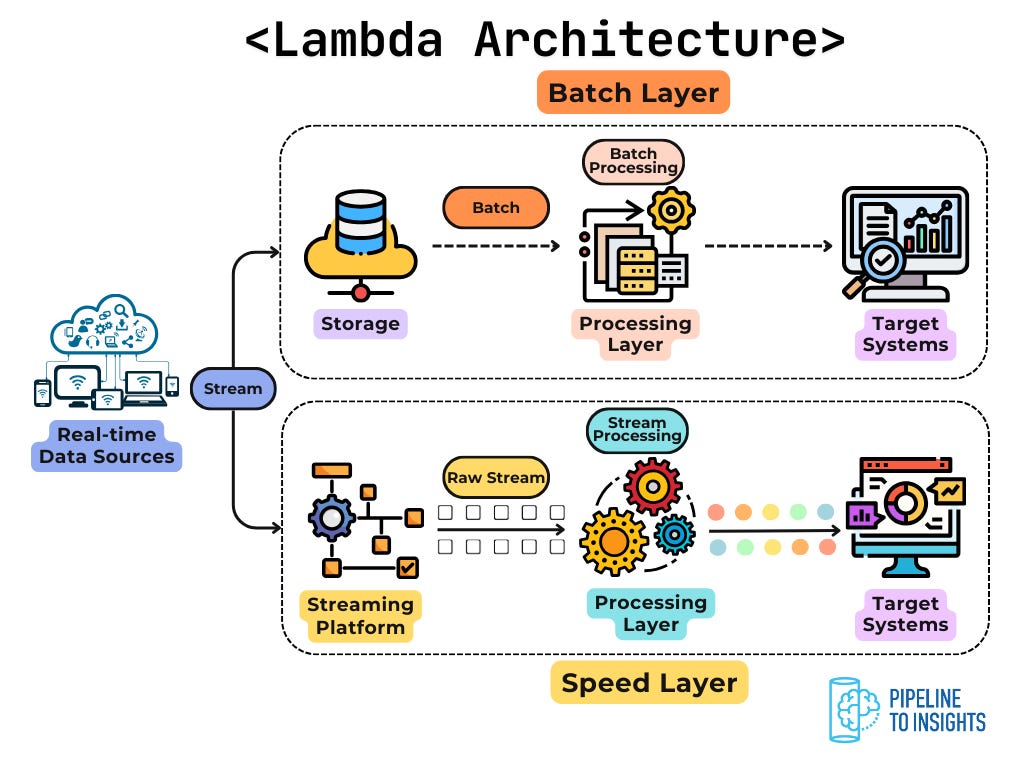
Also, some modern systems adopt a hybrid approach, such as the Lambda architecture, where stream processing handles real-time data while batch processing ensures long-term accuracy through periodic reprocessing. Although we don’t see such architecture in practice these days, it may still be useful to keep that in mind.
For more details on Pipeline Design Patterns, check out one of our popular posts below:

How Often Each Approach Appears in Typical Workflows
While both batch and stream processing have important roles in modern data systems, the reality is that most data pipelines in practice are batch-based.
This is especially true in small to mid-sized companies where data volume, urgency, and operational complexity are more manageable.
For example, common workflows like:
Ingesting data from common sources like databases, file systems, or APIs into a data warehouse,
Performing daily aggregations for dashboards,
Running scheduled ETL jobs for business reporting,
and so on
All can be effectively handled with batch processing. These pipelines are simpler to build, easier to test, and usually more cost-effective to run.
Even when low-latency is desirable, microbatch processing (e.g. running a job every 5 minutes) is often sufficient to meet business SLAs. Tools like Apache Spark’s Structured Streaming or Airflow with short schedules allow teams to process data quickly without adopting full stream processing complexity.
As a result, the percentage of pipelines that truly require real-time stream processing is relatively small, especially in smaller or non-digital-native companies. From what we’ve seen, it’s typically reserved for:
Financial institutions need fraud detection within seconds.
E-commerce platforms offering real-time product recommendations.
Ad tech or marketing platforms tracking clickstream data in near real-time
IoT platforms monitor and react to sensor data instantly
In these fields, the need for reactive systems, continuous analytics, and event-driven workflows makes stream processing more common.
However, for the majority of general-purpose analytics and data engineering use cases, batch or microbatch processing remains the default and often the most practical choice.
Popular Tools Used in Modern Data Teams
Note: Since this post focuses specifically on how data is processed, the tooling covered below is centered around processing engines, orchestration tools, and transformation layers. Ingestion, storage, and serving layers are important too, but are out of scope for this discussion.
Batch Processing Tools
Batch pipelines are usually built using a combination of orchestration, compute, and transformation tools. Here are some of the most widely used tools:
Processing & Compute Engines
SQL Engines in Warehouses (Snowflake, BigQuery, Redshift, Databricks SQL): Increasingly, batch transformations are implemented inside the warehouse using scheduled SQL workflows.
For more details about SQL, check out our SQL Optimisation series here: [link2]
dbt (Data Build Tool): Dominates the transformation layer for SQL-based pipelines. Often used with warehouses like Snowflake, BigQuery, or Redshift to define models, tests, and documentation.
For more details about dbt, check out our dbt in Actions series here: [link3]
Apache Spark: Still the backbone of many large-scale batch pipelines. Widely used for distributed processing, especially in data lake environments
For more details about Spark, check out the post below.

Pandas - Polars (Python libraries): Often used for small-scale or local batch processing, especially for prototyping or operational tasks.
For more details about Pandas and Polars, check out the post below.

Orchestration & Scheduling

Apache Airflow: One of the most common orchestration tools used to schedule and monitor batch jobs. Pipelines are defined as directed acyclic graphs (DAGs) in Python.
Dagster: An increasingly popular alternative that brings type safety and asset-driven design, making it easier to manage data dependencies and testing.
Prefect: Focuses on simplicity and observability, great for managing small to mid-scale batch jobs with Python-native interfaces.
For more details on Orchestration & Scheduling, check out weeks 16-18 of our Comprehensive Data Engineering Interview Preparation Guide: [link4]
Stream Processing Tools
Stream processing tools focus on handling data in motion, and typically involve a messaging layer (for transport), a processing engine, and a sink (where the results go).
Messaging & Event Transport
Apache Kafka: The industry standard for high-throughput, fault-tolerant event streaming. Used to publish and subscribe to event topics.
AWS Kinesis - GCP Pub/Sub - Azure Event Hubs: Cloud-native alternatives to Kafka, often used to decouple services and stream logs, metrics, or events.
Stream Processing Engines

Apache Flink: A robust, feature-rich engine designed for large-scale, stateful stream processing with strong support for event time and windowing.
Kafka Streams: A lightweight Java library that processes Kafka topics directly. Ideal for teams already working in the Kafka ecosystem.
Spark Structured Streaming: Allows developers to use familiar Spark APIs in a microbatch or continuous processing mode. Good for hybrid batch-streaming use cases.
Apache Storm: An older but still-used tool for real-time stream computation, especially in legacy systems.
Best Practices for Choosing the Right Method
Start simple. Optimise only when necessary. And always let the use case guide the architectural choices.
1. Start from the Business Requirement
Always ask:
How fast do we need the data?
What’s the acceptable latency?
What happens if data is delayed by 10 minutes? One hour?
This helps clarify if real-time is truly needed or just “nice to have.”
2. Consider The Team’s Maturity
Streaming requires deeper engineering capabilities, especially around monitoring and alerting. If the team is early in its journey, it’s usually better to start with batch and evolve.
For more details on Data Maturity, check out the post below:

3. Choose Hybrid Where Needed
In many mature systems, the combination may yield better performance:
Use streaming to provide recent insights.
Use batch to validate, backfill, or reprocess data.
For example, a model training pipeline might use streaming data to serve features quickly and batch data to retrain models nightly.
4. Don’t Optimise Prematurely
Real-time data can be tempting, but building it too early often leads to unnecessary complexity and cost. Unless there’s a strong driver, choose the simpler solution first.
Conclusion
Choosing between batch and stream processing is not about adopting the latest trend, but about aligning the processing strategy with business needs, system constraints, and team capabilities. While stream processing has its place in reactive, low-latency applications, the vast majority of pipelines can be effectively built using batch or microbatch processing.
By understanding the trade-offs, common tools, and practical patterns, we’ll be better equipped to design pipelines that are not only scalable but maintainable over time.
If you enjoyed this post, you might also be interested in the posts listed below.



https://pipeline2insights.substack.com/t/interview-preperation
https://pipeline2insights.substack.com/t/sql-optimisation
https://pipeline2insights.substack.com/t/dbt-series
https://pipeline2insights.substack.com/t/interview-preperation
Well structured and explained. Thanks